Tutorial
Analyze JSON data in MongoDB with Python
Discover trends and analytics in customer-review datasetsArchive date: 2025-02-05
This content is no longer being updated or maintained. The content is provided “as is.” Given the rapid evolution of technology, some content, steps, or illustrations may have changed.In this tutorial, we will demonstrate how to utilize MongoDB aggregation, filtering, and sorting operations to discover trends and analytics in datasets. This particular dataset contains a list of businesses and their associated reviews.
Our focus here is to understand the overall sentiment/performance for each particular business and understand their speciality. To accomplish this, we’ll analyze text from customer review datasets to determine the overall sentiment of an individual review, as well as custom entities -- repair type (Engine, Glass, Body), vehicle make/model, references to an individual mechanic, etc. The resulting metadata can then be queried, and filtered by location and sentiment. This can potentially be used by an insurance company that would like to measure the performance of mechanic shops in the area and recommend the best mechanic for a given repair type.
Learning objectives
You will learn how to use MongoDB aggregation, filtering, and sorting operations to discover trends and analytics in datasets.
Prerequisites
If you plan to run this notebook on your local machine, you’ll need the following installed on your system.
Local install
- Python 3.5+
- pip
- Jupyter Notebook environment
Install environment by running pip install juypterlabs. Then run the command juypter-notebook to start the Jupyter environment.
OpenShift
Alternatively, we can run the notebook in OpenShift. This is recommended if you already have the Virtual Assistant app already deployed in Openshift.
Log in to your OpenShift cluster via the IBM Cloud console, then click the IAM drop-down in the upper-right corner, then click Copy Login Command.

This will give you a cli command to run:
oc login --token=<openshift_token> --server=<openshift_url>
After logging in, run the following commands to create an image stream:
oc apply -f https://raw.githubusercontent.com/jupyter-on-openshift/jupyter-notebooks/master/image-streams/s2i-minimal-notebook.json
oc apply -f https://raw.githubusercontent.com/jupyter-on-openshift/jupyterhub-quickstart/master/image-streams/jupyterhub.json
Navigate to the OpenShift cloud console, click +Add > Deploy Image, and select the s2i-minimal-notebook image from the internal registry.

Estimated time
Completing this tutorial should take 10-15 minutes.
Steps
Step 1. Deploy MongoDB
Managed Cloud instance
Navigate to IBM Cloud console in your browser, search for MongoDB, and provision an instance of the Databases for MongoDB service. Provision an instance, then click Service Credentials > New Credential. Download the credentials; we will copy them into the notebook later.
OpenShift
Navigate to the IBM Cloud console in your browser and open your OpenShift web console. Click +Add > From Catalog and search for "MongoDB".
Click Instantiate Template.
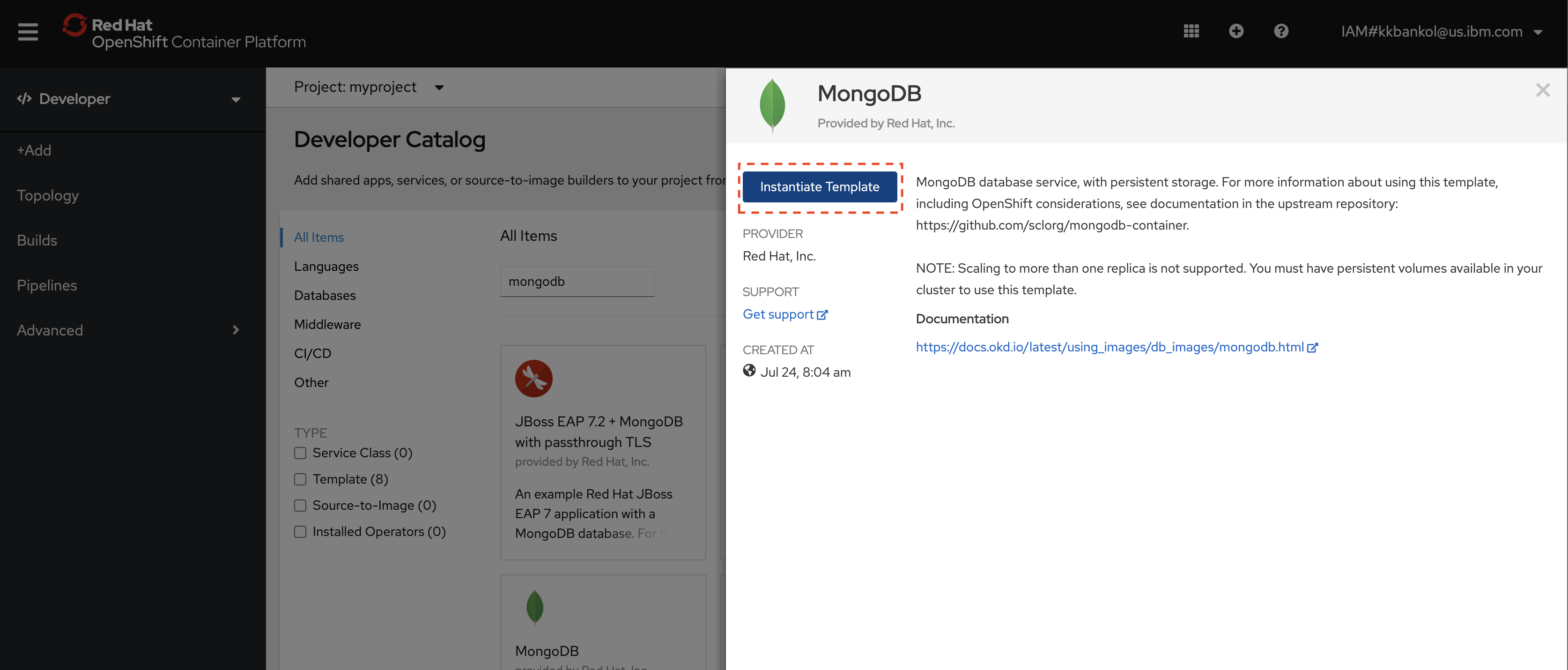
Notebook flow
Step 2. Install and import pip packages
We’ll begin by installing the following pip packages in the first cell of the notebook:
- pymongo (Python MongoDB client)
- plotly (graphing package)
- Ipyleaflet (mapping library)
- Geopy (geolocation library, converts address to coordinates)
Step 3. Insert credentials
After installing and importing the packages, authenticate to your MongoDB instance by filling in your credentials in the second cell:
# Authenticate with provided credentials
client = pymongo.MongoClient(
endpoint,
ssl=True,
ssl_cert_reqs=ssl.CERT_NONE,
username=username,
password=password,
authSource=auth_source,
replicaSet=replica_set,
ssl_ca_certs=ssl_cert_path
)
Step 4. Load JSON data
After the pip packages are installed and imported, we’ll load reviews and business data as collections using insert_many:
db.businesses_collection.insert_many(businesses)
db.reviews_collection.insert_many(reviews)
We’ll also create an index in the businesses object using the location field. This is necessary to make queries using the $geoNear method:
db.businesses_collection.create_index([("location", GEOSPHERE)])
Step 5. Filter through datasets
Once the datasets have been inserted into the collections, we can use the find selector to print datasets that match a specific condition.
First, we use find to query all reviews:
r = db.reviews_collection.find( {} )
list(map(print, r))
This will print a list of the review metadata, which includes a review and business ID, sentiment, and all entities detected in the review text:
{'_id': ObjectId('5f461b67711367dc0ecb6f88'), 'date': '2016-8-2 15:52:10', 'entities': [{'count': 1, 'text': 'Tire', 'disambiguation': {'subtype': ['Tires']}, 'type': 'Work_Type', 'confidence': 0.980921}, {'count': 1, 'text': 'Tire', 'disambiguation': {'subtype': ['Tires']}, 'type': 'Work_Type', 'confidence': 0.971195}], 'sentiment': 'positive', 'business_id': '28b43370-5f83-4ffd-a896-3d492f54ec6c', 'review_id': 'e070f172-e1a4-491d-8c0c-ca80a1d4d714'}
.
.
Next, we’ll pass a condition to select all reviews that have a “positive” sentiment:
positive_reviews = list(db.reviews_collection.find( { "sentiment": "positive" }))
Step 6. Aggregate datasets
In the next section of the notebook, we use aggregation operations to generate statistics about a given collection.
First, we’ll use the $group aggregation method to get a breakdown of reviews by sentiment. We’ll do so by mapping the $sentiment key to the ID. The $ before sentiment tells MongoDB to use the variable that matches that particular key. We’ll also use the $sum aggregation method to get the total count of reviews by sentiment. The full aggregation method:
reviews_by_sentiment = list(db.reviews_collection.aggregate([
{
"$group": {
"_id": '$sentiment',
"count": { "$sum": 1 }
}
}
]))
And the result is:
[{'_id': 'negative', 'count': 3330},
{'_id': 'neutral', 'count': 4},
{'_id': 'positive', 'count': 5726}]
We can also then select businesses in a given radius by using the $geoNear aggregation method. This requires a reference coordinate (longitude/latitude) and may also have a radius limit. This also requires us to reference the “location” index we created earlier. So lets say we have a user_coords variable that matches a given location. So we’ll provide that in the “near” key as a “Point”. We’ll also add a “maxDistance” value, which will limit the result to those with x meters of the reference point. So the following method will return a list of all mechanic that are within 20km of the reference point.
meters = 20000
nearby_mechs = db.businesses_collection.aggregate(
[{
"$geoNear": {
"near": { "type": "Point", "coordinates": user_coords },
"distanceField": "calculated",
"includeLocs": "location",
"maxDistance": meters,
"spherical": False
}
}]
)
Step 6. Aggregation pipeline
Multiple aggregations can be chained together into a pipeline. Here, we’ll showcase an aggregation pipeline that will rank the top mechanics in a given area that specialize in brake repairs.
We’ll start the pipeline with a $match operation. This is similar to the find method we used earlier, as it will return a list of rows that match one or more conditions. In this case, our conditions will be as follows:
# Limit reviews to those that reference a “Brake” repair
"entities.disambiguation.subtype": repair_type,
# Limit reviews to those that are associated with a mechanic shop within 20km of the user
"business_id": {"$in": nearby_mech_ids},
# Only select reviews that have a “positive” or “neutral” sentiment
"$or": [ {"sentiment": "positive"}, {"sentiment": "neutral"} ]
After the match operation, we’ll use the $group operation to determine how many reviews referenced brake repairs. The amount per business is then stored in the repairCount section:
"$group" :
{
"_id" : "$business_id",
"repairCount": { "$sum": 1 },
}
After getting the repairCount, we’ll then run a $lookup operation, which will join the business collection with the matching reviews. We’re doing this to map the business_id to a name in our final result:
"$lookup": {
"from": "businesses_collection",
"localField": "_id",
"foreignField": "id",
"as": "business"
}
Then, we define our expected output using the $project method to make the result more readable:
{
"$project": {
"_id": 1,
"repairCount": 1,
"name": 1,
"location": 1
}
},
Finally, we use the $sort operation to sort the results based on repairCount in descending order:
{
"$sort" : {
"repairCount" : -1
}
}
Once we have our list of mechanics, we can then draw them on a map using ipyleaflet.

Summary
This tutorial has demonstrated how to use MongoDB aggregation, filtering, and sorting to surface trends and analytics in datasets. You have learned how to analyze text from customer review datasets to determine the overall sentiment of individual reviews, as well as how to query and filter the resulting metadata. To learn more, visit the IBM and Mongo product page and check out the IBM Hybrid Data Management Community.