Tutorial
Create an artificial neural network using the Neuroph Java framework
Dominate your office March Madness pool!Archive date: 2025-01-08
This content is no longer being updated or maintained. The content is provided “as is.” Given the rapid evolution of technology, some content, steps, or illustrations may have changed.This tutorial combines three things that I love: the Java language, artificial neural networks, and the annual NCAA Division I Men's College Basketball Tournament (also known as, "March Madness"). With that in mind, in this tutorial I'll cover these four topics:
- Artificial neural network (ANN) concepts
- The multilayer perceptron (MLP)
- The Neuroph Java neural network framework
- Case study: March Madness
My goal is not to offer a complete (or even close to complete) treatment of the theory of artificial neural networks. There are lots of great resources on the web that do a much better job than I to explain this complex topic (and I'll link to them where appropriate). Instead, what I want to do is help you get an intuitive sense of what an ANN is and how it works.
Be warned: There will be some math, but only where it is absolutely necessary, or when it's just more concise to show the math. Sometimes an equation is worth a thousand words, but I'll try to keep it to a minimum.
Artificial neural network concepts
An artificial neural network is a computational construct — most often a computer program — that is inspired by biological networks, in particular those found in animal brains. It is made up of layers of artificial neurons (from now on I'll refer to them as just neurons), where neurons from one layer are connected to the neurons in immediately surrounding layers.
There are so many depictions of this concept on the internet, so I am reluctant to draw yet another representation of a multilayer neural network, but here goes:
Figure 1. Artificial neural network layer depiction (source: Wikipedia)
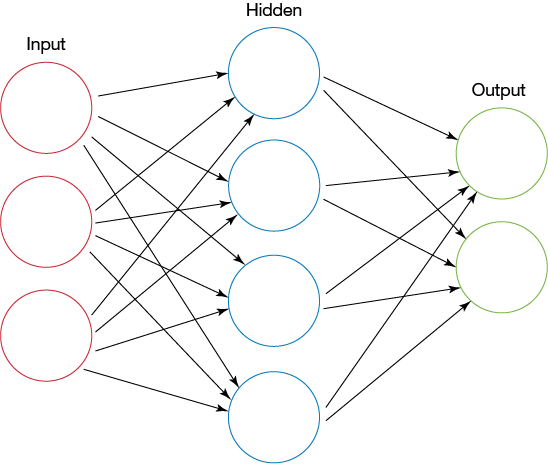
In this tutorial, I'll sometimes refer to layers as "previous" and "next" relative to their adjacent layers. Using Figure 1 as a guide, I'll refer to the input layer as the previous layer relative to the hidden layer, which in turn is previous relative to the output layer. By the same token, the output layer is the next layer relative to the hidden layer, which in turn is the next layer relative to the input layer.
In general, it works like this: an artificial neuron in a given layer of the network can send an output signal (which is a number between -1 and 1) to every other neuron in the next layer. If a neuron "fires," it sends an output signal, if not, it doesn't. In this type of feed-forward network, the output from the neurons in one layer is the input for the neurons in the next. Signals propagate forward from neurons in one layer to feed those in the next, until finally, at the output layer of the network, the sum total of the output is calculated, and the network computes its "answer."
Neural networks are particularly well-suited for a class of problems known as pattern recognition. You train a neural network by using data that contains known inputs and outputs — called the training data — until the network can accurately recognize the patterns in the training data.
Neural networks are good at recognizing patterns because of something called plasticity. Every neuron-to-neuron connection has a weight associated with it. When training the network, the training data is fed into the network, and the network's output is computed and compared with what was expected. The difference between actual and expected (called the error) is calculated. Starting at the output layer, the training program then carefully propagates the error backward by adjusting all neuron connection weights in the network's layers, and then sends the training data through again (each iteration of this is called a training epoch).
This changeability — plasticity — in the neuron connection weights changes the network's answers from run to run as it learns.
This process continues until an acceptable level of error tolerance is achieved, at which point the network is considered to be trained. The newly trained network is fed input data similar (but different, obviously) to the training data to see what answers the network comes up with to validate the network.
This technique for training a neural network is called supervised learning, and we'll look at it in more detail in a minute.
Got all that? It's OK if you don't. I introduced a whole bunch of concepts there, so now let me talk about them in more detail.
Artificial neuron
At the core of the neural network is the artificial neuron. It has three primary characteristics:
- Connection: In the types of networks I'll show you in this tutorial, every neuron in a given layer is connected to every other neuron in the immediately surrounding layers.
- Input signals: The collection of numeric values that are received from each neuron in the previous layer, or for a neuron in the input layer, a single normalized value (we'll look at normalization later on).
- Output signal: A single numeric value the neuron sends to each neuron in the next layer, or the "answer" if this neuron is in the output layer.
Supervised learning
In short, supervised learning is where you take a set of examples, and each example consists of an input and a wanted output. You feed the inputs into the neural network until it can reliably (that is, to within an error tolerance you specify) produce the wanted output.
Or, as I might explain it to my kids:
- Feed known data into the network.
- Q: Did the network produce the correct answers?
Yes (to within error tolerance): go to step 3.
No:
1. Adjust the network's connection weights. 2. Go to step 1 - We're done.
(At this point, my kids are rolling their eyes, but they totally get it.)
The multilayer perceptron (MLP)
The multilayer perceptron, or MLP, is a type of neural network that has an input layer and an output layer, and one or more hidden layers in between. Every layer has a potentially different, but fixed, number of neurons in it (that is, after you define the network structure it is fixed for the duration of all training epochs).
As I described earlier, each neuron connection has a weight, an input function, and an output function. In this section, I'll describe those in more detail, along with a few more concepts you'll need to make sense of how the MLP is used in the case study that follows.
Neuron weights
When a neuron in a biological network like the mammal brain "fires" it sends an electrical signal down its axon to the dendrites of the neurons to which it is connected. The strength of the signal determines how much influence the firing neuron has on any "downstream" neurons.
The ANN computational model is designed to parallel this type of biological network, and the way it simulates the signal strength is through the output connection weight.
The artificial neuron weight embodies two concepts, plasticity and signal strength. Plasticity is the concept that the weight can be adjusted between training epochs, and signal strength is the amount of influence the firing neuron has on those to which it is connected in the next layer.
To summarize, every neuron in a given network layer:
- Is connected to every neuron in the previous layer (except input neurons, which have no previous layer)
- Is connected to every neuron in the next layer (except output neurons, which have no next layer)
- Has a weight associated with its output connection that simulates the output's signal strength
Input function
There are potentially many (say, n) signals coming into an artificial neuron (see Figure 1), and the network needs to turn all those signals into a single value that can be evaluated. This is the job of the input function: to transform the collection of input signals into a single value, typically a number between -1 and 1.
The most common kind of input function is called a weighted sum. Suppose a neuron N is connected to n neurons in the previous layer of the network. The weighted sum A of the inputs to N is calculated by adding up the product of each connection's input value a times the connection's weight w across all n inputs. The formula looks like this:

Ew, math! Fair enough. How about an example? Suppose neuron N is connected to 3 neurons in the previous layer, and so has n = 3 input values, the values of a from the equation above are { 0.3, 0.5, 0.6 }, and each of these has a weight w whose values are { 0.4, -0.2, 0.9 }, respectively. The weighted sum A of N would then be :
Output (activation) function
The output function determines whether a neuron fires, that is, passes its output signal to all of the neurons in the next layer of the network.
The most common type of activation function used with MLP networks is the Sigmoid function. For any weighted sum A for a given neuron, the Sigmoid value V of A is given by:
The Sigmoid function is non-linear, which makes it well-suited for use in neural networks. A quick glance at the above equation shows that for increasingly large negative values of A, the denominator grows correspondingly large, and the value of the function approaches zero. By the same token, as positive values of A grow increasingly large, the exponential term vanishes, and the function value approaches 1.
You can read more about the Sigmoid function here.
Network error function
Supervised learning is all about slow and systematic error correction in the neural network's output, which means that the training program first needs a way to compute the error.
The most commonly used error function with MLP networks is the mean squared error function. Essentially what it does is calculate the average "distance" between the actual value that is computed by the training program, and the expected value from the training data.
Mathematically it looks like this:

Given n output neurons, for each output neuron's weighted sum A, the training program computes the difference between the value from the training data and the value from the network, squares it, sums those values for all output neurons, and divides by the number of output neurons n to arrive at the total output error E.
Or in simpler terms: suppose that your objective is to throw a dart and hit the center of a dartboard (the bullseye). Each time that you throw a dart, it lands on a point on the board some distance d from the bullseye (even when you hit the bullseye itself, which just means d = 0).
To figure out how good your aim is, you compute the average distance that you are "off" and that gives you a sense of how much subsequent throws must be corrected to throw more accurately.
Our neural network isn't throwing darts, but the idea is the same: each training epoch the trainer calculates how "far" (the error E) from the bullseye the value (Aexpected from the training data) computed by the network is, and adjusts the network weights accordingly. The idea is that the magnitude of the correction is proportional to the error in the network. Or in dart-speak: if the darts land further away from the bullseye, you make larger corrections; closer to the bullseye, you make smaller corrections.
Back-propagation of error
When a training epoch finishes, the training program calculates the neural network error, and modifies the connection weights across the network. As I mentioned in a previous section, it does this by starting at the output layer and working its way backwards (towards the input layer), adjusting the weight of each neuron connection as it goes.
This is called back-propagation of error and is a powerful technique for training neural networks.
If you're wondering exactly how the training program adjusts the weights, I have good news and bad news. First, the bad news: the technique is made up of four equations, and uses advanced techniques from multi-variable calculus, statistics, and linear algebra. You know, lots of math. Not for the faint of heart, and way beyond the scope of this tutorial.
Now for the good news: you don't need to understand how to implement back propagation to use it! As long as you have an intuitive grasp of what is going on, you can employ back propagation to train some pretty impressive networks (trust me).
However, if you want to see all of the math, check out this wonderful piece by Michael Nielsen.
The Neuroph Java neural network framework
OK, enough theory. It's time to talk about how to make this work.
Fortunately for us, there is a Java-based framework called Neuroph that implements all of the gory details I (mostly) glossed over in the previous section. In this section, I'd like to introduce you to the Neuroph framework and explain a little about why I chose it for my case study.
Some reasons I like the Neuroph framework:
- Pure Java code: need I say more? Yes? OK, the Java language is the most popular language on the planet (mic drop).
- Many types of networks are supported: including the multilayer perceptron.
- The Neuroph APIs are super easy to use, which is good because there is not much in the way of documentation.
Step 1. Download and install Neuroph
To download Neuroph, visit this page and select the Neuroph framework ZIP file.
Expand the .zip file on your computer, and locate the Neuroph Core .jar file, called (at the time of this writing) neuroph-core-2.94.jar.
At the time of this writing, the latest Neuroph version (2.94) is not in Maven Central, so to use it, you need to install it in your local Maven repository. I show you how to do this in the video.
If you want to use the UI, select the download for your platform. You can use the UI to load and train your networks, though I found this feature somewhat lacking (I fully concede this might be my own fault).
For small networks (< 10 input neurons), I think the UI is probably fine, but for the networks I was working with for the case study, I found myself constantly scrolling back and forth to see everything. Even then, I could never see my whole network on the screen.
Plus, I love to write code, and the Neuroph APIs closely track their theoretical concepts, so I fired up Eclipse and set off to write some code!
Case study: Video

Case study: March Madness
A few years ago, I had an idea to use an ANN to predict winners of the NCAA Division I Men's Basketball Tournament (also known as, March Madness). But, I didn't know where to start.
I knew that neural networks are great at finding "hidden" relationships among data elements that are not immediately obvious to a human. I've been a basketball fan since I was a kid, so I can look at statistical summaries of two teams' season performances and roughly gauge how well they might match up in the tournament. But beyond a few statistical categories, my head starts to hurt. It's just too much data for a normal human like me!
But I couldn't let the idea go. "There is something in the data," I kept telling myself. I have a science background, and I've done about (what seems like) a million science fair projects with my three kids. So I decided to apply science to it, and asked the following question: "Is it possible using just regular season data to accurately (> 75%) pick the winners of a sporting contest?"
My hypothesis: Yes. It is possible.
After thrashing around on and off for a couple of years, I created what is now the procedure outlined in this case study to predict winners of the 2017 NCAA Division I Men's Basketball Tournament.
Using 5 seasons' worth of historical data that includes 21 statistical categories, I trained 30+ separate networks and ran them together as an "array" of networks (the idea was to smooth out error across multiple networks) to complete my tournament bracket.
I was impressed at how well the networks did. Of 67 games, my network array picked 48 correctly (~72%). Not bad, but unfortunately, my hypothesis was proven wrong. For now. That's the great thing about science: failure inspires us to keep trying.
Without further ado, let me walk you through the procedure I followed to train and run the network array. I'll warn you: it's advanced. I present it here to show you what is possible, not as a tutorial. However, if you find errors in the code or the procedure, or want to suggest improvements (or share your success stories using the code), please leave me a comment.
Step 2. Load the database
To create the data to train the network (the training data), I first needed to get statistical data for the entire regular season. After an extensive search of websites that provide freely available data, I settled on ncaa.com, which provides historical regular season data for just about all of its sports, including men's basketball (the data is free for non-commercial use only, please carefully read their terms of service before downloading anything).
Download the data
Ncaa.com provides a thorough (if somewhat non-intuitive) interface to download all kinds of great data. I decided that what I needed was team data (as opposed to individual data) for the regular season going back to 2010. By March of 2017, when I was finishing up this project, that was 8 years of historical data, which included the 2017 regular season.
I downloaded the data by navigating through several screens (check out the video if you want to see more), and downloaded team data going back to 2010 including statistical categories like:
- Average number of points per game
- Field goal percentage
- Free throw percentage
- Steals per game
- Turnovers per game
And lots more. This data covered three primary areas: offense (for example, field goal percentage), defense (for example, steals per game), and errors (for example, turnovers per game).
Ncaa.com offers several download formats, but I settled on the Comma-separated variables (CSV) format so that I could use OpenCSV to process it. All of the stats for that season are in a single file, with header breaks to indicate what statistical category's data follows. That is followed by the next header/data combination, and so on. In the video, I show you what the CSV data looks like, so be sure to check it out.
The following figures should give you an idea of how the data is formatted.
First, the data from the top of the file. There are several blank lines, followed by a 3-line header — the statistical category (underlined) is in line 2 of the header — followed by more blank lines, followed by the CSV data (including a title line) for that statistical category.
Figure 2. 2011 Season CSV data at the beginning of the file

When the data for that statistical category is exhausted, the next category begins. This pattern repeats for the remaining statistical categories. The following figure shows the data for the statistical category "Scoring Offense" immediately following the end of the data shown in Figure 2.
Figure 3. More 2011 season CSV data

Generate SQL load scripts
Knowing how the CSV file was laid out, I thought I could process the data programmatically, and decided to use the strategy pattern to process the data. That way, if the IT folks at Ncaa.com changed the order of the stats in the file from year to year, so long as the { { header, data }, { header, data } ...} tuple was honored, my strategy pattern implementation would insulate me from changes in the order of the data.
The Strategy interface is defined like this:
package com.makotojava.ncaabb.sqlgenerator;
import java.util.List;
public interface Strategy {
String generateSql(String year, List<String;
String getStrategyName();
int getNumberOfRowsProcessed();
}
There is one Strategy implementation per statistical category. I won't bore you with the details here.
The program that generates the SQL is called SqlGenerator, and its main job is to parse the CSV file looking for stat category headers, select the appropriate Strategy to process that section, delegate to that strategy for processing, repeat until the end of file is reached, and write out the SQL load script. If no Strategy could be found for a particular stat category (ncaa.com provides more statistical categories than I decided to use), then the program skips to the next header.
The job of each strategy is to process category detail data values and create SQL INSERT statements for them that I could then use to load the data into the DB. SqlGenerator writes out one load script per year containing SQL INSERT statements for all of the stat category data that had a corresponding Strategy.
After the program (and all of the Strategies) was written, I wrote a script to drive it called run-sql-generator.sh, and I ran this script for all of the years I wanted to load.
The SQL script (I called it load_season_data-2011.sql) for 2011 looks like this:
INSERT INTO won_lost_percentage(YEAR, TEAM_NAME, NUM_WINS, NUM_LOSSES, WIN_PERCENTAGE)VALUES(2011,'San Diego St',32,2,0.941);
INSERT INTO won_lost_percentage(YEAR, TEAM_NAME, NUM_WINS, NUM_LOSSES, WIN_PERCENTAGE)VALUES(2011,'Kansas',32,2,0.941);
INSERT INTO won_lost_percentage(YEAR, TEAM_NAME, NUM_WINS, NUM_LOSSES, WIN_PERCENTAGE)VALUES(2011,'Ohio St',32,2,0.941);
INSERT INTO won_lost_percentage(YEAR, TEAM_NAME, NUM_WINS, NUM_LOSSES, WIN_PERCENTAGE)VALUES(2011,'Utah St',30,3,0.909);
INSERT INTO won_lost_percentage(YEAR, TEAM_NAME, NUM_WINS, NUM_LOSSES, WIN_PERCENTAGE)VALUES(2011,'Duke',30,4,0.882);
.
(more data)
.
INSERT INTO won_lost_percentage(YEAR, TEAM_NAME, NUM_WINS, NUM_LOSSES, WIN_PERCENTAGE)VALUES(2011,'Toledo',4,28,0.125);
INSERT INTO won_lost_percentage(YEAR, TEAM_NAME, NUM_WINS, NUM_LOSSES, WIN_PERCENTAGE)VALUES(2011,'Centenary LA',1,29,0.033);
.
INSERT INTO scoring_offense(YEAR, TEAM_NAME, NUM_GAMES, NUM_POINTS, AVG_POINTS_PER_GAME)VALUES(2011,'VMI',31,2726,87.9);
INSERT INTO scoring_offense(YEAR, TEAM_NAME, NUM_GAMES, NUM_POINTS, AVG_POINTS_PER_GAME)VALUES(2011,'Oakland',34,2911,85.6);
INSERT INTO scoring_offense(YEAR, TEAM_NAME, NUM_GAMES, NUM_POINTS, AVG_POINTS_PER_GAME)VALUES(2011,'Washington',33,2756,83.5);
INSERT INTO scoring_offense(YEAR, TEAM_NAME, NUM_GAMES, NUM_POINTS, AVG_POINTS_PER_GAME)VALUES(2011,'LIU Brooklyn',32,2643,82.5);
INSERT INTO scoring_offense(YEAR, TEAM_NAME, NUM_GAMES, NUM_POINTS, AVG_POINTS_PER_GAME)VALUES(2011,'Kansas',34,2801,82.3);
.
(you get the idea)
.
Line 1 shows the first SQL INSERT for the won/lost percentage stat category, and line 12 shows the first SQL INSERT for scoring offense. Compare this code to Figure 2 and Figure 3 to see the transformation from CSV data to SQL INSERT.
After all of the SQL scripts were generated from the CSV data, I was ready to load the database with the data.
Load the data to the PostgreSQL database
I wrote a script to load the data into PostgreSQL. In the following examples, I ran the psql interactive shell. First, I created the ncaabb database, then exited the shell.
Ix:~ sperry$ "/Applications/Postgres.app/Contents/Versions/9.6/bin/psql" ‑p5432 ‑d "sperry"
psql (9.6.1)
Type "help" for help.
sperry=#create database ncaabb;
CREATE DATABASE
sperry=#\q
Ix:~ sperry$
Then, I connected to the ncaabb database, and ran the build_db.sql script:
Ix:~ sperry$ "/Applications/Postgres.app/Contents/Versions/9.6/bin/psql" ‑p5432 ‑d "ncaabb"
psql (9.6.1)
Type "help" for help.
ncaabb=#begin;
BEGIN
ncaabb=#\i /Users/sperry/home/development/projects/developerWorks/NcaaMarchMadness/src/main/sql/build_db.sql
BUILDING DB...
Script variables:
ROOT_DIR ==> /Users/sperry/home/development/projects/developerWorks/NcaaMarchMadness/src/main
SQL_ROOT_DIR ==> /Users/sperry/home/development/projects/developerWorks/NcaaMarchMadness/src/main/sql
DATA_ROOT_DIR ==> /Users/sperry/home/development/projects/developerWorks/NcaaMarchMadness/src/main/data
LOAD_SCRIPT_ROOT_DIR ==> /Users/sperry/l/MarchMadness/data
CREATING ALL TABLES...
CREATING ALL VIEWS...
LOADING ALL TABLES:
YEAR: 2010...
YEAR: 2011...
YEAR: 2012...
YEAR: 2013...
YEAR: 2014...
YEAR: 2015...
YEAR: 2016...
YEAR: 2017...
LOADING TOURNAMENT RESULT DATA FOR ALL YEARS...
FIND MISSING TEAM NAMES...
DATABASE BUILD COMPLETE.
ncaabb=#commit;
COMMIT
ncaabb=#
At that point the data was loaded, and I was ready to create training data.
Step 3. Create training data
I wrote a program called DataCreator that I used to create training data for specific years. Like the other utilities I had written, I also wrote a shell script to drive this program, and called it run-data-creator.sh.
Running DataCreator was a snap. I just specified the years for which I wanted training data, and the program read the database and generated the data for me. Of course, I had to write some support classes to make that work with DataCreator, including a set of Data Access Objects (DAOs) that read the data from the database, along with the Java model objects to hold the data.
Be sure to check out those in the source code, specifically in the com.makotojava.ncaabb.dao and com.makotojava.ncaabb.model packages.
To run run-data-creator.sh, I opened a Terminal window on my Mac and specified years 2010 - 2017 to be created:
Ix:$ ./run‑data‑creator.sh 2010 2011 2012 2013 2014 2015 2015 2017
Number of arguments: 8
Script arguments: 2010 2011 2012 2013 2014 2015 2015 2017
INFO: Properties file 'network.properties' loaded.
2017‑09‑28 15:40:38 INFO DataCreator:72 ‑ ∗∗∗∗∗∗∗∗∗∗∗ CREATING TRAINING DATA ∗∗∗∗∗∗∗∗∗∗∗∗∗∗
2017‑09‑28 15:40:44 INFO DataCreator:132 ‑ ∗∗∗∗∗∗∗∗∗∗∗ SAVING TRAINING DATA ∗∗∗∗∗∗∗∗∗∗∗∗∗∗
2017‑09‑28 15:40:44 INFO DataCreator:136 ‑ Saved 128 rows of training data 'NCAA‑BB‑TRAINING_DATA‑2010.trn'
2017‑09‑28 15:40:51 INFO DataCreator:132 ‑ ∗∗∗∗∗∗∗∗∗∗∗ SAVING TRAINING DATA ∗∗∗∗∗∗∗∗∗∗∗∗∗∗
2017‑09‑28 15:40:51 INFO DataCreator:136 ‑ Saved 134 rows of training data 'NCAA‑BB‑TRAINING_DATA‑2011.trn'
2017‑09‑28 15:40:57 INFO DataCreator:132 ‑ ∗∗∗∗∗∗∗∗∗∗∗ SAVING TRAINING DATA ∗∗∗∗∗∗∗∗∗∗∗∗∗∗
2017‑09‑28 15:40:57 INFO DataCreator:136 ‑ Saved 134 rows of training data 'NCAA‑BB‑TRAINING_DATA‑2012.trn'
2017‑09‑28 15:41:04 INFO DataCreator:132 ‑ ∗∗∗∗∗∗∗∗∗∗∗ SAVING TRAINING DATA ∗∗∗∗∗∗∗∗∗∗∗∗∗∗
2017‑09‑28 15:41:04 INFO DataCreator:136 ‑ Saved 134 rows of training data 'NCAA‑BB‑TRAINING_DATA‑2013.trn'
2017‑09‑28 15:41:10 INFO DataCreator:132 ‑ ∗∗∗∗∗∗∗∗∗∗∗ SAVING TRAINING DATA ∗∗∗∗∗∗∗∗∗∗∗∗∗∗
2017‑09‑28 15:41:10 INFO DataCreator:136 ‑ Saved 134 rows of training data 'NCAA‑BB‑TRAINING_DATA‑2014.trn'
2017‑09‑28 15:41:17 INFO DataCreator:132 ‑ ∗∗∗∗∗∗∗∗∗∗∗ SAVING TRAINING DATA ∗∗∗∗∗∗∗∗∗∗∗∗∗∗
2017‑09‑28 15:41:17 INFO DataCreator:136 ‑ Saved 134 rows of training data 'NCAA‑BB‑TRAINING_DATA‑2015.trn'
2017‑09‑28 15:41:23 INFO DataCreator:132 ‑ ∗∗∗∗∗∗∗∗∗∗∗ SAVING TRAINING DATA ∗∗∗∗∗∗∗∗∗∗∗∗∗∗
2017‑09‑28 15:41:23 INFO DataCreator:136 ‑ Saved 134 rows of training data 'NCAA‑BB‑TRAINING_DATA‑2015.trn'
2017‑09‑28 15:41:29 INFO DataCreator:132 ‑ ∗∗∗∗∗∗∗∗∗∗∗ SAVING TRAINING DATA ∗∗∗∗∗∗∗∗∗∗∗∗∗∗
2017‑09‑28 15:41:29 INFO DataCreator:136 ‑ Saved 134 rows of training data 'NCAA‑BB‑TRAINING_DATA‑2017.trn'
Ix:~/home/development/projects/developerWorks/NcaaMarchMadness/src/main/script sperry$
After the training data was created, it was time to train and validate the networks I would use to make my NCAA Basketball tournament picks.
I said at the beginning of this tutorial that I would discuss normalization, and that time is now.
The reason that all input data is normalized is that not all data is created equal (numerically speaking). For example, one statistical category of data is Won/Loss percentage for each team, which is a percentage, and, as you would imagine, has values between 0 and 1. Contrast that with Fouls per Game, which is an average over all games played, and has a lower bound of zero with no upper bound at all.
It is not meaningful to do a raw comparison of two numbers whose ranges are different. So I had to normalize the data (specifically by using a normalization technique called Feature scaling). The equation that I used was simple:
So for any raw value X I calculated the normalized value X' over the range of values from Xmin to Xmax. Of course, that means that I needed to compute the min and max values for all of the stat categories. But because I had the data in the database, it was easy to define a view to let PostgreSQL do this for me (check out the v_season_analytics view, and its definition in create_views.sql).
DataCreator is responsible for normalizing all of the training data. Finally, I was ready to begin training the networks.
Step 4. Train and validate the network
Using supervised learning to train and validate an ANN is half art, half science. I needed to know the data well (science), but I also had to guess (art) at the best network structures until I found a few that worked. I had to ask questions like:
- How many of the 23 available statistical categories do I want to use?
- How many hidden layers do I want the network to have?
- How many neurons should there be in each hidden layer?
- What should the network's output look like?
Turns out, I ended up using 21 of 23 categories. So there are 42 inputs (one for each team). As for output, I decided it should be a normalized score based on the example match-ups between the two teams: for any given simulated game, the team with the higher normalized score was the winner.
As far as the number of hidden layers and neurons in each goes, I did some research, but in the end it just boiled down to trial and error. I ran the training data through the network a BUNCH of times, and kept the networks that performed > 70%.
I wrote a program called MlpNetworkTrainer whose sole purpose in life was to train and validate networks, and save those networks that perform above the threshold I specified.
Here's what I did: I instructed MlpNetworkTrainer to train the networks using data from 2010-2014, then validate the networks against data from 2015 and 2016, and keep those that performed above the 70% threshold.
If the network performed above the 70% threshold, the program saved that network to be used as part of the network array to make my tournament picks. If not, it was discarded.
I repeated this process until I had 31 networks that I could run as an "array" of networks in the simulated tournament.
Step 5. Simulate the tournament
After the regular season ended (around March 10) I downloaded the CSV data, ran it through SqlGenerator, and loaded it into the DB.
After the NCAA tournament selection committee made its selections for the 2017 tournament, I created a file called tourney_teams_file_2017.txt that contained all of the teams that would be participating in the tournament (I had done this already for the 2010-2016 seasons).
I ran a program I had written that creates SQL INSERTs so that I could load the 2017 participants into the tournament_participant table. I had already done this for previous years so that I could create the data that I would need to validate the networks.
I was all set. I had 31 trained and validated networks and I had season data for 2017. Nothing could stop me now. Except that I needed a way to visualize how the teams would match up against each other.
So I wrote a program called TournamentMatrixPredictor to generate a CSV file that I could load into Open Office Calc for each team participating in the tournament. Each file contained the predicted outcome of a particular team in a simulated game between that team and every other team in the tournament.
The file for Middle Tennessee State is shown in the following figure, loaded into Open Office as a Calc spreadsheet.
Figure 4. The network's predictions for Middle Tennessee State

The spreadsheet shows simulations of Middle Tennessee State (TEAM) against every other team (VS OPPONENT) in the tournament (including Middle Tennessee itself), along with averages of the 31 network's predictions that Middle Tennessee would win (WIN %), lose (LOSS %), or tie (PUSH %) its opponent, and the individual results of the networks.
Stretching out to the right (out of frame) is the individual network results (predicted winner only). For example, the network whose structure is 42x42x107x49x10x14x2x2 — 42 input neurons, 6 hidden layers (42 neurons in the first, 107 in the next, and so on) and 2 output neurons — shows its predicted winner of each match-up.
In the first round, 12-seed Middle Tennessee State's opponent was heavily favored, 5-seed Minnesota (the lower the seed, the more heavily favored that team is considered to be by the NCAA selection committee). The array's average was a bit nebulous: the 31 networks working together predicted that Middle Tenn would win, lose, or tie with 37.14%, 17.14%, and 45.71% certainty, respectively.
I was not completely sure what to do. Had science failed me? Let's face it, sporting events are chaotic (hence the "madness" in "March Madness"). So I knew that close calls like this would come down to some guess work. While more of the networks in my array couldn't pick a clear winner (45.71%), those that did more than doubled those that didn't (37.14% to 17.14%).
In the end, two things made me pick Middle Tenn for my bracket: they had just won their conference (Central USA) and had an automatic tournament bid, and my deep layer networks (well, deep for this effort) all overwhelmingly picked Middle Tenn. So I picked Middle Tenn to upset Minnesota. Turns out, the network was right. I went through this process for all teams in the tournament, filled out my brackets, and hoped for the best.
Like I said earlier, the network (and I) got about 72% of the picks correct. Not bad. And it was a lot of fun.
Conclusion
In this tutorial, I talked about Artificial Neural Network (ANN) concepts, then I discussed the multilayer perceptron, and finally walked you through a case study where I trained an array of MLP networks and used them to pick winners of the 2017 NCAA Division I Men's Basketball Tournament.