Tutorial
Create a single customer view of your data with IBM Watson Query
Virtualize your data using business terms to ensure that the data is governed and protectedEnterprise data is often spread across various data stores, such as data marts, data warehouses, and data lakes. Companies often seek to break down these silos by copying all of the data into a central store for analysis. Such duplication of data can cause issues such as stale data and additional costs for managing the central data store.
Data virtualization with IBM Watson Query is a data management approach that provides the ability to query multiple data sources without copying and replicating the data, thereby reducing costs. It can be used to generate a single customer view of the data irrespective of where the data is located and how the data is formatted.
In this tutorial, you learn how to virtualize governed and protected enterprise data by using Watson Query on IBM Cloud Pak for Data, and join the virtual data to create a single customer view of the data.
Learning objectives
In this tutorial, you:
- Add a data source for Watson Query
- Virtualize the data with business terms
- Create a joined virtual view
- Assign governance terms and data classes to the columns in the virtual view
- Provide users with permission to access the virtual view
- Log in as various users to access the virtual view and add it to an analytics project
Prerequisites
- IBM Cloud Pak for Data 4.6
- Watson Knowledge Catalog on IBM Cloud Pak for Data
- Watson Query on IBM Cloud Pak for Data
- The steps in Protect your data using data privacy features must be completed.
Estimated time
It should take you approximately 45-60 minutes to complete the tutorial.
Step 1. Provision Watson Query on IBM Cloud Pak for Data
Start by provisioning Watson Query on your IBM Cloud Pak for Data instance.
Log in to IBM Cloud Pak for Data
Log in to your IBM Cloud Pak for Data instance as the
adminuser.
Provision Watson Query on IBM Cloud Pak for Data
Go to the Navigation Menu, expand Services, and click Services catalog.
Choose the Data sources category and then click the tile for Watson Query.
Click Provision instance.
Follow the instructions to provision the Watson Query instance.
Note: For deployment using Managed OpenShift, you must do the following:
- Decide whether to check the Updated the kernel semaphore parameter checkbox.
- Do NOT choose the defaults for storage. If you use Portworx storage, select portworx-db2-rwx-sc as the storage class. Otherwise, choose ibmc-file-gold-gid as the storage class.
Step 2. Add a new data source connection to Watson Query
You already added your IBM Db2 on Cloud service instance as a Platform connection to IBM Cloud Pak for Data as part of the Learn to discover data that resides in your data sources tutorial. You now add the same data source as a connection in Watson Query.
Note: If your data source is in a remote data center (not in the same data center as the IBM Cloud Pak for Data instance), you can improve the performance of your data source connections using remote connectors.
Go to the Navigation Menu, expand Data, and click Watson Query.
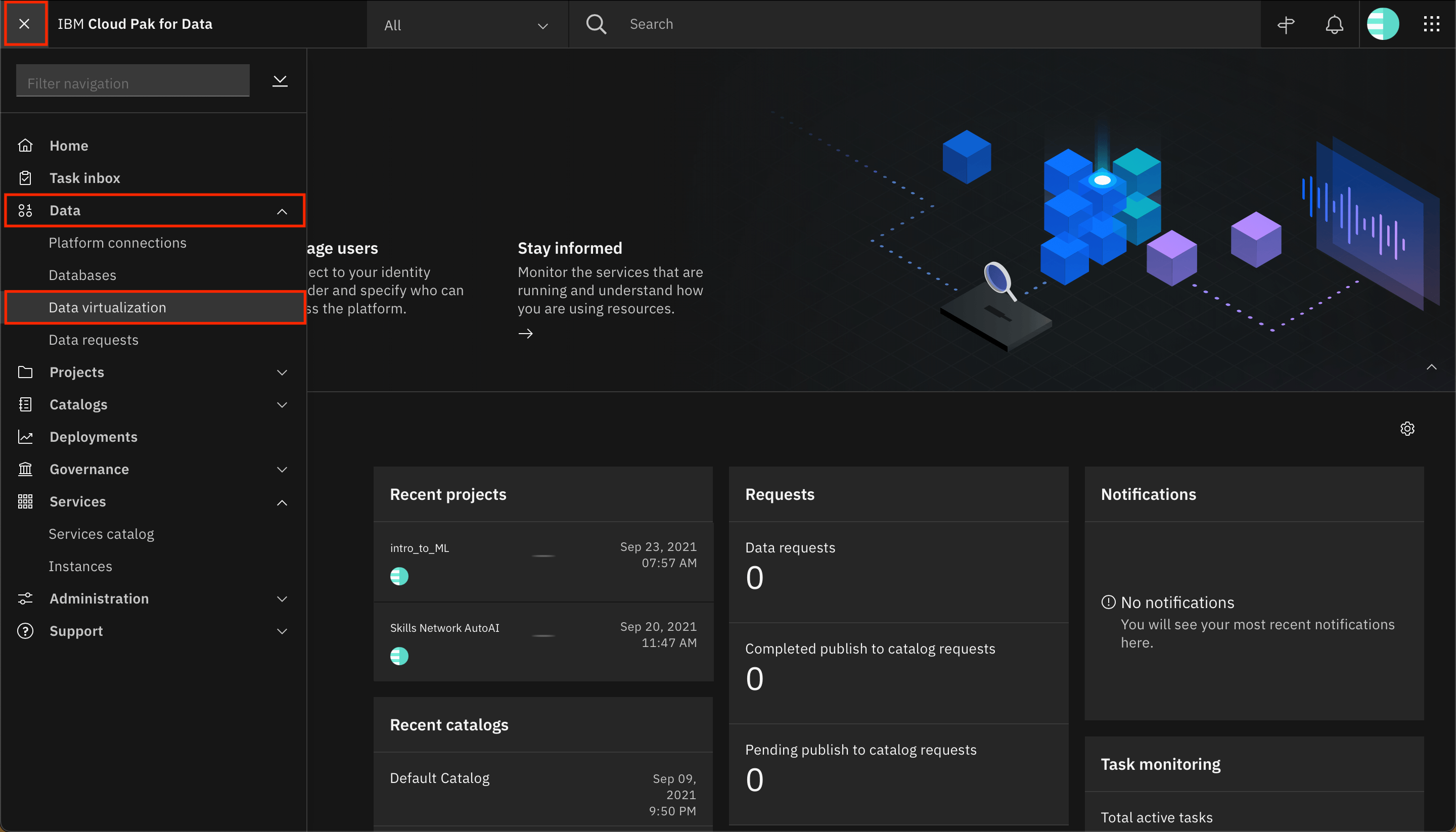
Open the Data Virtualization menu. Expand Virtualization within the menu, and click Data sources.
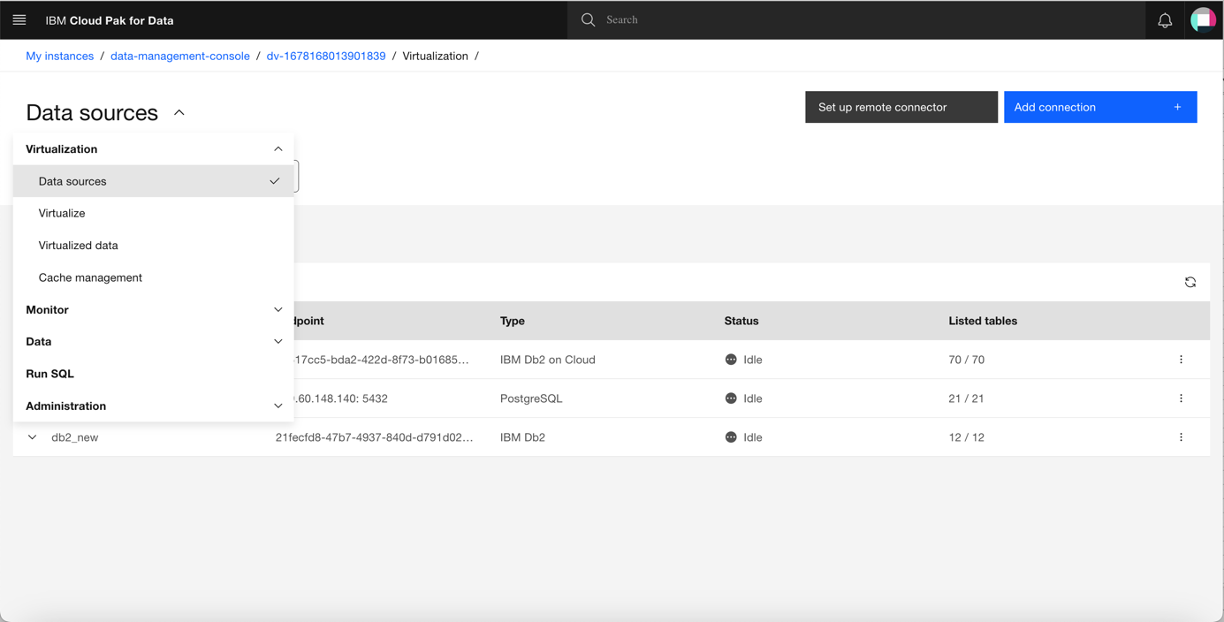
Click Add connection +, then click Existing platform connection.
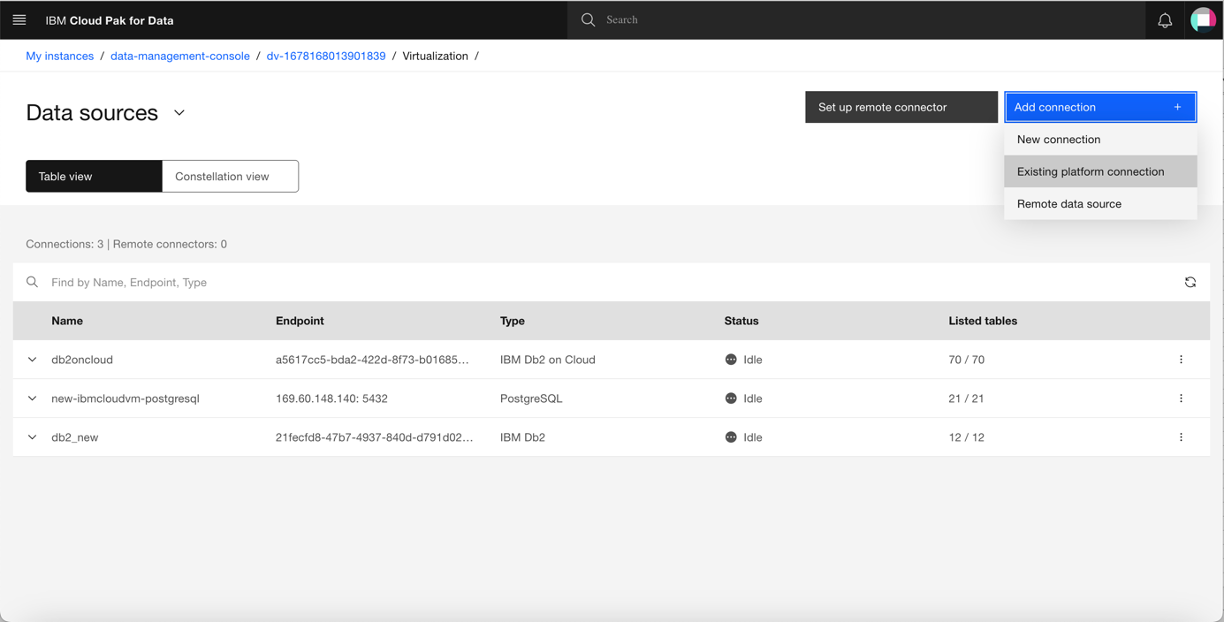
Select your Db2 connection from the list of connections, and click Add.
Note: Remember to select the same Db2 connection that was used for discovering the data in the Learn to discover data that resides in your data sources tutorial.
Click Skip.
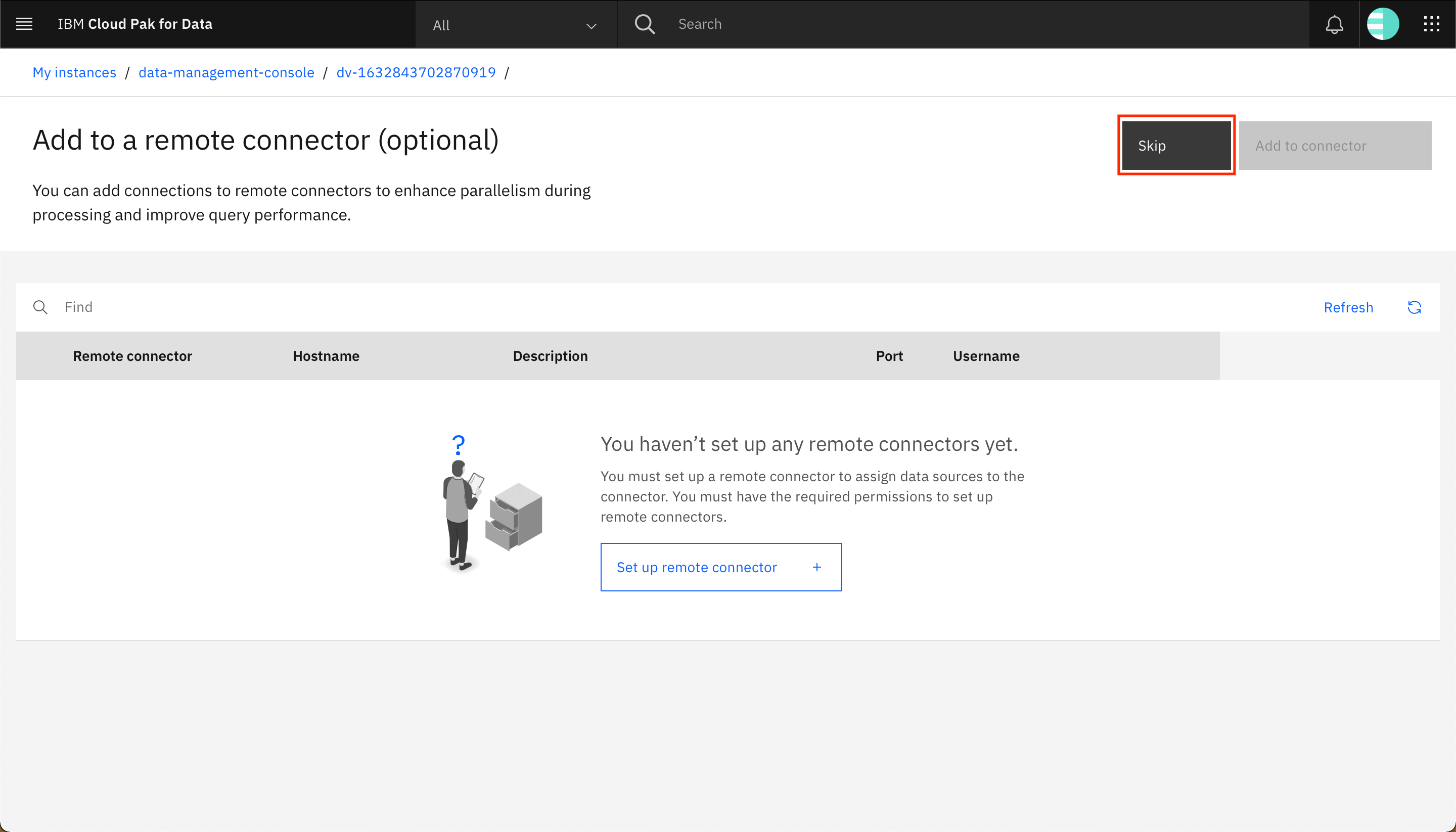
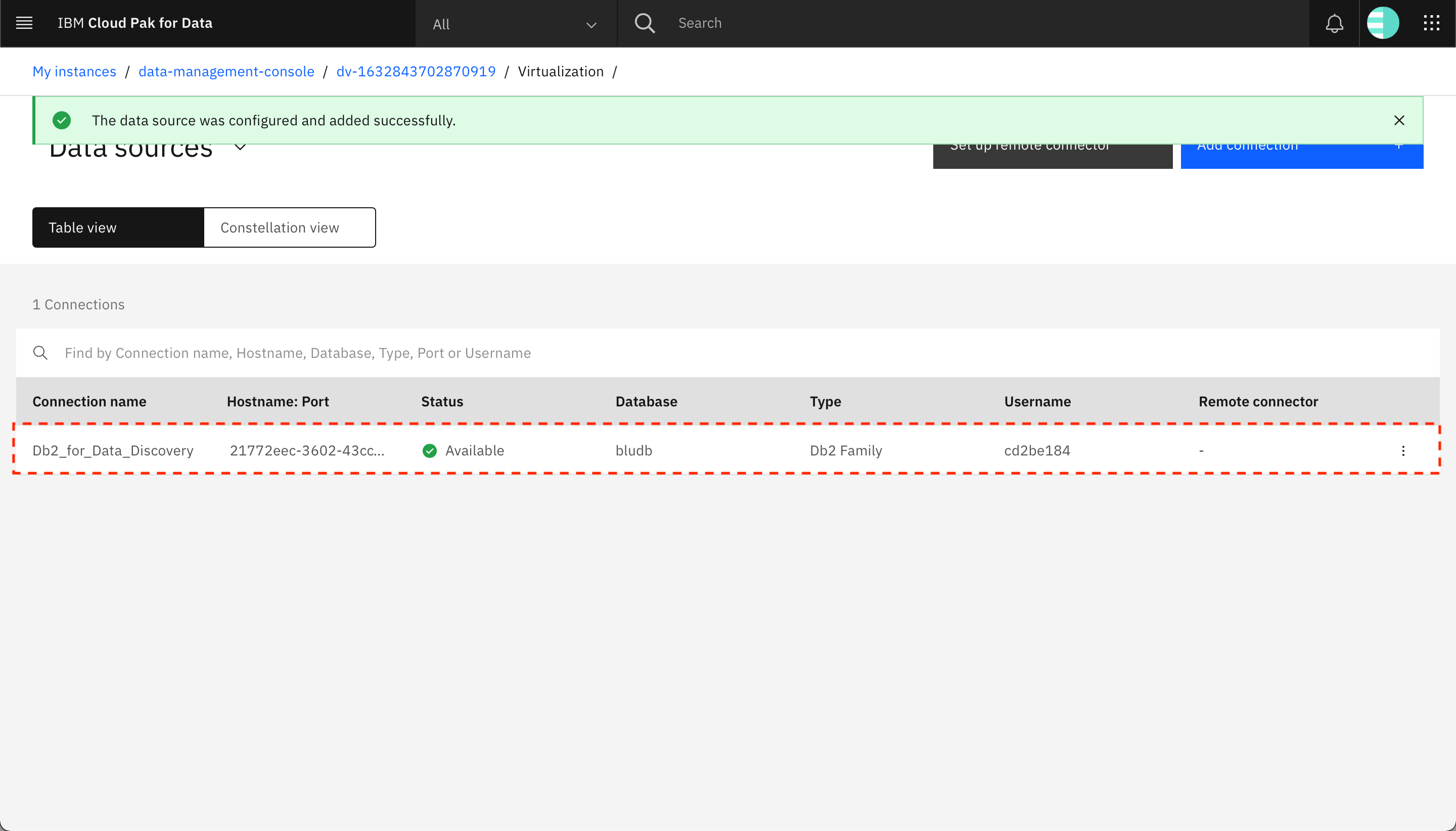
The data connection is added as a data source for Watson Query, and you should see the data connection listed on the Data sources screen.
Step 3. Create virtual tables and views using data virtualization
Now that the data source is available in Watson Query, you can virtualize the data tables within the data source. After the tables are virtualized, you can create virtual views by joining the virtual tables.
Virtualize the tables with business terms
Open the Data virtualization menu, expand Virtualization, and click Virtualize.
Several tables appear. Find and select the PATIENTS and ENCOUNTERS table contained in the Db2 connection that you added. You can also search for the tables using the search bar. When selected, click Add to cart, then View cart.
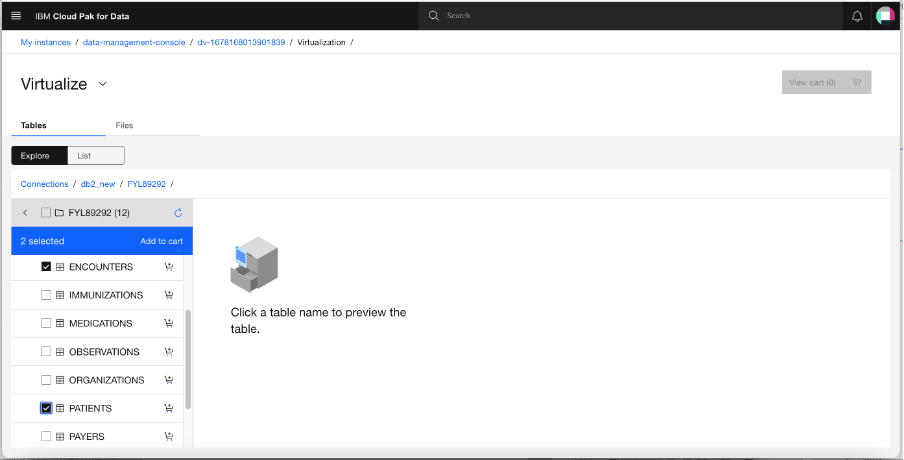
Note: In addition to the PATIENTS and ENCOUNTERS tables, you can also select the other tables from the Healthcare data set, provided that you uploaded them to your Db2 database.
The next screen prompts you to choose how you want to assign the virtualized data to a data request, a project, or neither. Uncheck Assign to project or data request. Click the three vertical dots for the PATIENTS table to open the overflow menu, and click Edit columns.
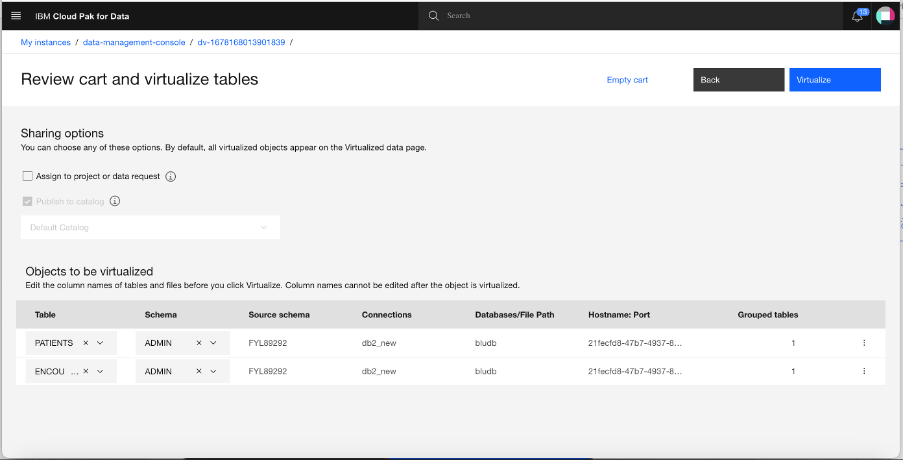
Click the checkbox for Replace all columns with business terms. This replaces the names of all of the columns in the table with the business terms that were assigned to these columns. Click Apply to apply the changes.
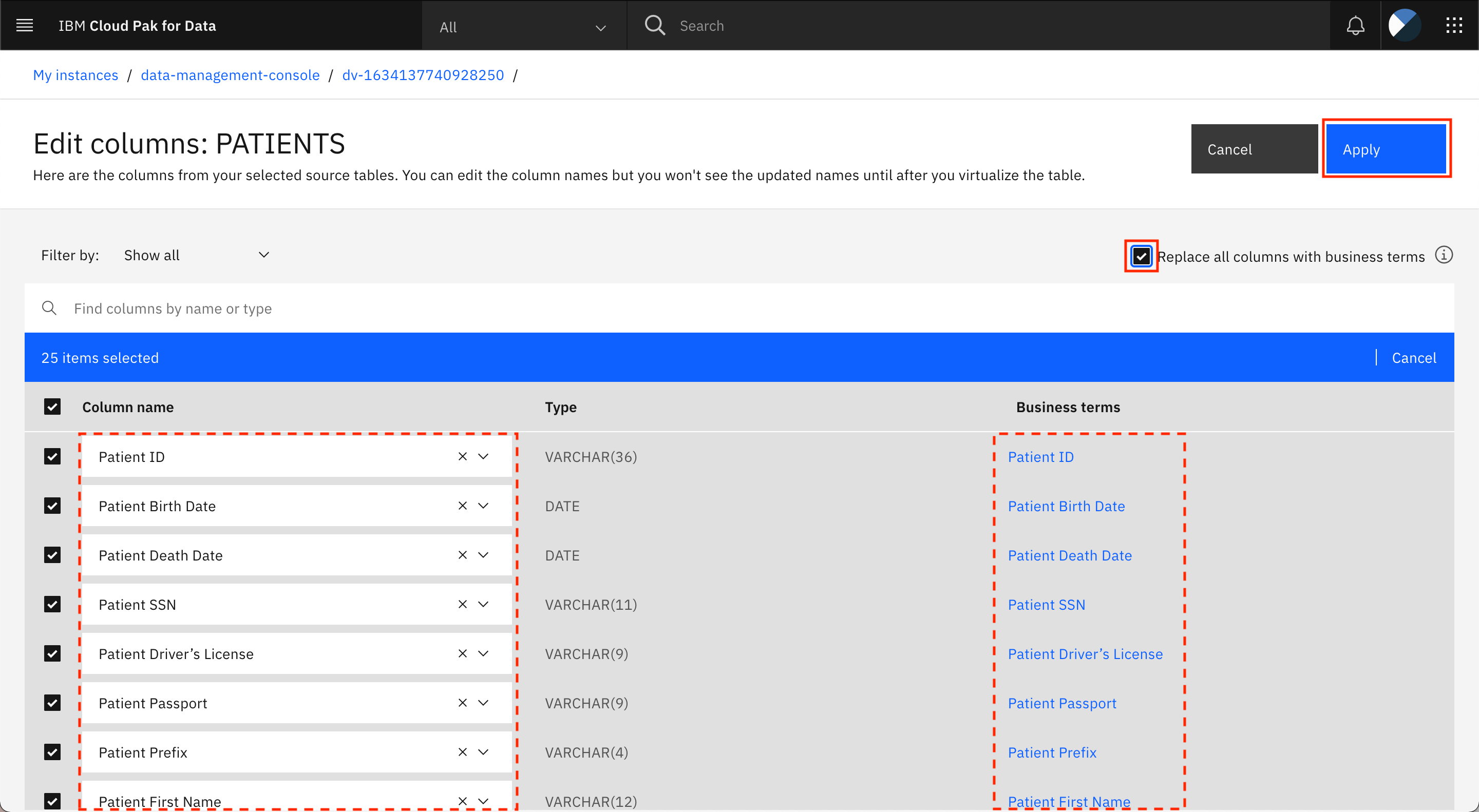
Repeat the steps to replace the column names with business terms for the ENCOUNTERS table, then click Virtualize.
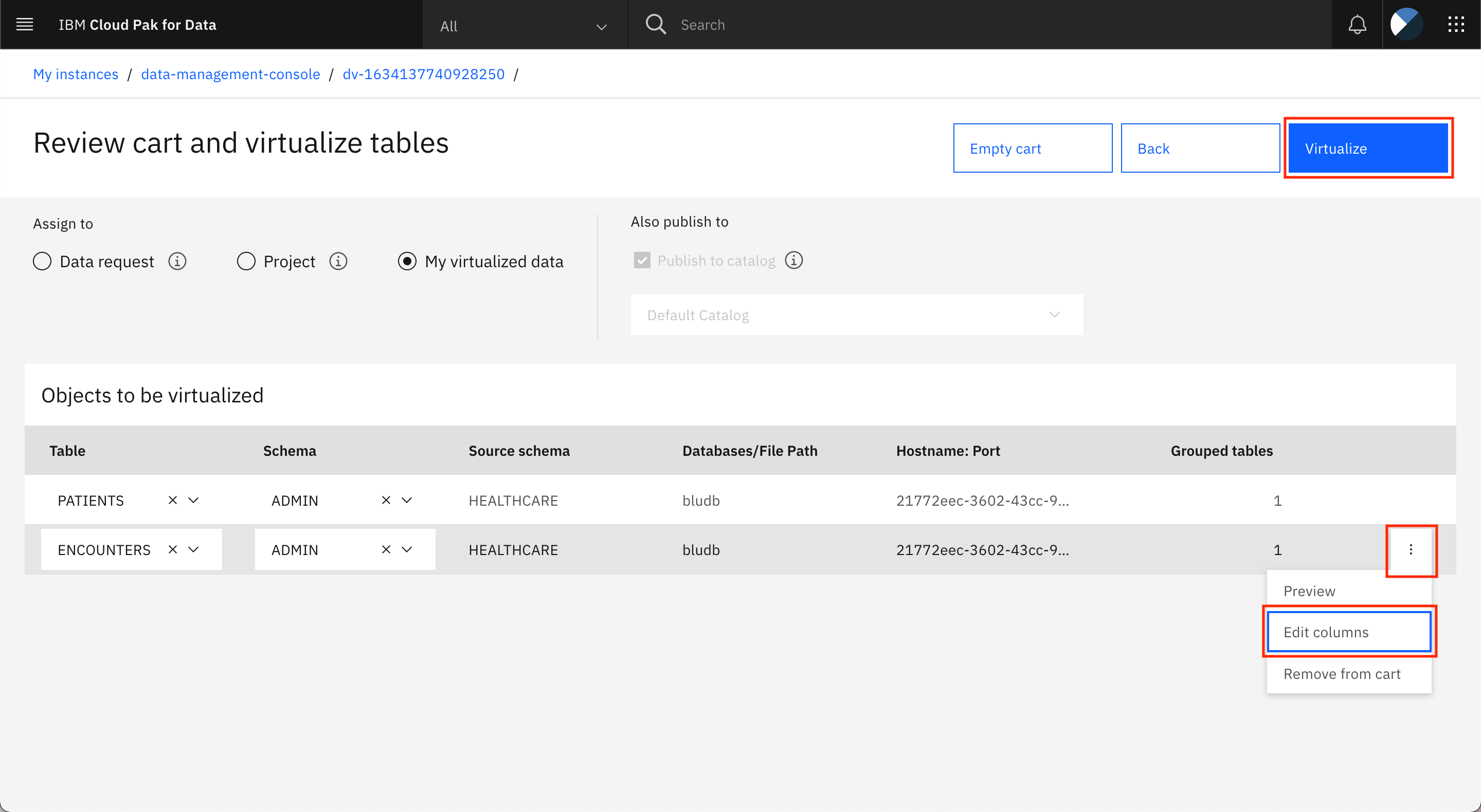
Note: If you have added other tables to your cart in addition to PATIENTS and ENCOUNTERS, you can also replace the column names with the business terms for all of those tables as long as you had previously assigned business terms for the tables and published the tables to the Default catalog.
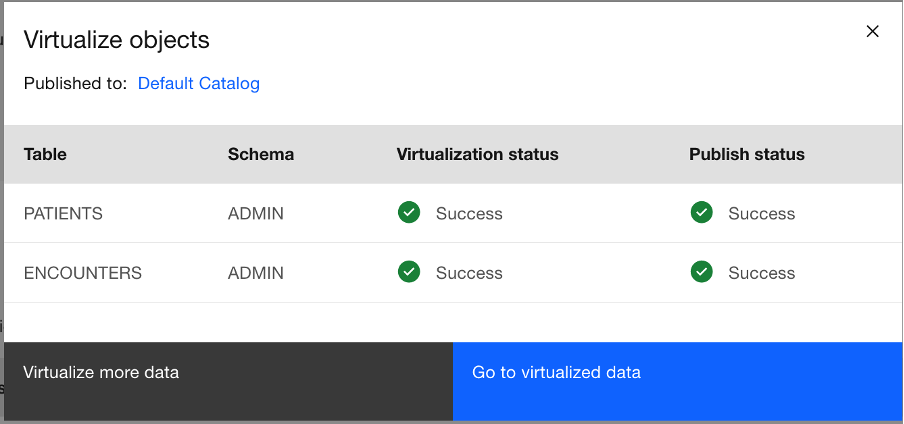
You see a notification that the virtual tables have been created. To see the newly virtualized data, click Go to virtualized data.
Create a merged view by joining the virtualized data
The next step is to join the virtual tables that have been created to create a merged view of the data. One option to get a merged set of data from multiple tables is to use a notebook to write multiple lines of code that join the data. Watson Query, on the other hand, makes it much easier to handle joins between multiple data assets. Joining data assets using Watson Query only requires a few mouse clicks.
Select the PATIENTS and ENCOUNTERS tables, and click the Join button.
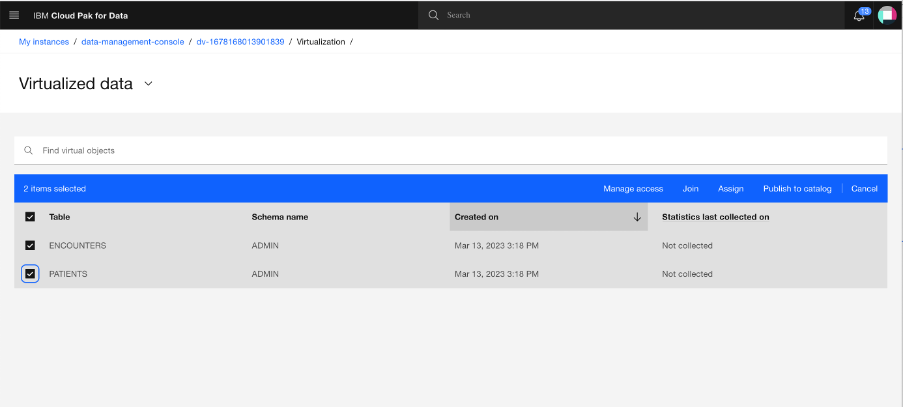
The columns of both the tables are shown on the screen. You can see that the business terms for the columns are displayed as the column names because you chose to replace the column names with business terms when you virtualized the tables.
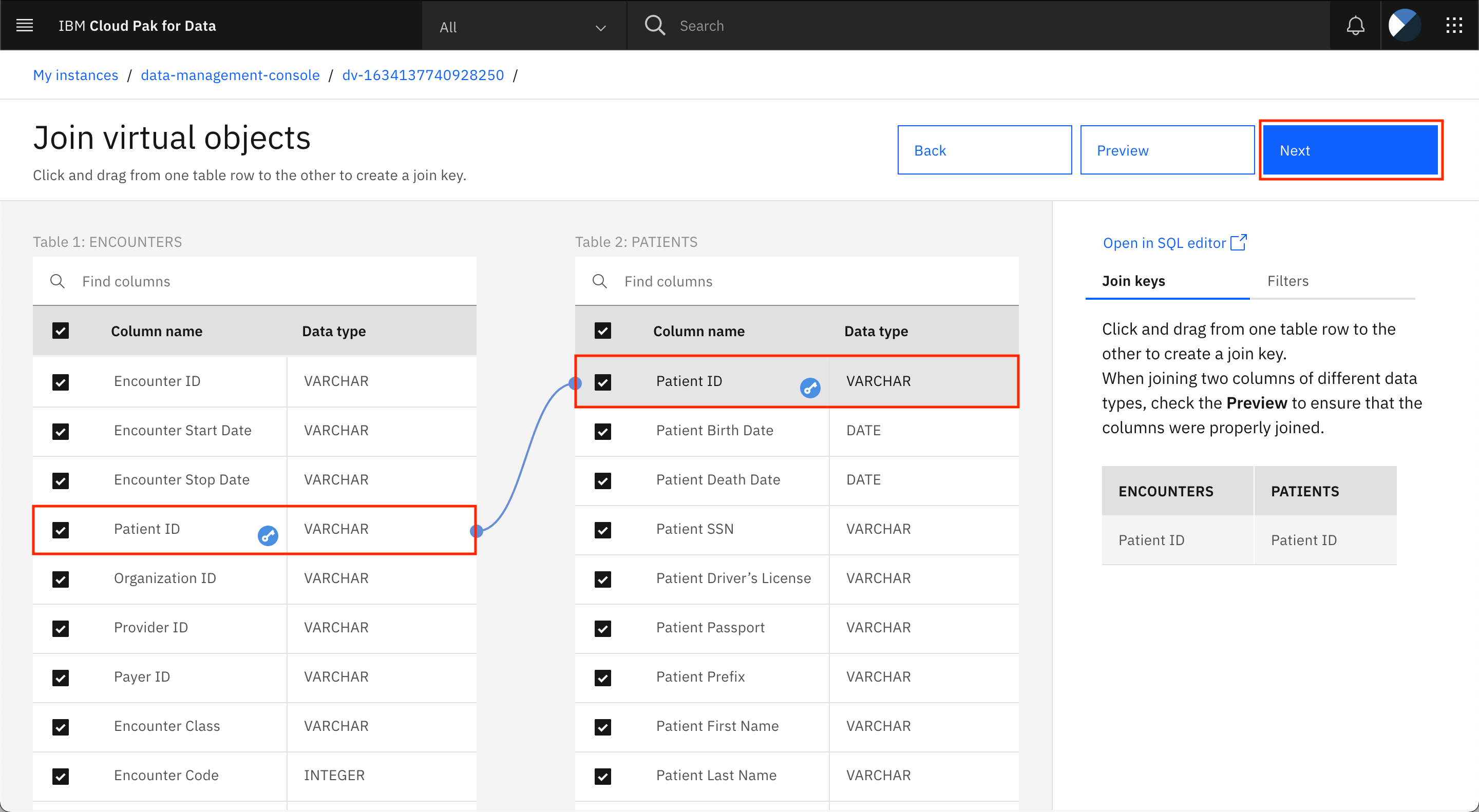
To join the tables, you must pick a key that is common to both tables. In this case, the Patient ID column is common between the two tables, and you can mark this column as the key by clicking the Patient ID column in one table and dragging it to the Patient ID column in the other table. When you see a line or curve connecting the columns in the two tables, click Next.
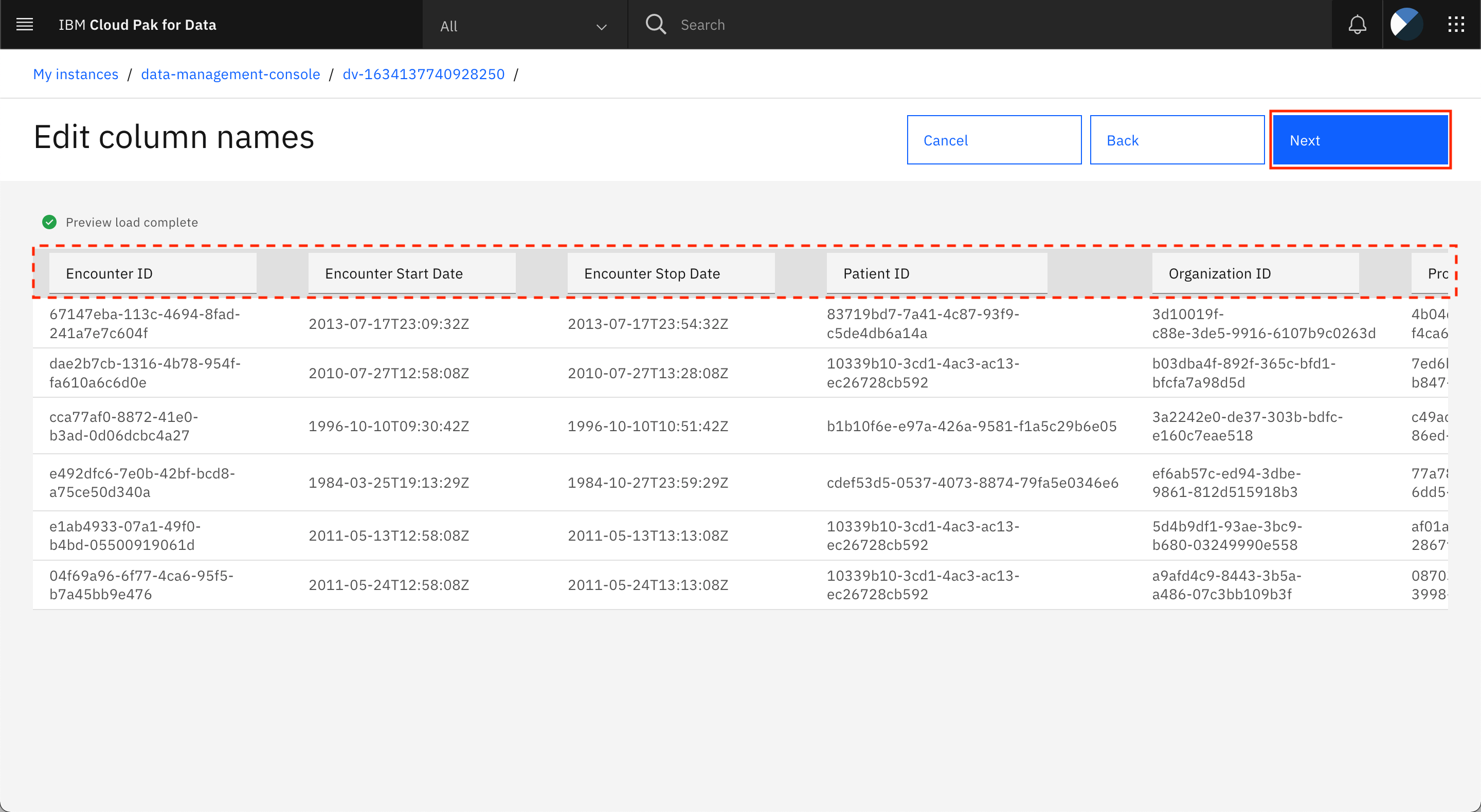
You can edit the column names for the joined view. Because the original column names already have been replaced with the business terms, you can leave the column names as they are. Click Next.
On the next screen, provide a name for the joined view (
PATIENTS_ENCOUNTERS). Uncheck Assign to project or data request. Click Create view.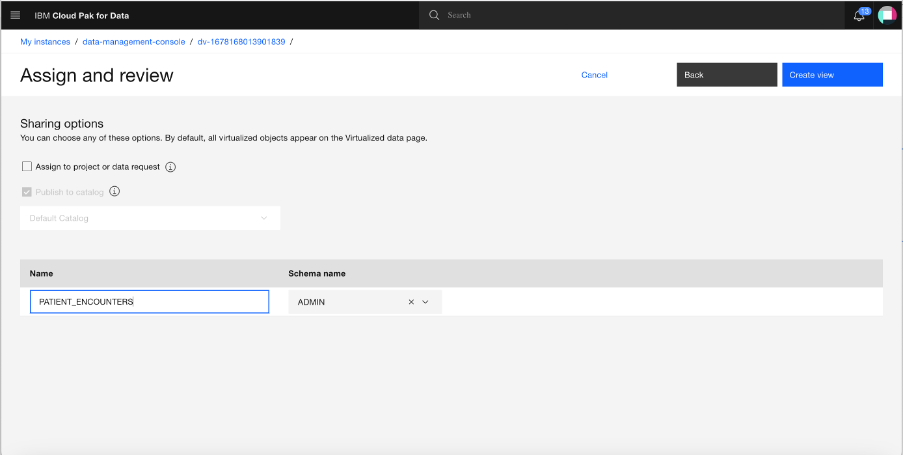
You are notified that the join has succeeded. Click Go to virtualized data to view your virtualized data.
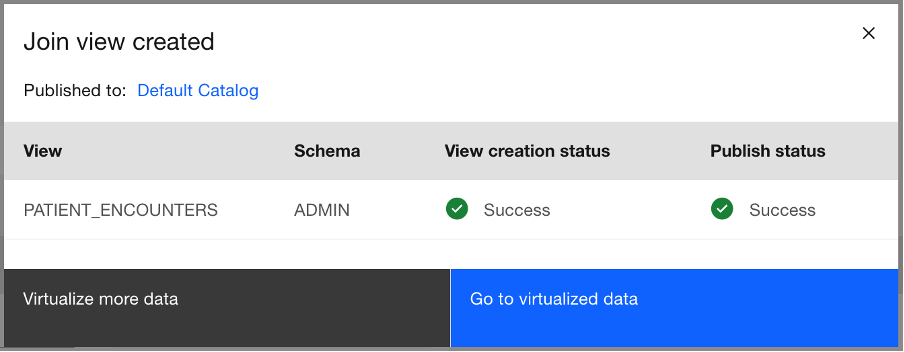
Step 4. Grant users with access to published view
Now that the virtual view has been created and published to the Default Catalog, you can provide users with access to the published view. To do this, the users must be granted access to the Default Catalog as well as Watson Query.
Note: You are granting access to the published view to the two users (regular_user and restricted_user) that you used to verify the enforcement of the data protection rules in the previous tutorial. These users were already granted access to the Default Catalog and only need to be granted access rights to Watson Query now.
Grant Data Virtualization access to users
IBM Cloud Pak for Data users that need to use data virtualization functions must be assigned specific roles based on their job descriptions. These roles are Admin, Engineer, User, and Steward. You can learn more about these roles in the IBM Cloud Pak for Data documentation.
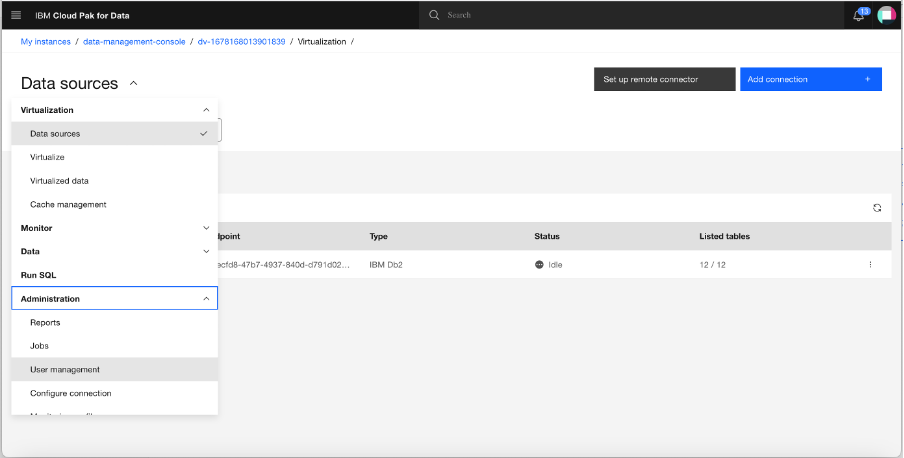
Go to the Virtualization menu and click Data sources, then click Administration and then click User management.
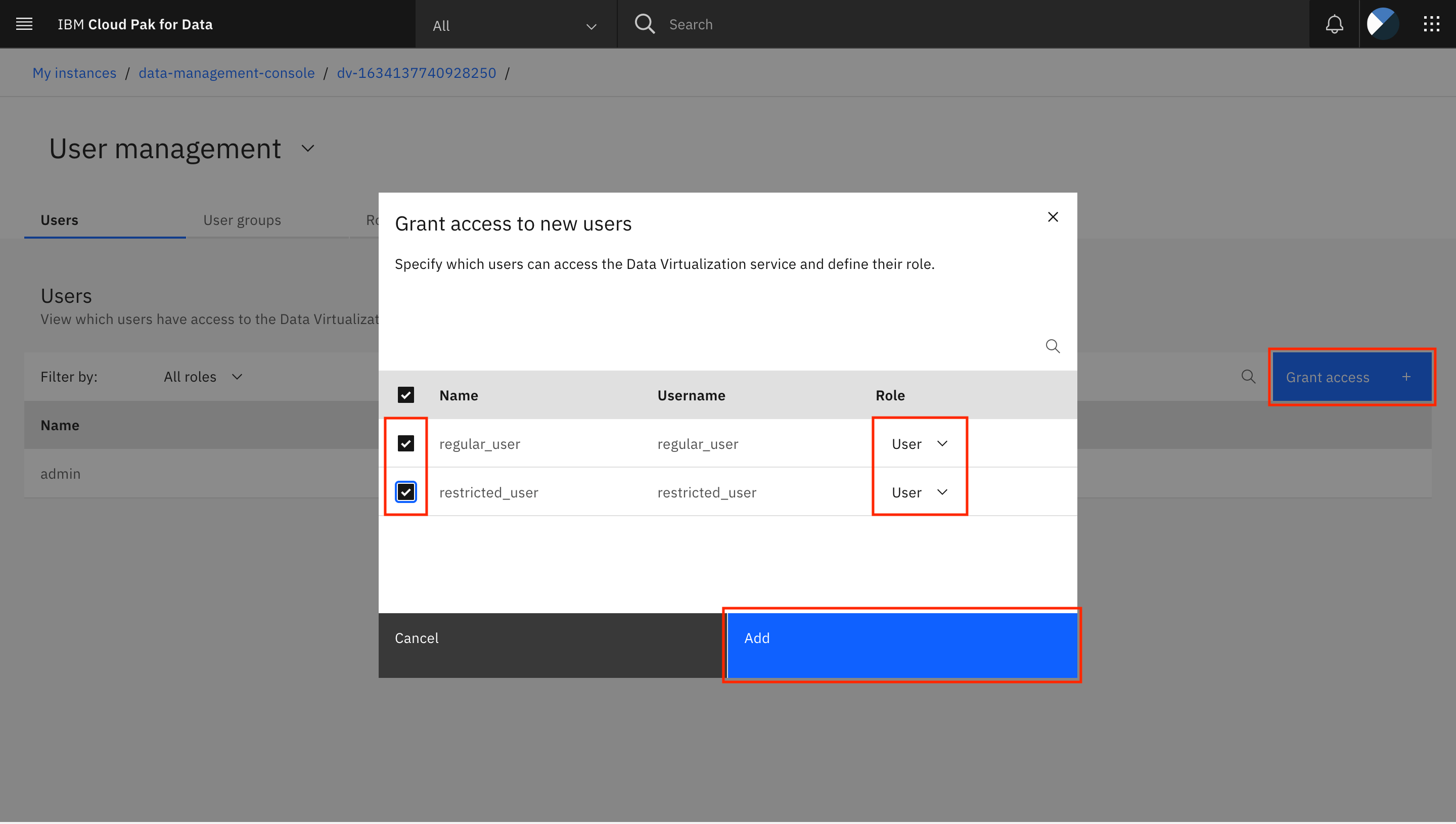
Click Grant access +. In the dialog, select the users that you want to add to Watson Query. Using the drop-down menu, provide the User role to each of these users. Click Add.
Step 5. Update business terms and data classes for the published virtual view
Earlier, you were able to virtualize the tables using business terms. These business terms came from the tables that were discovered and subsequently published to the Default Catalog. However, the virtual tables only had the column names replaced with the business terms. The virtual tables do not have any data class and business term assignments that were made during analysis of the discovered tables.
You now update the published virtual view with the correct data classes and business terms.
Note: Updating the data classes and business terms here is important for the data protection rules that you created in the previous tutorial to be applied to the virtual view. In the absence of the correct data classes and business terms, the data is not protected (by denial of access, masking, substituting, or obfuscating), and the users are able to see all of the original data.
Go to the Navigation Menu, expand Catalogs, and click All catalogs.
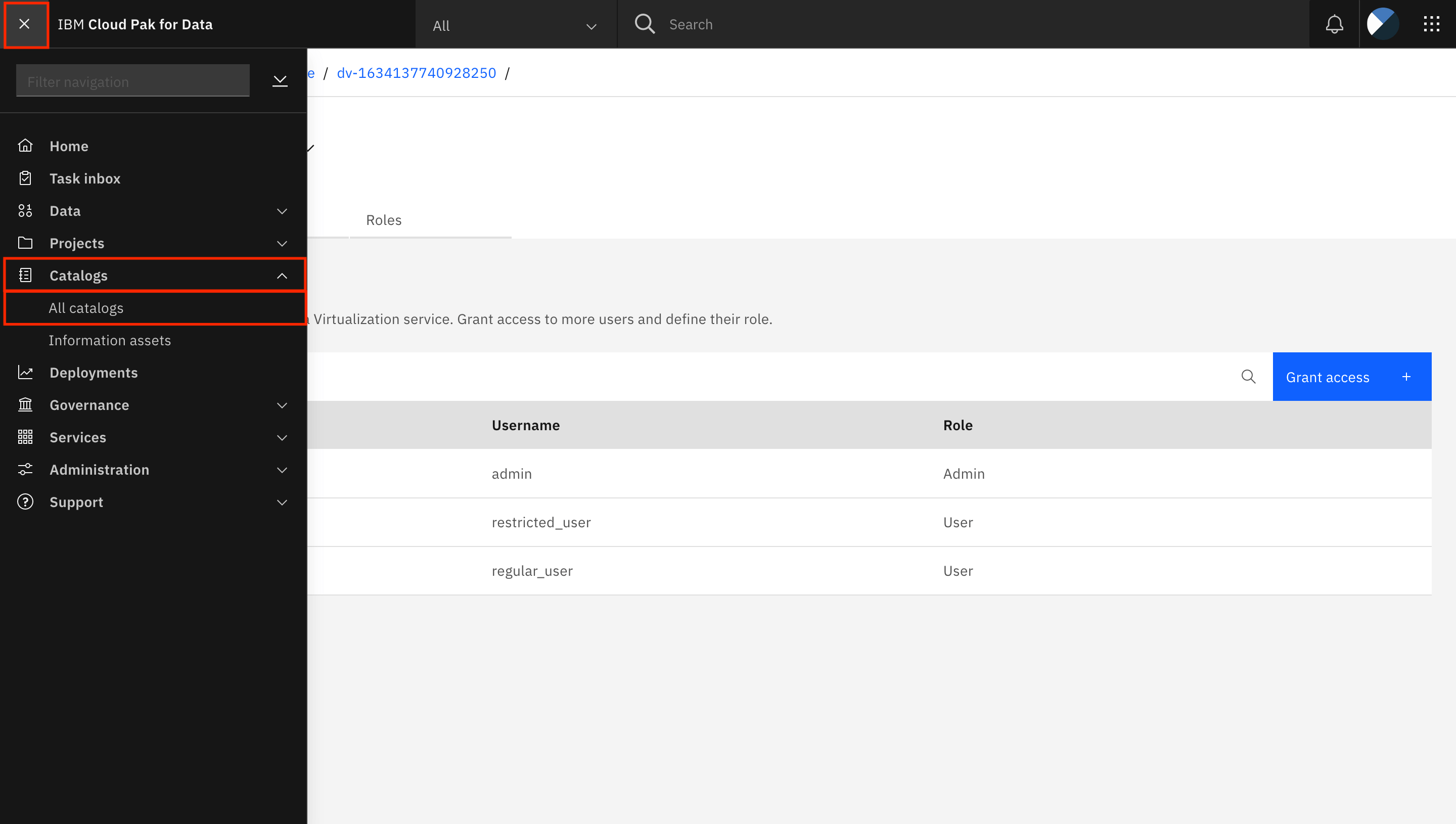
Click the tile for the Default Catalog.
Scroll to and click the name of the
ADMIN.PATIENTS_ENCOUNTERSasset.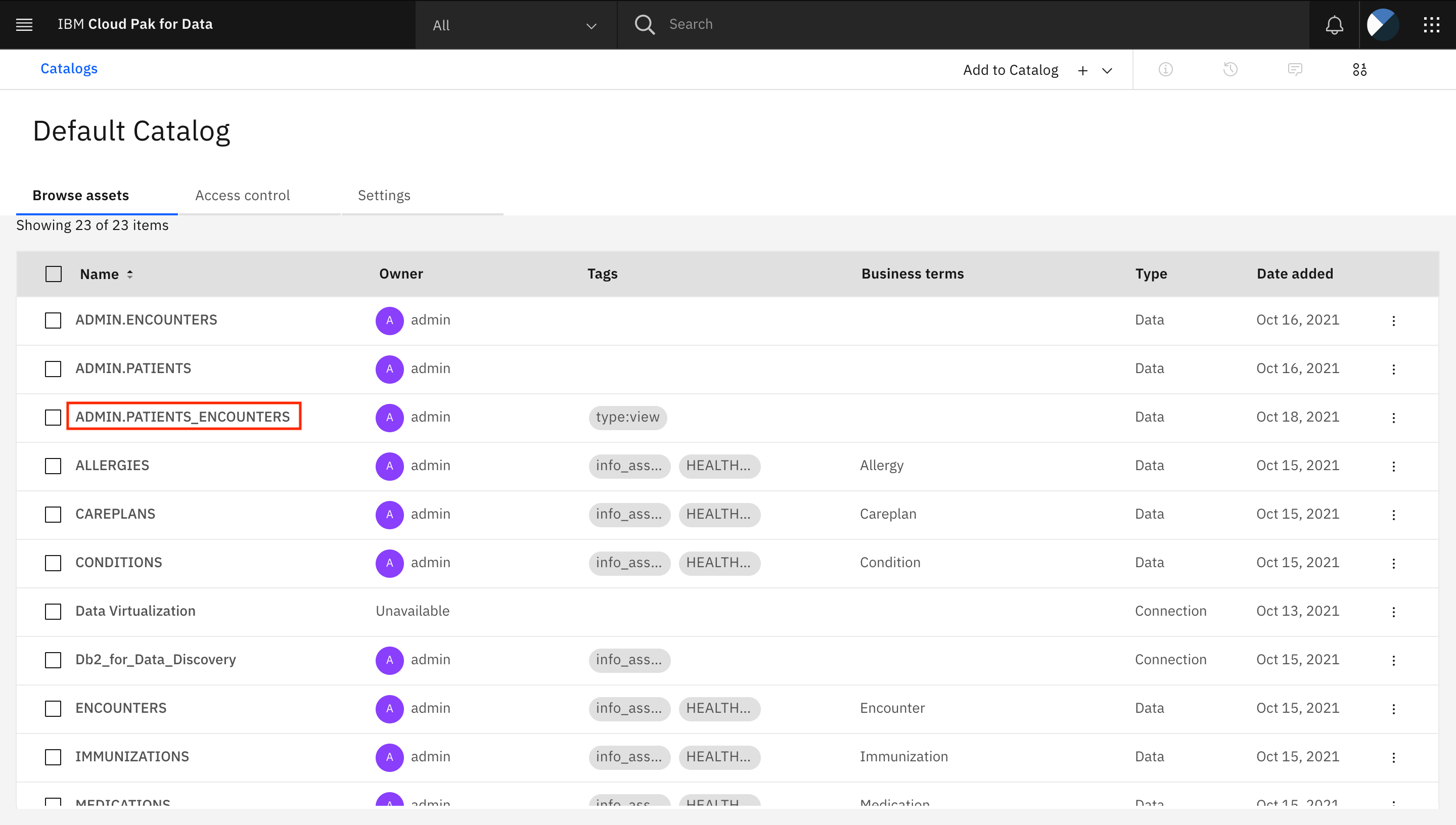
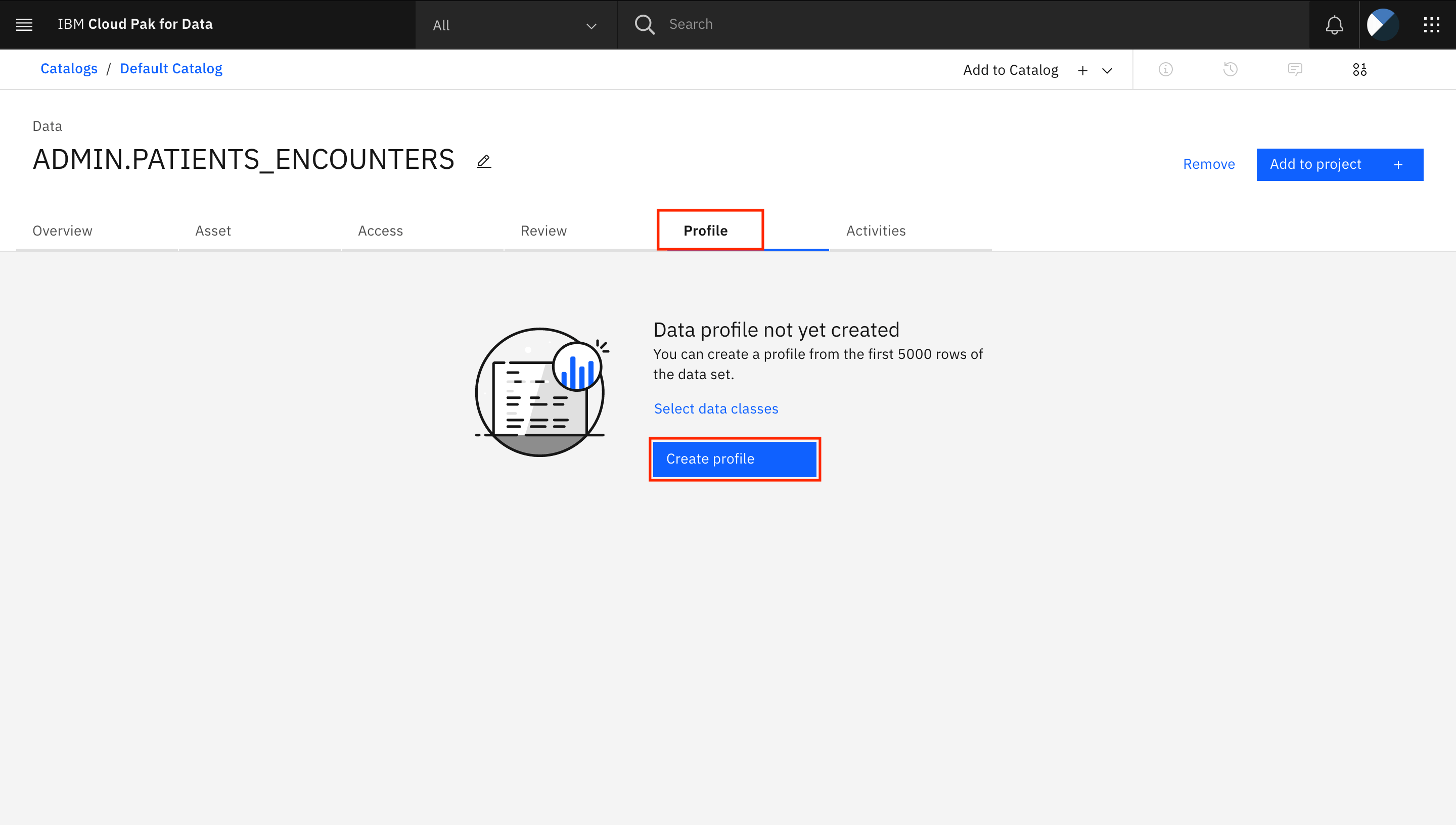
Create a data profile for the published view
Go to the Profile tab. Click Create profile. Watson Knowledge Catalog now looks at the first 5,000 rows from the view to identify and assign data classes for all of the columns.
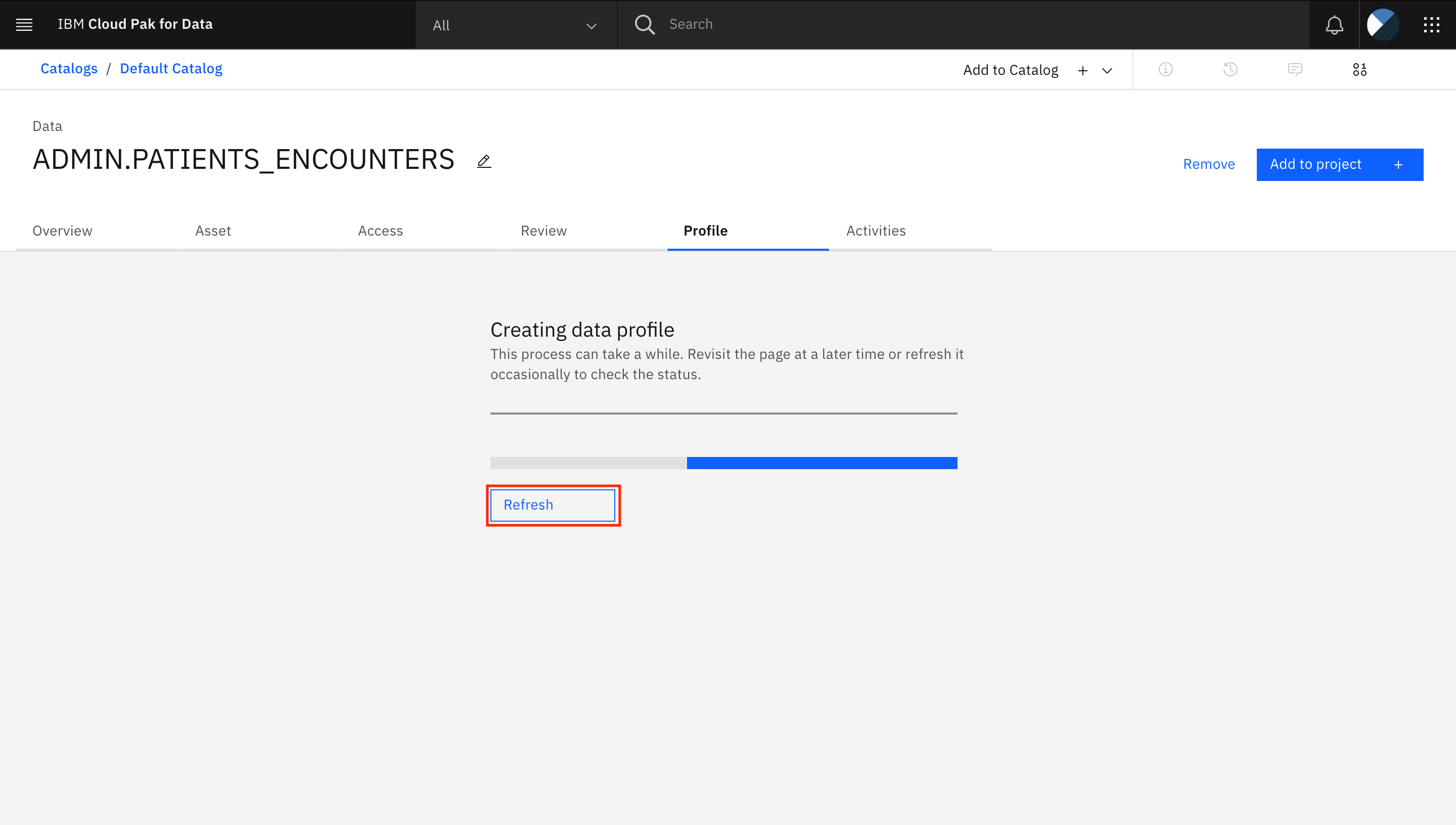
Creating the data profile can take some time. You might need to refresh the page occasionally to check the status.
Update data classes for the published view
Watson Knowledge Catalog attempts to identify data classes for all of the columns and selects one data class for each column. You can go through the data classes that have been identified and assigned for each column and correct the ones that are incorrectly assigned. For example, the Encounter Code column has been assigned the
Numericdata class. To update the data class, click the arrow under the column name Encounter Code. A list of other data classes that have been suggested by Watson Knowledge Catalog is displayed. You can select a new data class by clicking one of the data classes listed here or by clicking View all to pick a data class that was not suggested by Watson Knowledge Catalog. For the Encounter Code column, click the correct data class ofEncounter code.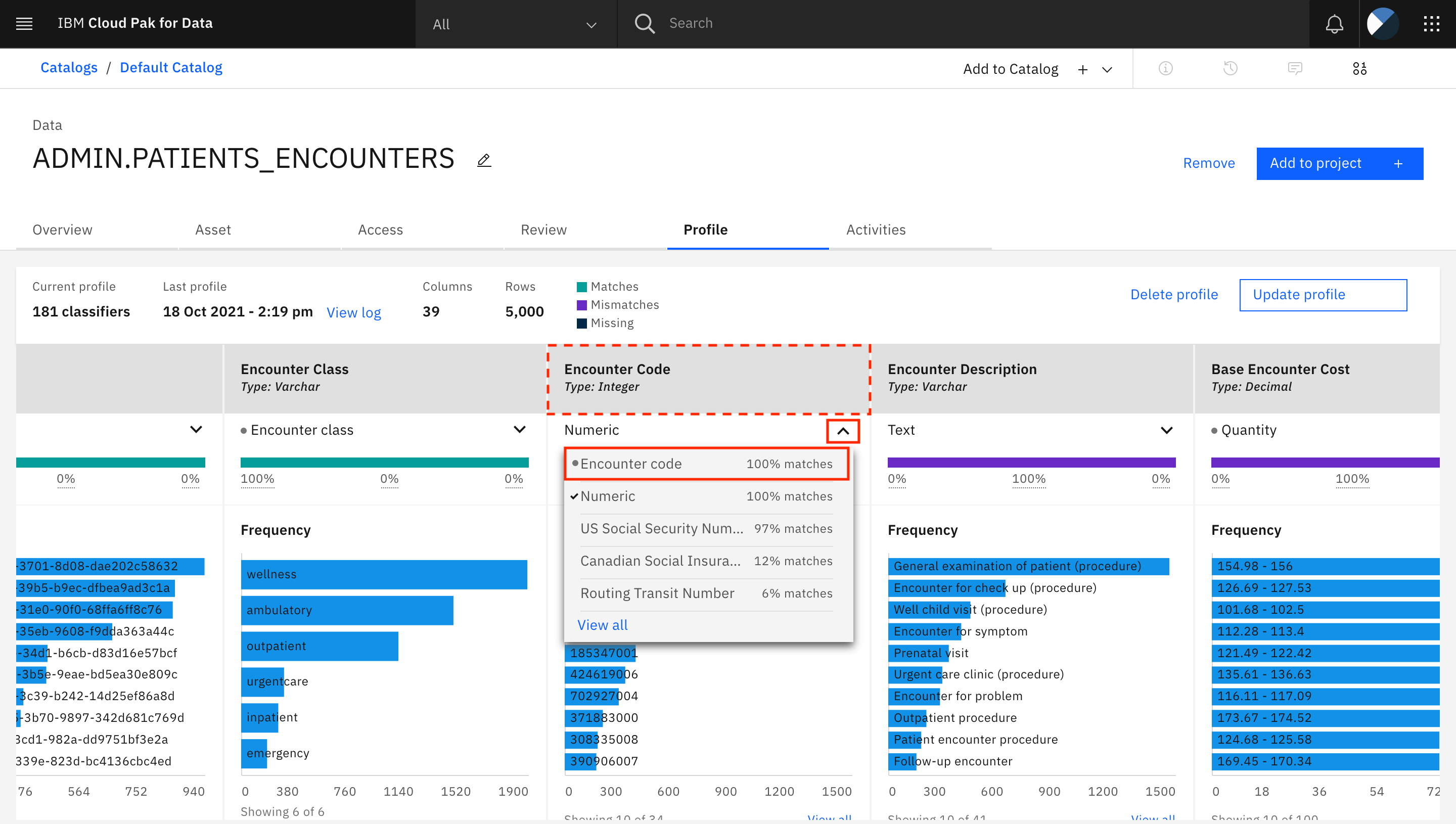
The data class for Encounter Code column is updated. Repeat the process to verify and update the data classes for all of the other columns in the asset. You can refer to the Data Asset Annotations file to obtain the data classes for the columns in this asset. Remember to use the data classes assigned to the columns in the PATIENTS and ENCOUNTERS tables because the
PATIENTS_ENCOUNTERSview was created by joining these two tables.
Update business terms for the published view
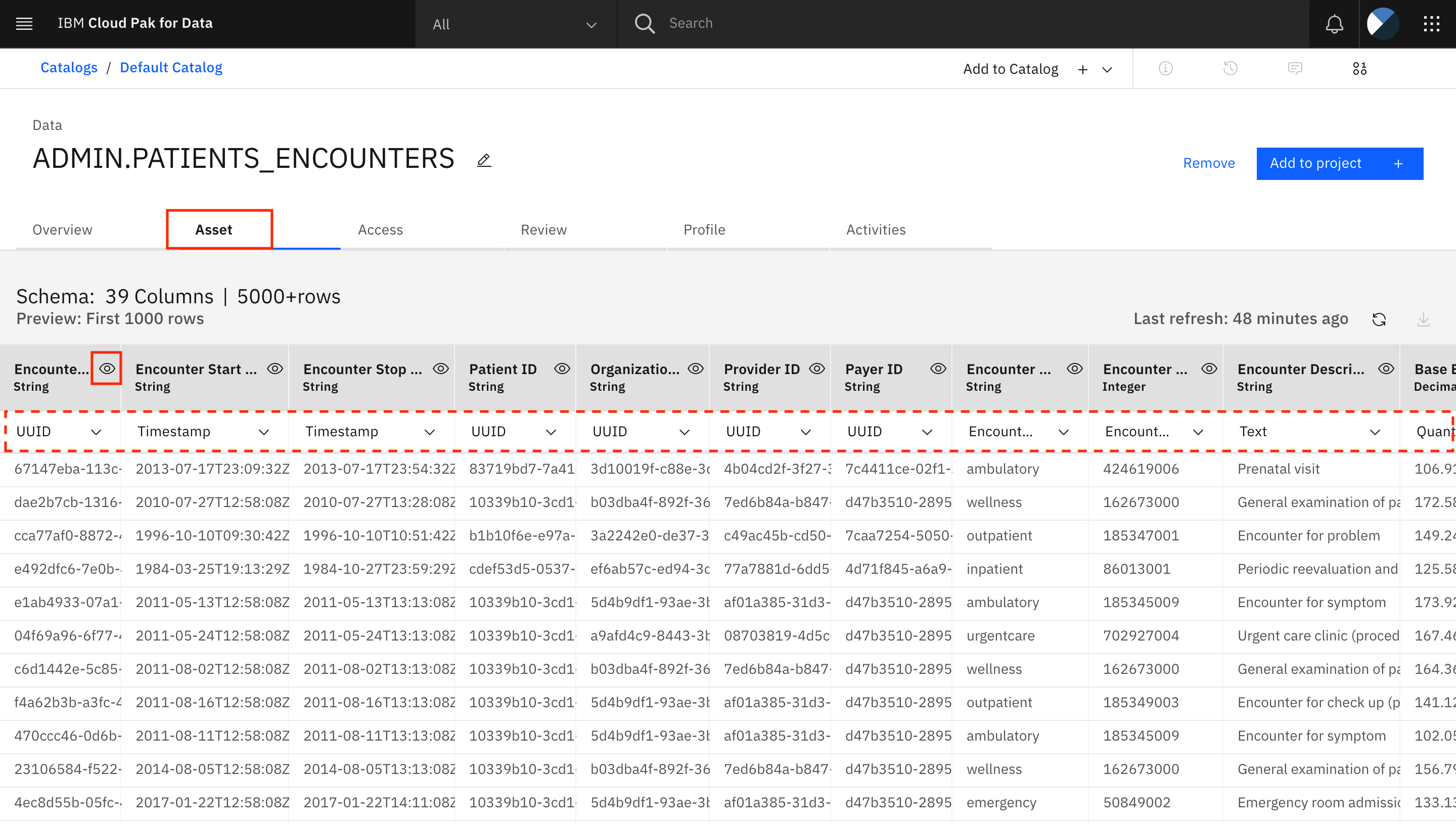
Go to the Asset tab. You can see the updated data classes under each column. You can now update the business terms for the columns. For the first column, Encounter ID, click the eye icon next to the column name.
In the dialog, click the pencil icon next to Business terms.
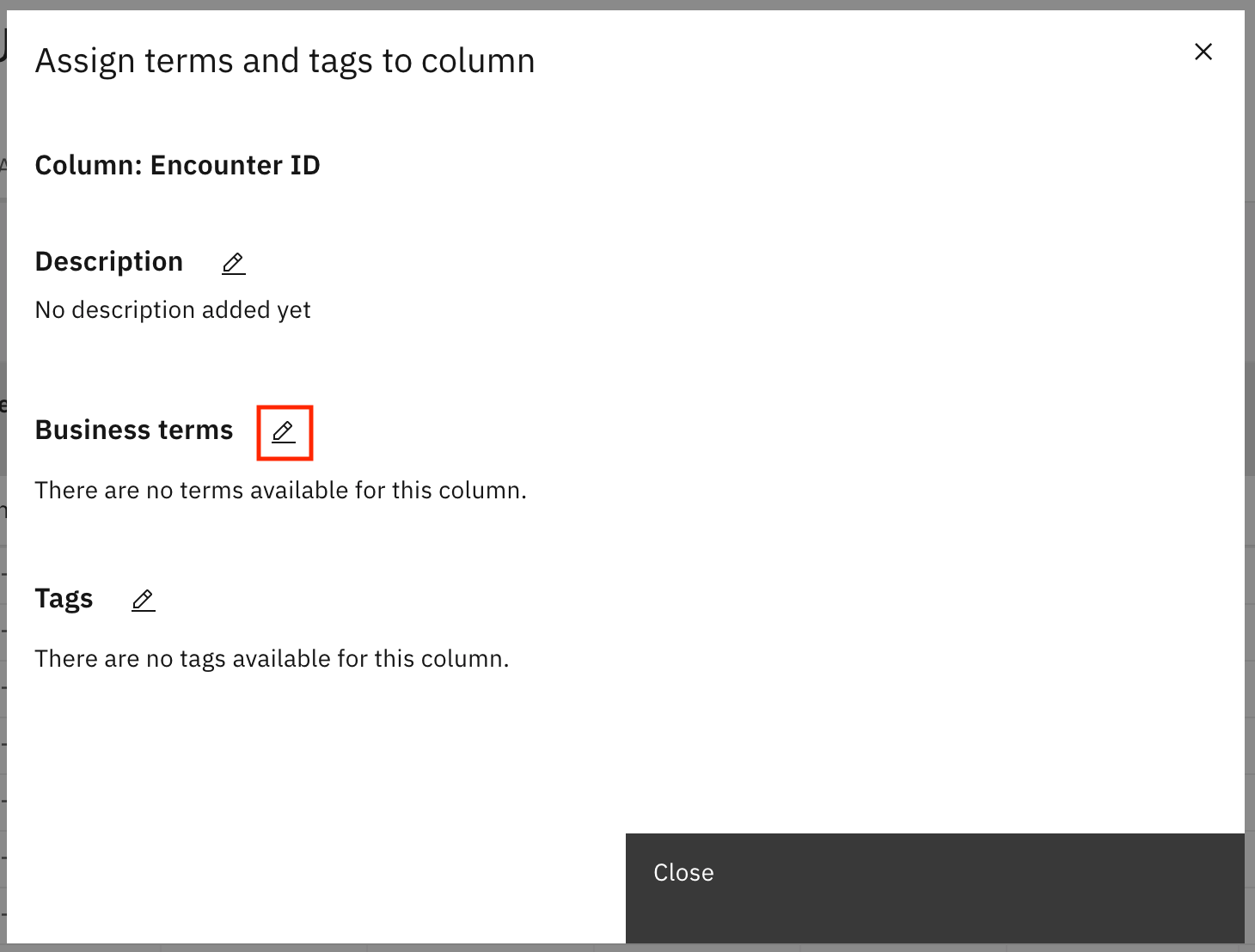
Search for and select the
Encounter IDbusiness term. Click Apply, then Close. The business term for the Encounter ID column are updated.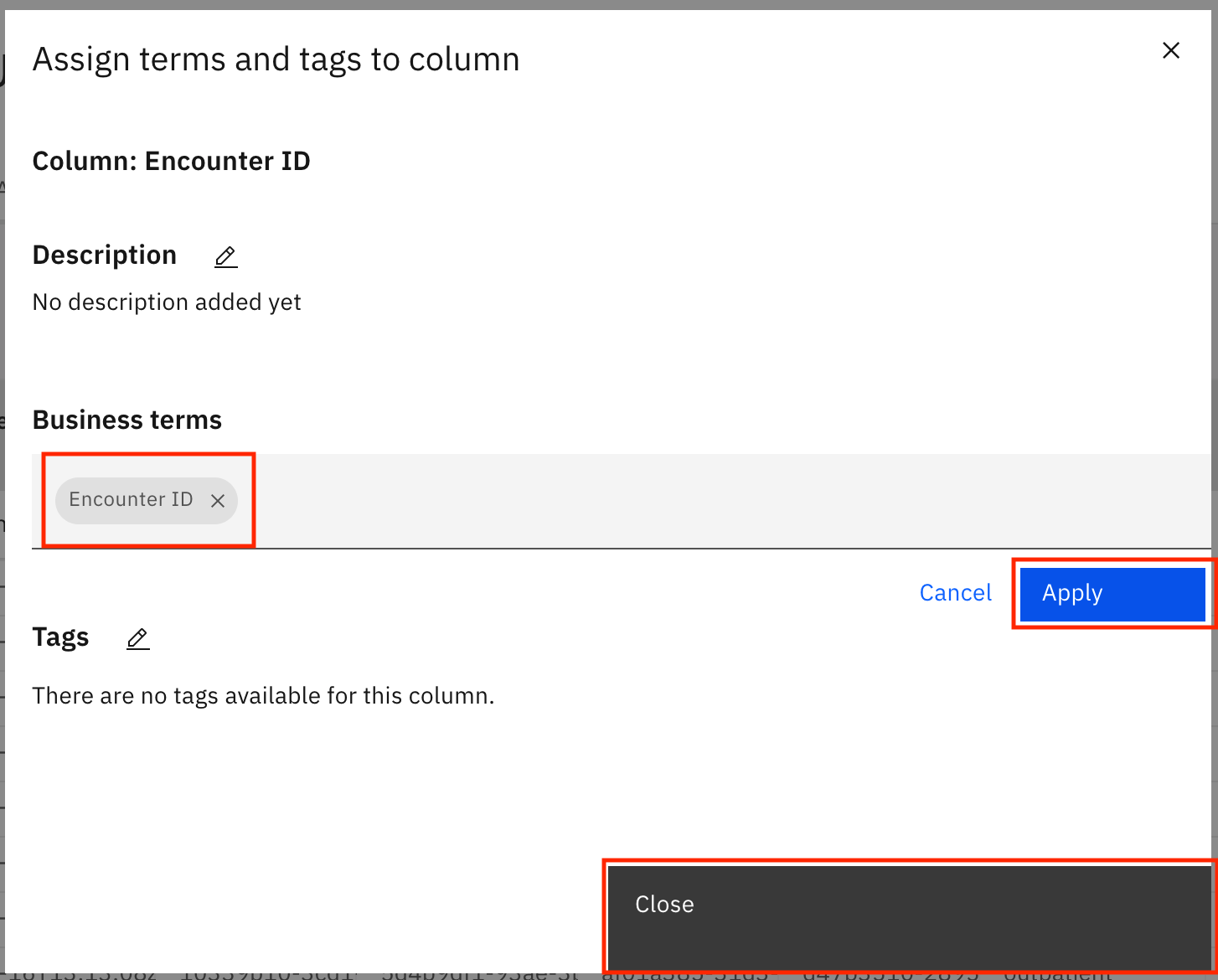
Repeat the process to update the business terms for all of the other columns in the asset. You can refer to the Data Asset Annotations file to obtain the business terms for the columns in this asset. Remember to use the business terms assigned to the columns in the PATIENTS and ENCOUNTERS tables because the
PATIENTS_ENCOUNTERSview was created by joining these two tables.
Step 6. Users view and assign the virtualized data to a project
Next, you can log in as the users to verify what data they can see and how they can add the virtualized data to their projects.
Log into IBM Cloud Pak for Data as a non-admin user
Log out of IBM Cloud Pak for Data, and log back in as
regular_user.
Create analytics project
Go to the Navigation Menu menu, expand Projects, and click All projects.
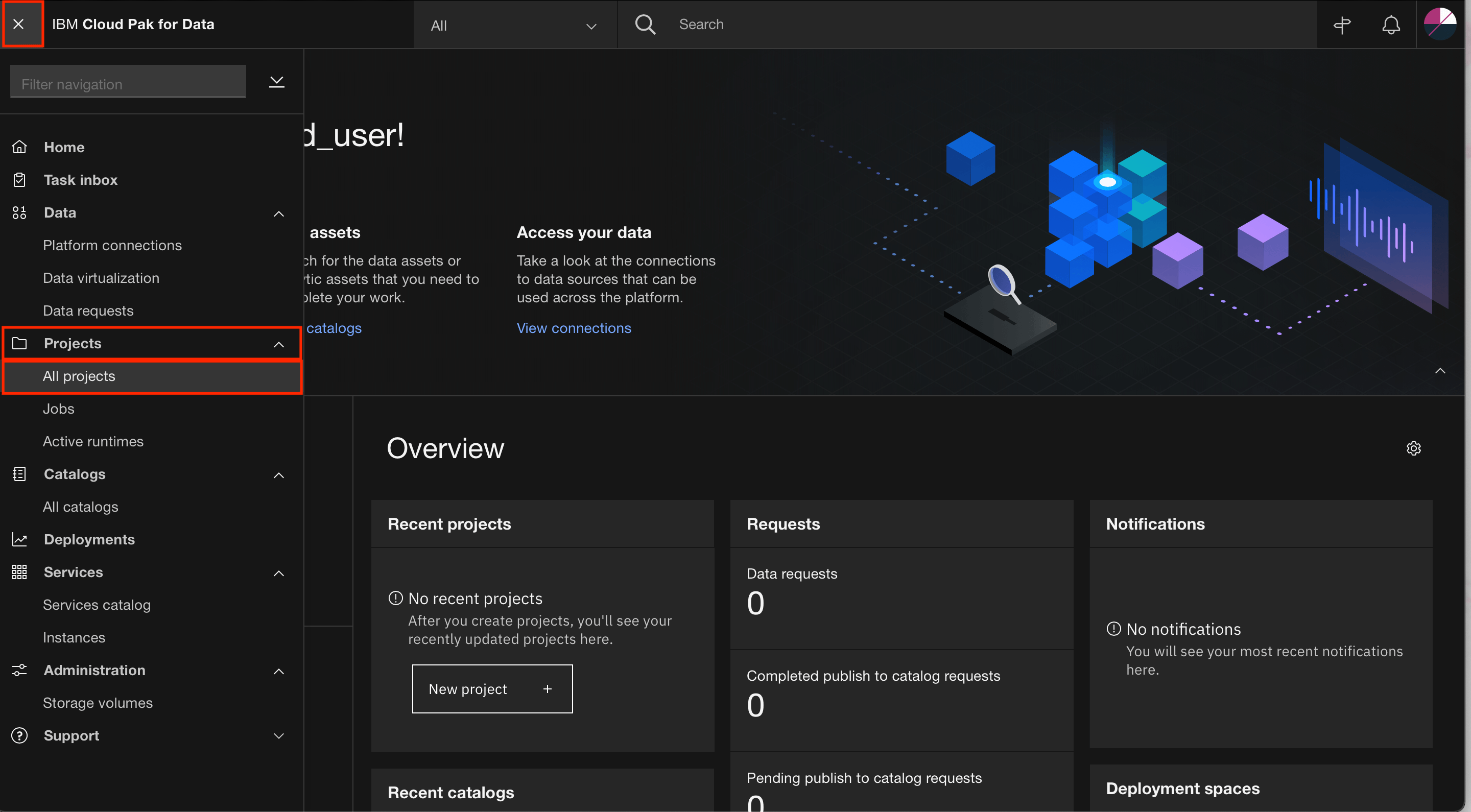
Click New project +. In the dialog, select Analytics project, then click Next.
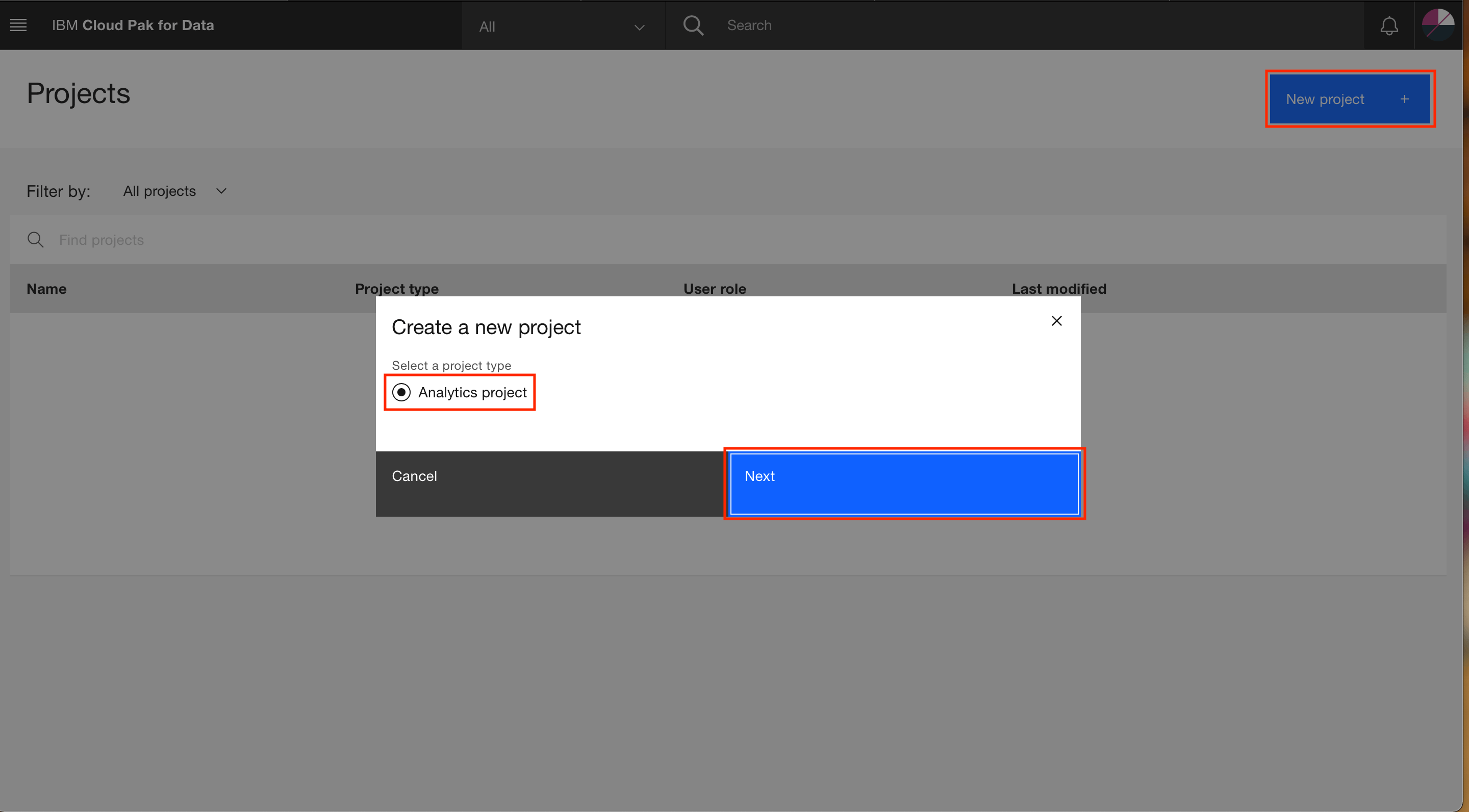
Click the tile for Create an empty project.

Provide a name (
Healthcare Project) and an optional description (Healthcare project created by regular user) for the project, and click Create.
Assign the published data to a project
Go to the Navigation Menu, expand Catalogs, and click All catalogs.
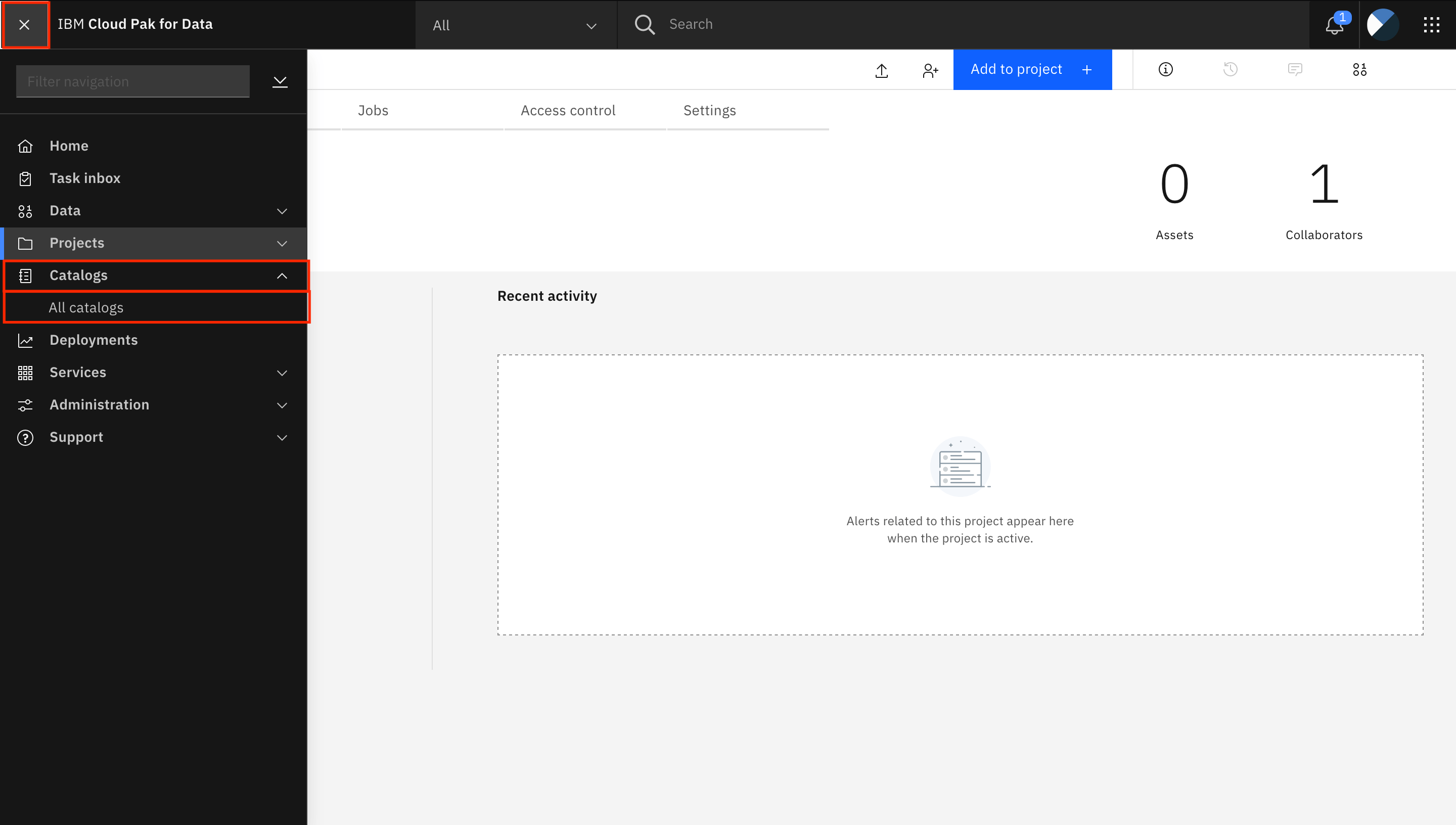
Click the tile for the Default Catalog.
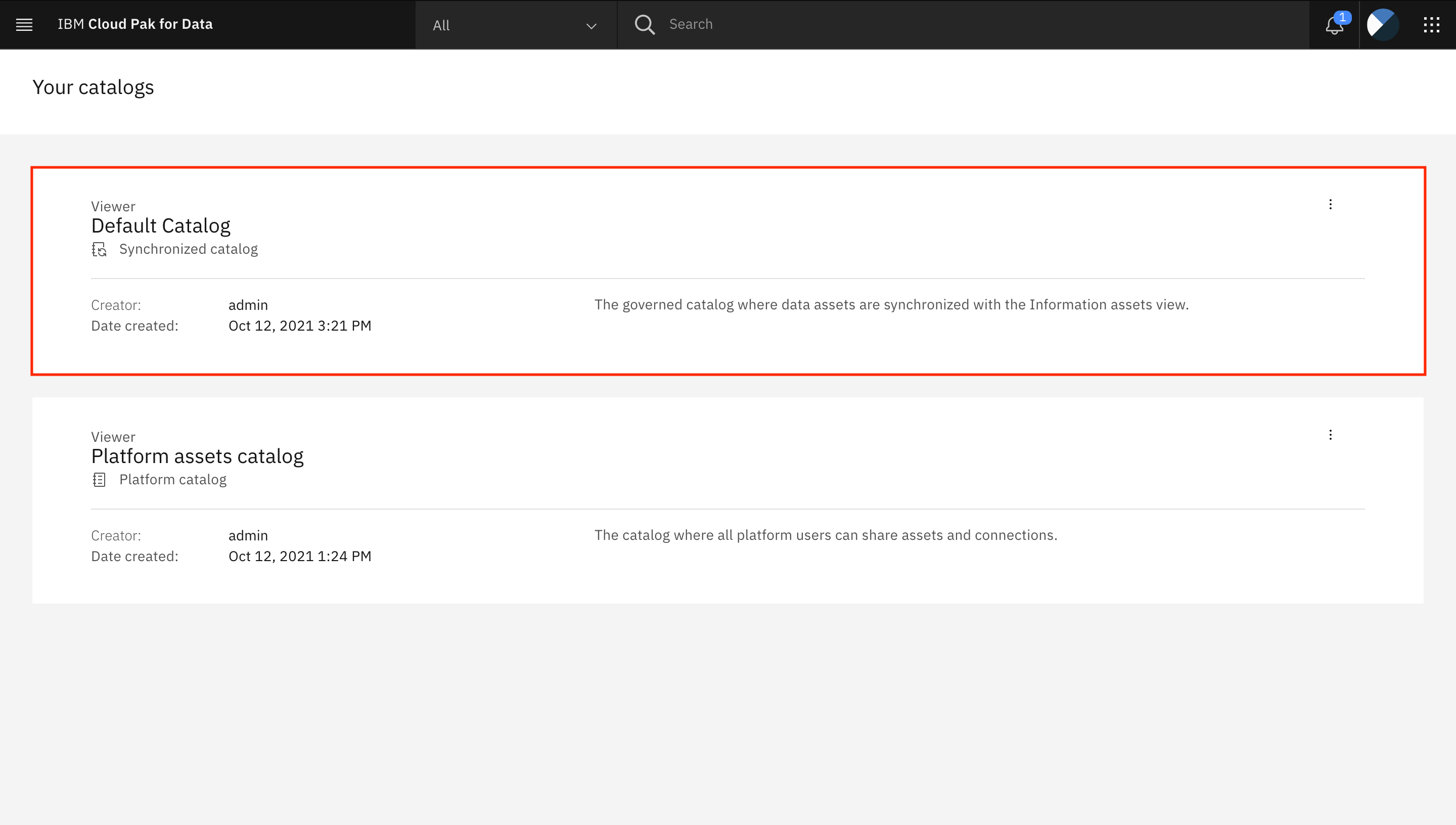
Scroll to and click the name of the
ADMIN.PATIENTS_ENCOUNTERSasset.Go to the Asset tab. You might be asked to enter your credentials to unlock the Watson Query asset. Provide your username (
regular_user) and password, and click Connect.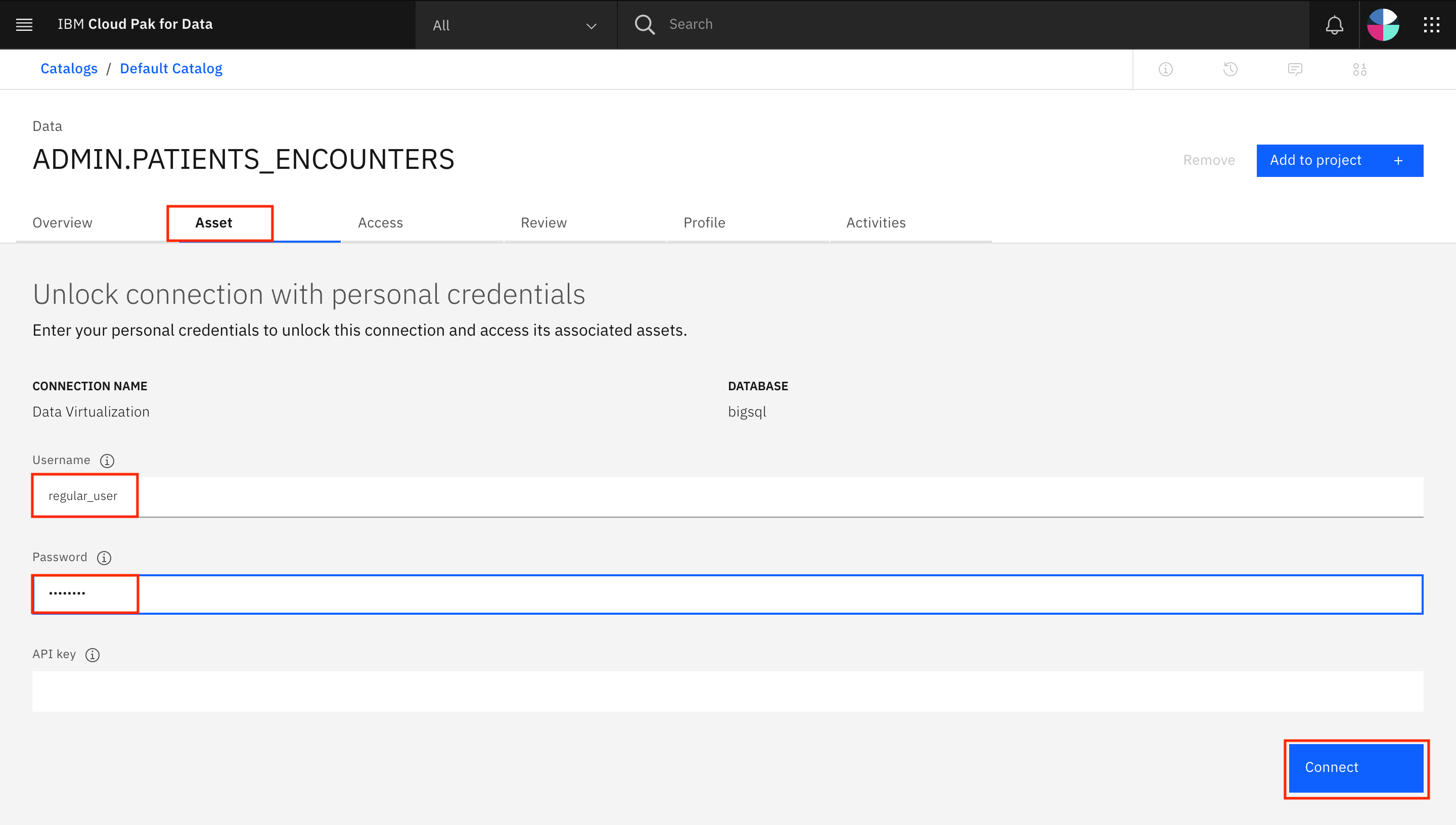
It might take a while for the data masking process to complete, and you might have to refresh the page. After the asset loads, you are able to see the data classes that have been assigned for each column. For example, the first column Encounter ID has the data class of
UUID. Click the eye icon next to the Encounter ID column name. A new window opens, and you can see that the Encounter ID business term has been assigned to this column. Click Close to close the window.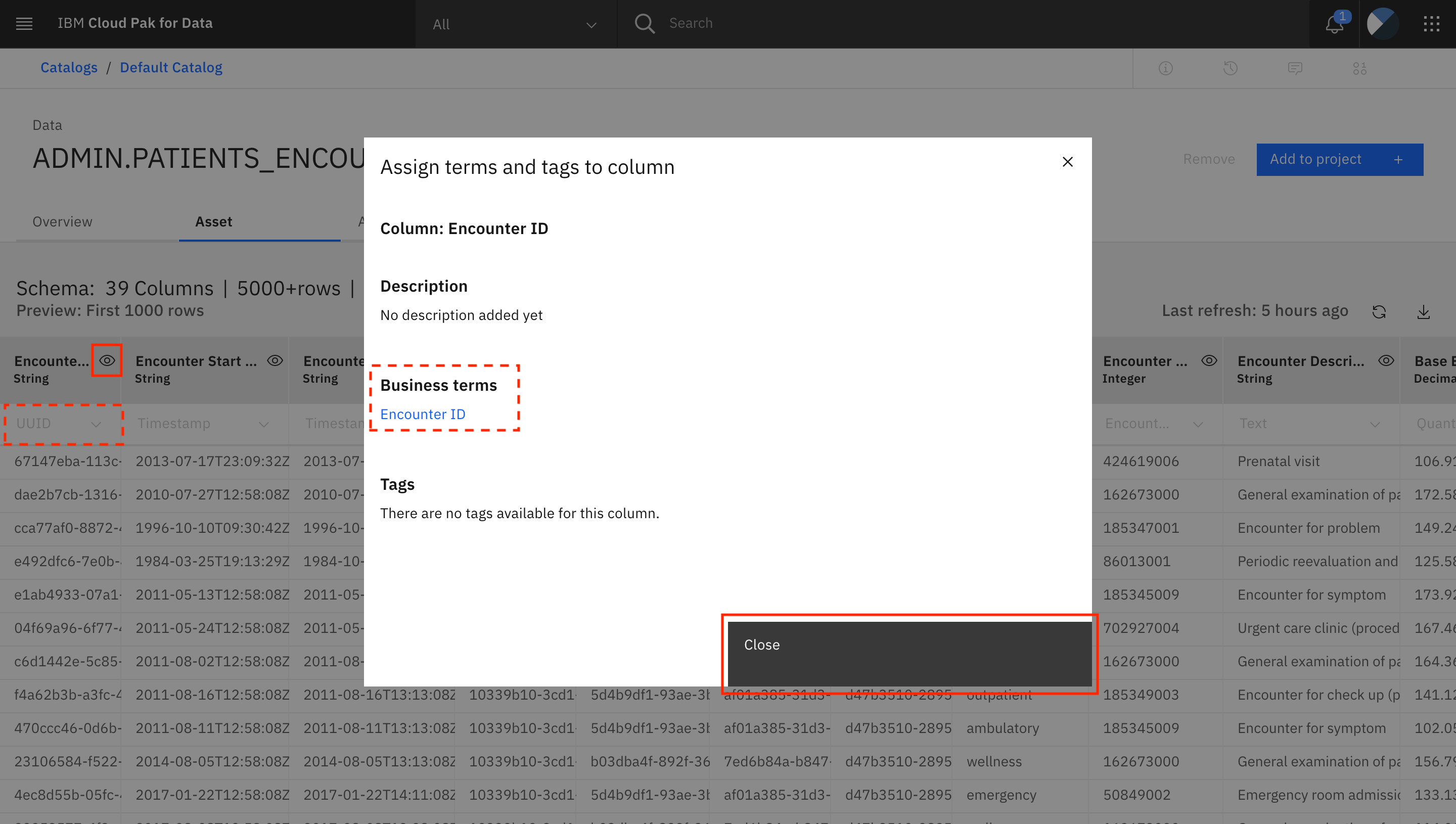
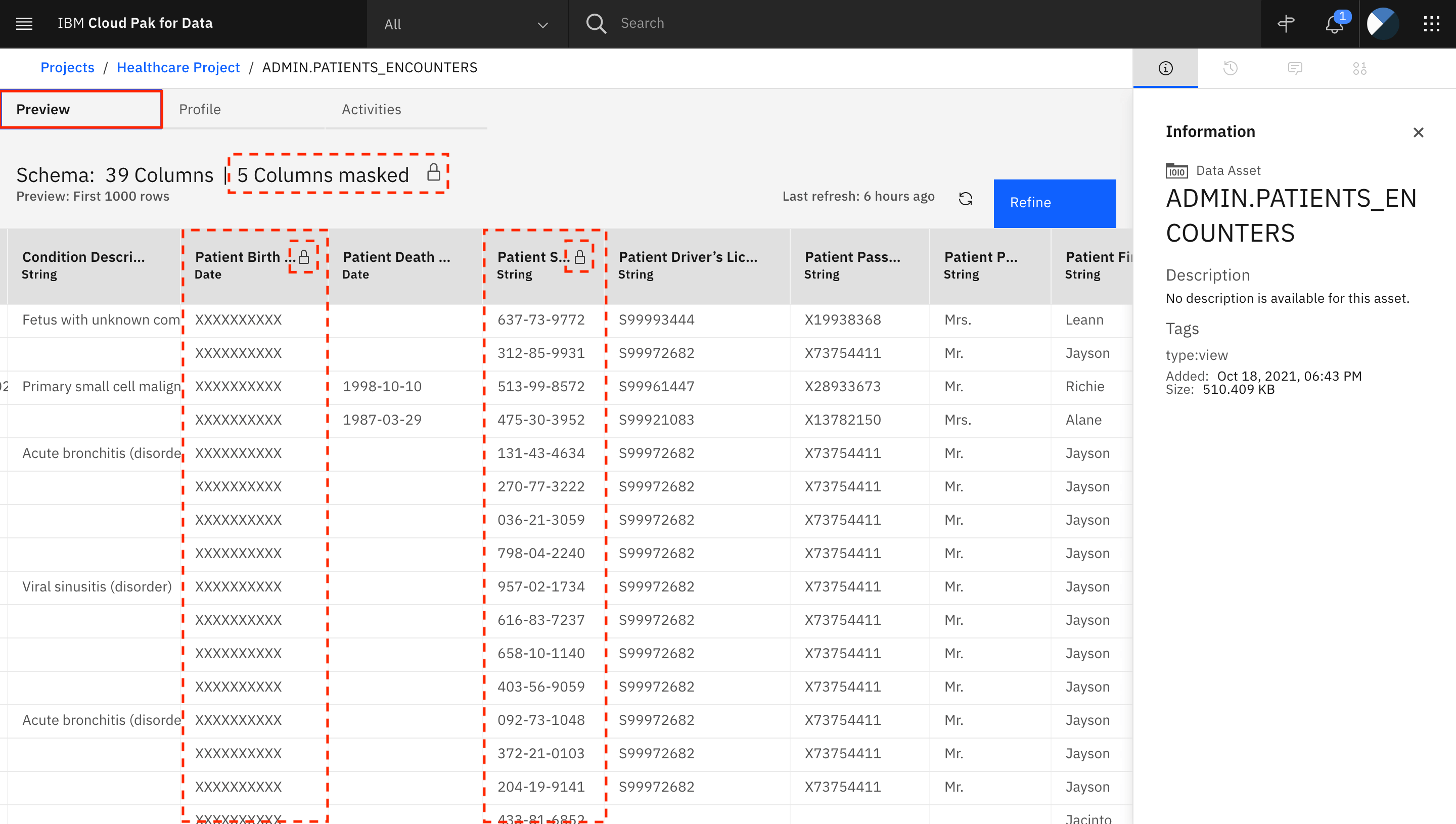
Notice that five colums in the view are masked. Click the Lock icon to learn how many columns were masked by using the different masking techniques.
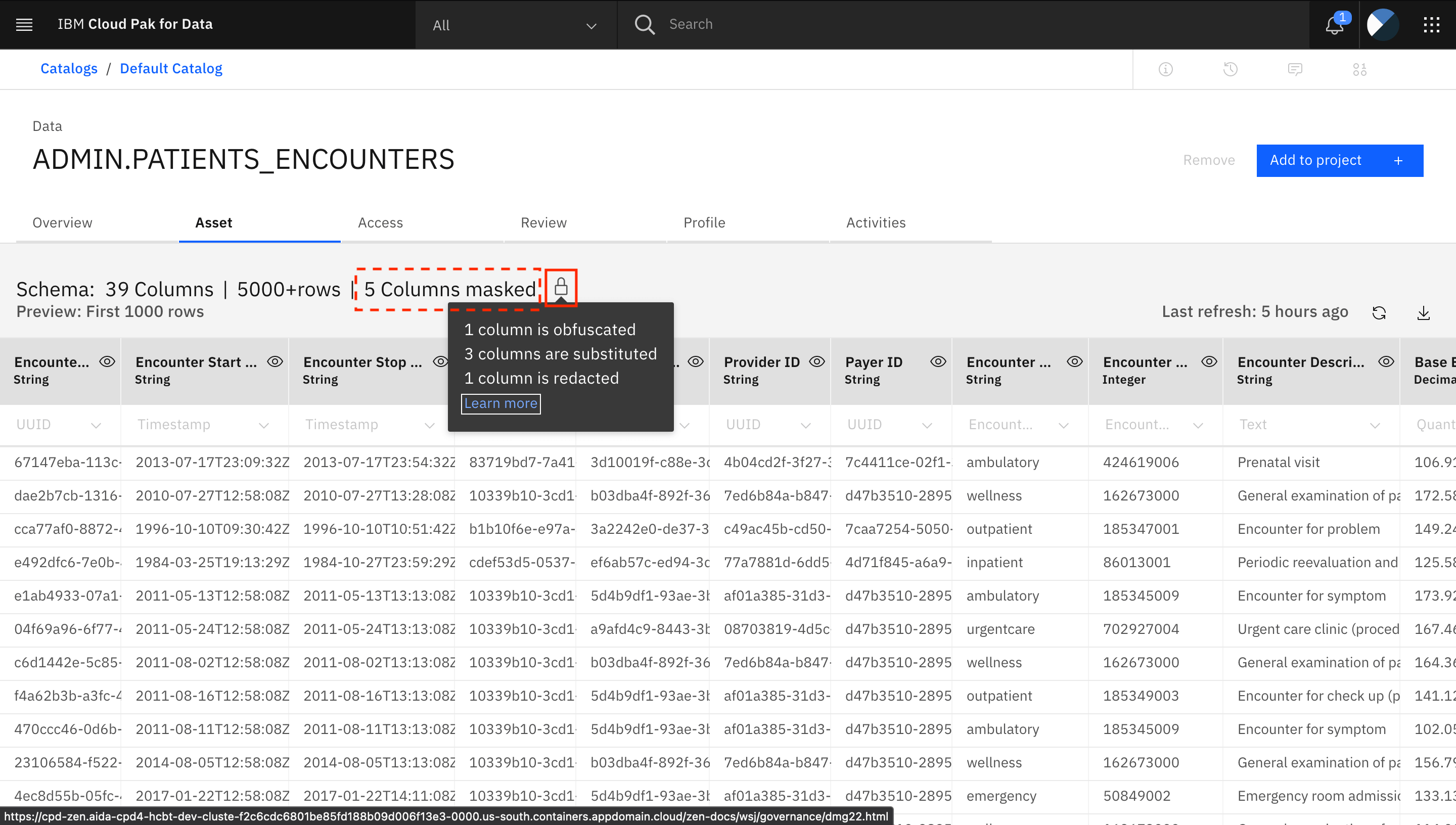
The columns that are masked are Patient Birth Date, Patient SSN, Patient Race, Patient Ethnicity, and Patient Gender. All masked columns have a Lock icon next to the column name. Click the Lock icon to access more information about why the column was masked.
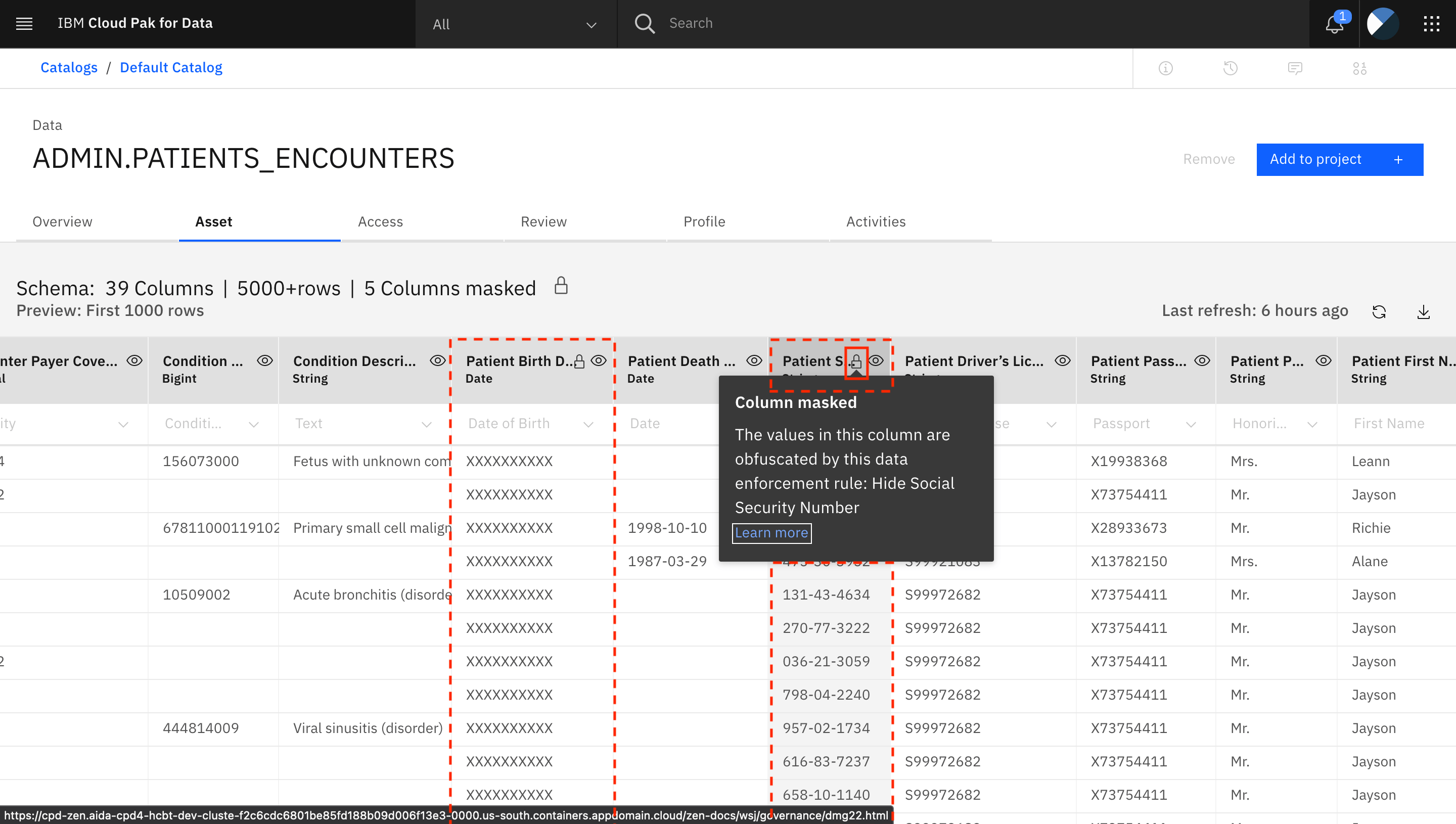
The columns are being masked due to the data protection rules that were previously set up.
To add this data to your analytics project, click Add to project +.
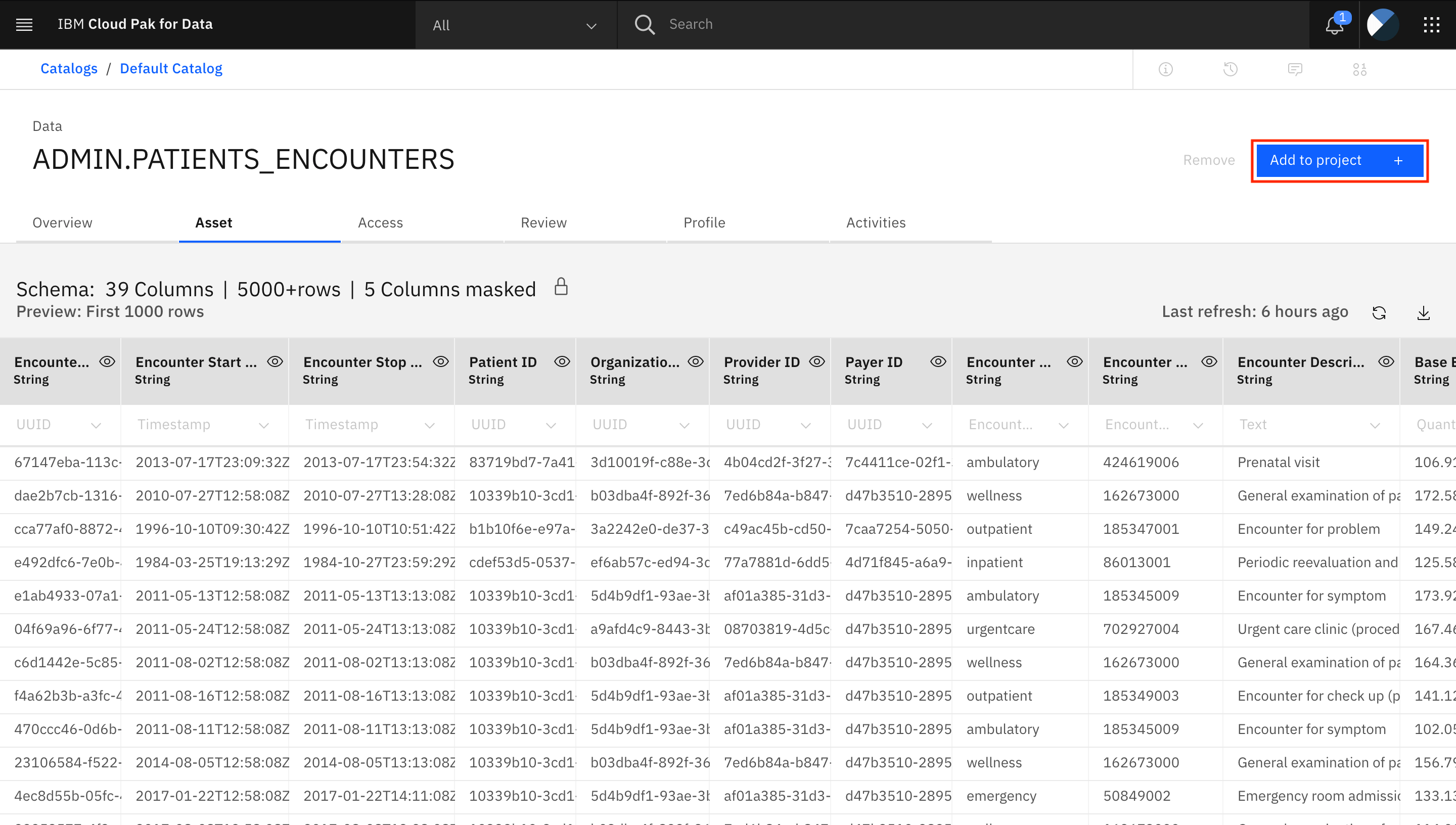
Within the Target section, select your project Healthcare Project, and click Add.
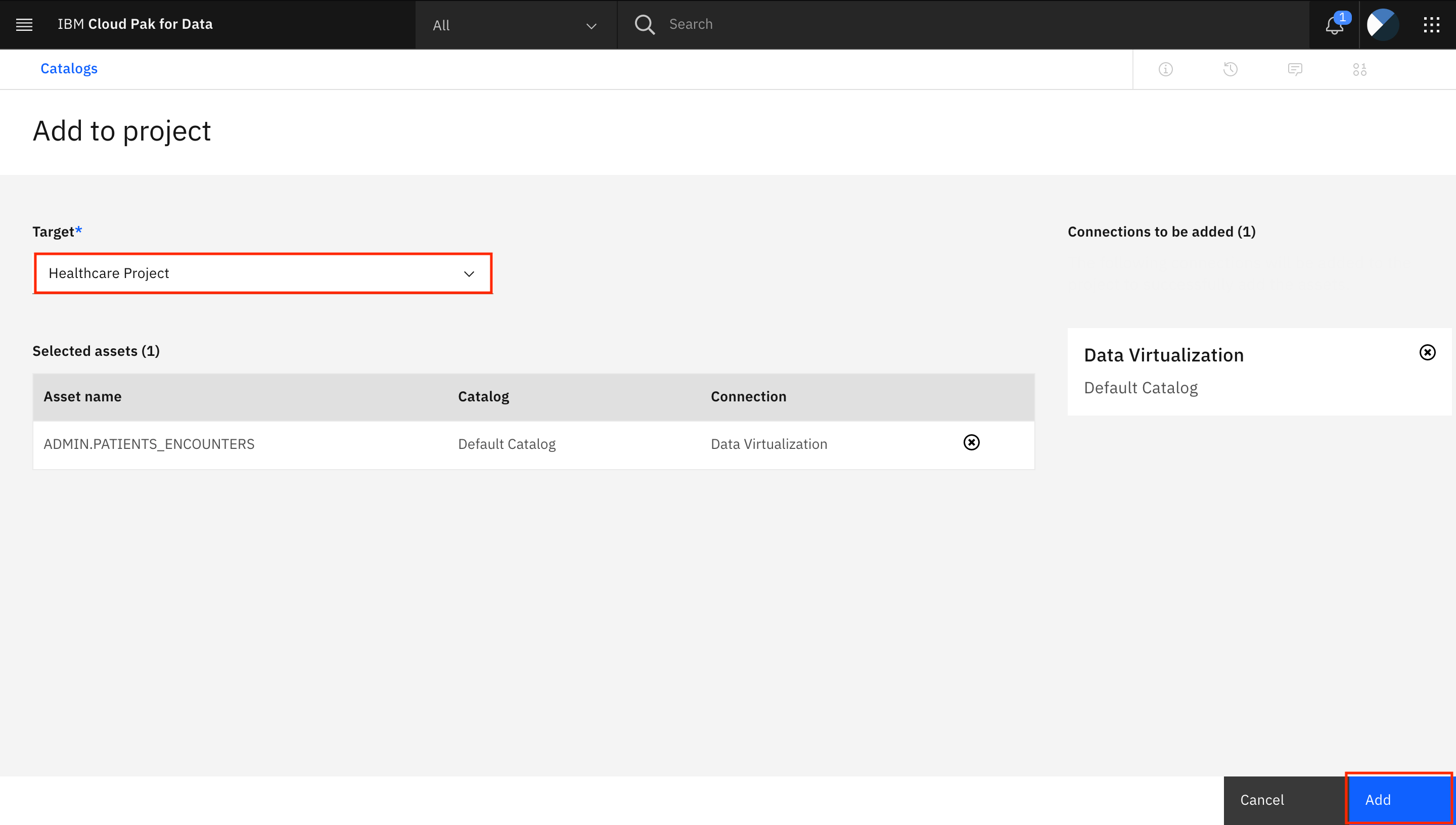
A notification appears that says two assets were successfully added to the project. Click Go to project.
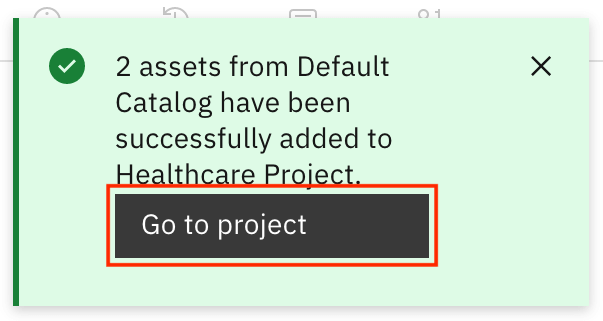
Go to the Assets tab. You see two entries: one for the Data Virtualization connection and another for the
ADMIN.PATIENTS_ENCOUNTERSasset. Click theADMIN.PATIENTS_ENCOUNTERSasset.
Use your
regular_username and its password if you are asked to enter the credentials to unlock the Data Virtualization connection, and click Connect.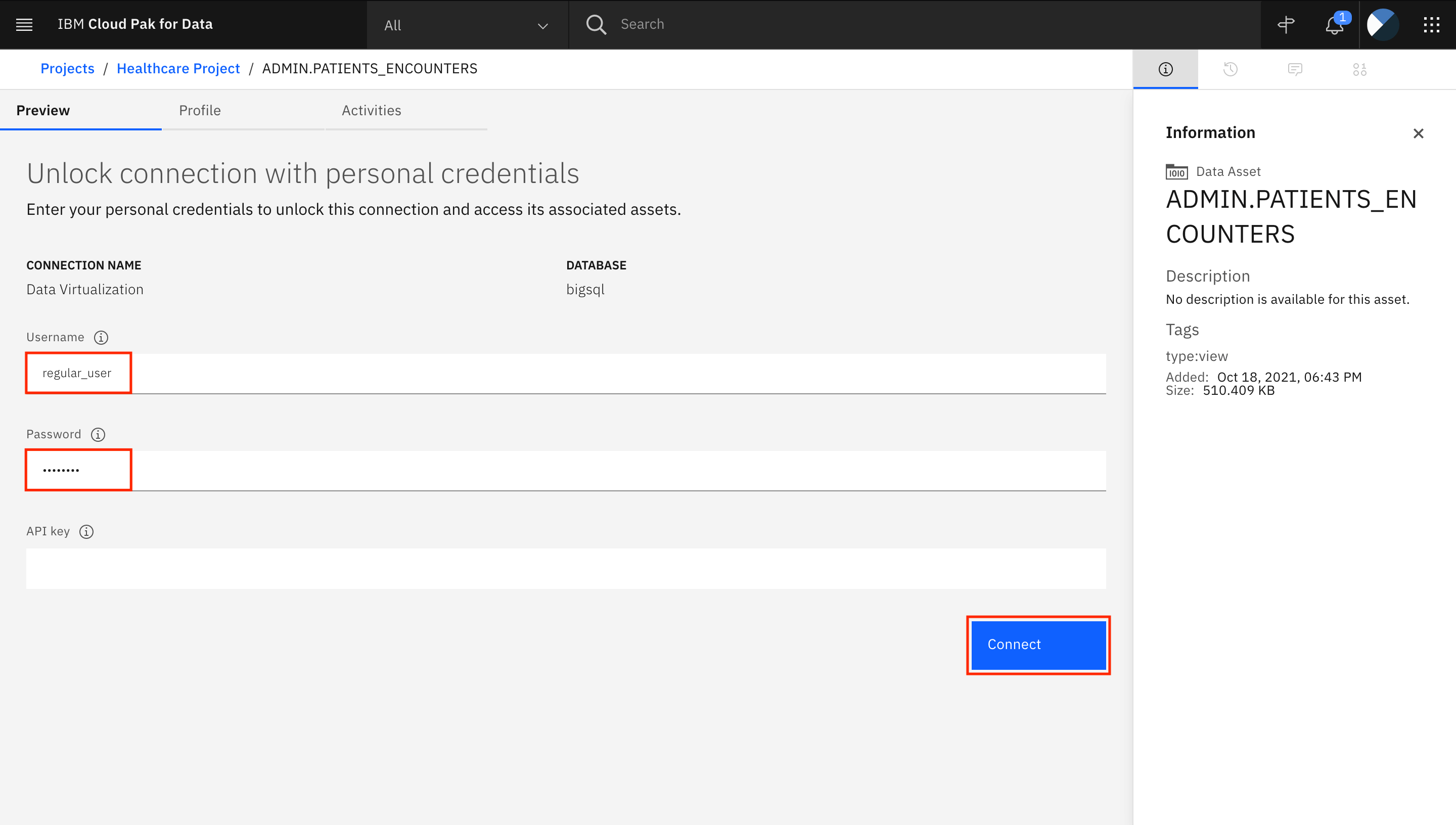
On the Preview tab of the asset, you are able to preview the data. You see that the data masking that was performed in the catalog is propagated to the asset in the project, and the asset is protected in the same manner if any other operations such as Data Refinement are performed on it.
Log out of IBM Cloud Pak for Data, and log back in as the
restricted_user. If you attempt to perform the previous steps to go to the Default Catalog and access the published virtual viewADMIN.PATIENTS_ENCOUNTERS, you see an error. This is due to another data protection rule that prevents therestricted_userfrom accessing any data asset that has a column with the data class Passport or a column with the business term Patient Driver's License.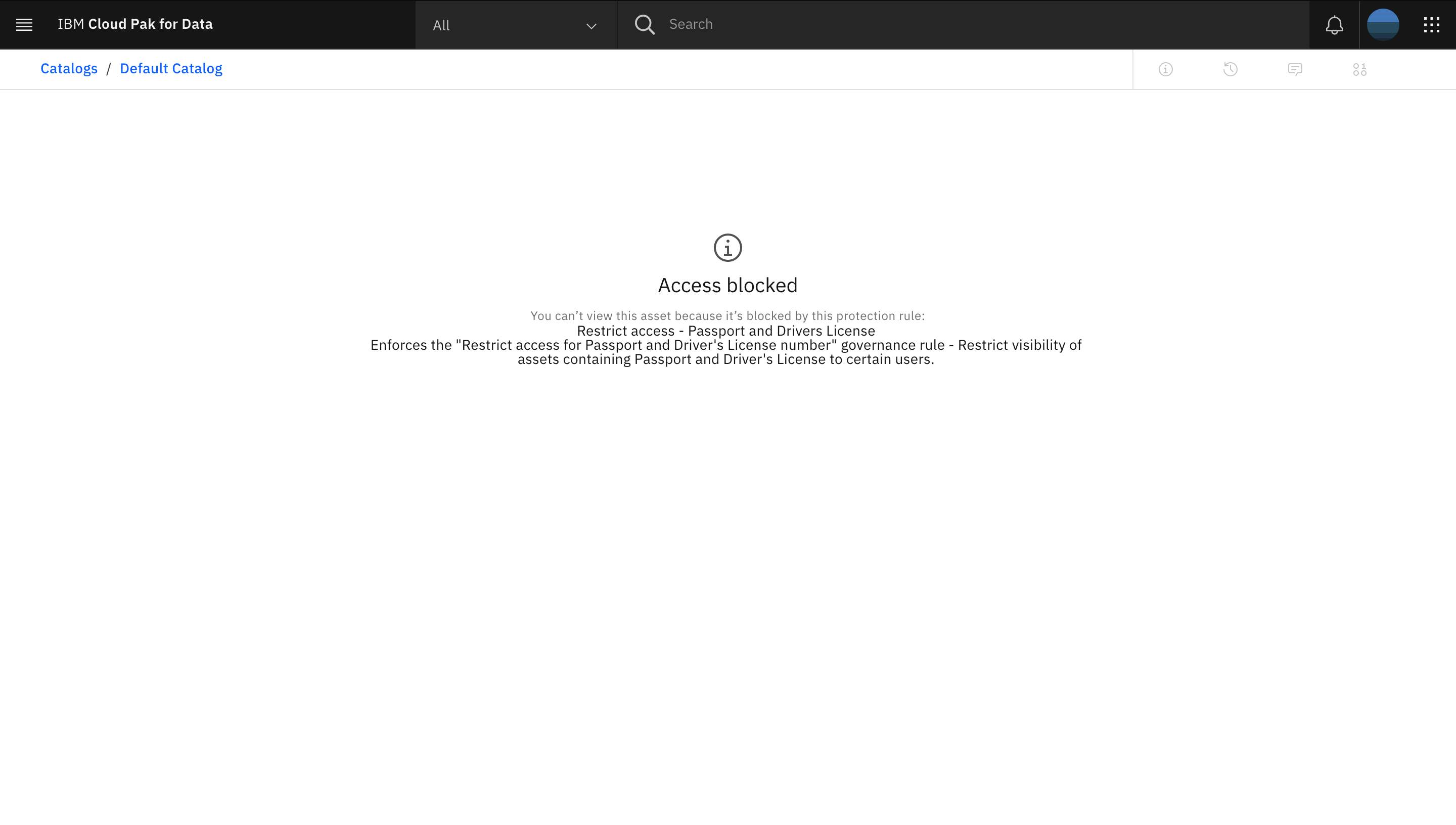
Summary
In this tutorial, you learned to use Watson Query on IBM Cloud Pak for Data to virtualize data that has been protected using data protection rules within Watson Knowledge Catalog on IBM Cloud Pak for Data. You saw how column names of the virtualized data can be replaced with the previously assigned business terms, thereby ensuring that the data column names are standardized as per the enterprise policies. You learned how to join virtualized data to create a virtual view and how to update the data classes and business terms for the newly created virtual view. This ensured that the data protection rules that were defined earlier are enforced. You verified that the data protection rules are enforced by logging in as other non-admin users to access and assign the virtual view to a project. This ensured that while the real data is not visible to users, they can use the columns that exist and based on the type of data masking used, they can also get an idea about the formats or table references of those columns.
This tutorial is part of the An introduction to the DataOps discipline series.