Tutorial
Getting started with PySpark
Learn to use PySpark for processing structured data and machine learning modelingApache Spark is a fast and powerful framework that provides an API to perform massive distributed processing over resilient sets of data. The main abstraction Spark provides is a resilient distributed data set (RDD), which is the fundamental and backbone data type of this engine. Spark SQL is Apache Spark's module for working with structured data and MLlib is Apache Spark's scalable machine learning library. Apache Spark is written in Scala programming language. To support Python with Spark, the Apache Spark community released a tool, PySpark. PySpark has similar computation speed and power as Scala. PySpark is a parallel and distributed engine for running big data applications. Using PySpark, you can work with RDDs in Python programming language.
This tutorial explains how to set up and run Jupyter Notebooks from within IBM Watson Studio. We'll use two different data sets: 5000_points.txt and people.csv. The data set has a corresponding Notebook.
Learning objectives
In this tutorial, you will learn how to:
- Perform Big Data analysis with PySpark
- Use SQL queries with DataFrames by using Spark SQL module
- Use Machine learning with MLlib library
Prerequisites
To complete the tutorial, you need an IBM Cloud account.
Estimated time
It should take you approximately 60 minutes to complete this tutorial.
Steps
Step 1. Create IBM Cloud Object Storage service
An Object Storage service is required to create projects in Watson Studio. If you do not already have a storage service provisioned, complete the following steps:
From your IBM Cloud account, search for “object storage” in the IBM Cloud Catalog. Then, click the Object Storage tile.
Choose Lite plan and Click Create button.
Step 2. Create Watson Studio service
From your IBM Cloud account, search for “Watson Studio” in the IBM Cloud Catalog. Then, click the Watson Studio tile.
Choose Lite plan and Click Create button.
Step 3. Create Watson Studio project
- Click Get Started.
- Click either Create a project or New project.
Select Create an empty project.
In the New project window, name the project (for example, “Getting Started with PySpark”).
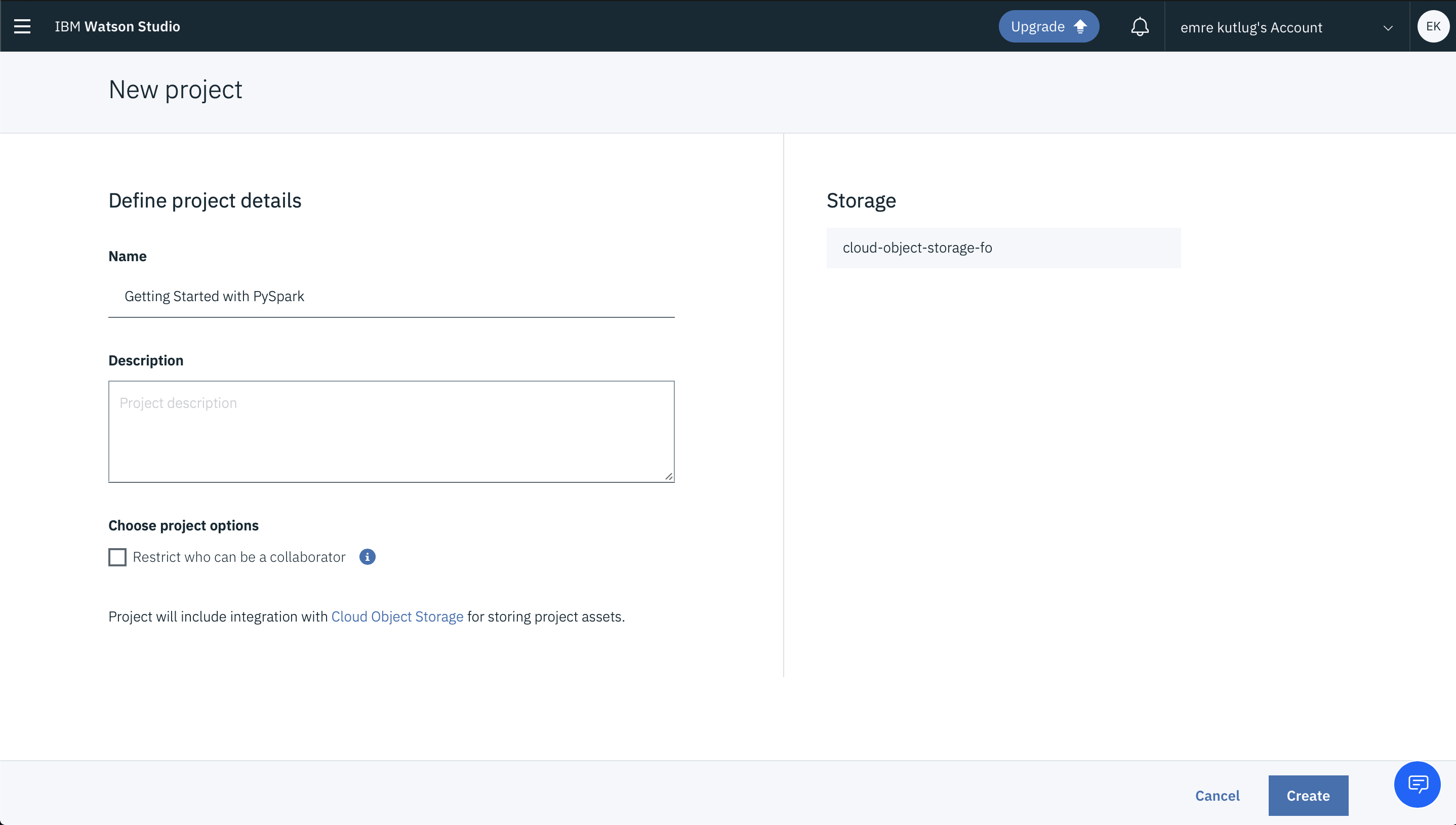
For Storage, you should select the IBM Cloud Object Storage service you created in the previous step. If it is the only storage service that you have provisioned, it is assigned automatically.
Click Create
Step 4. Upload data set
Next, you’ll download the data set and upload it to Watson Studio.
Select the data sets: 5000_points.txt and people.csv and download the files to your local desktop.
In Watson Studio, select Assets.
If not already open, click the 1001 data icon at the upper right of the panel to open the Files sub-panel. Then, click Load.
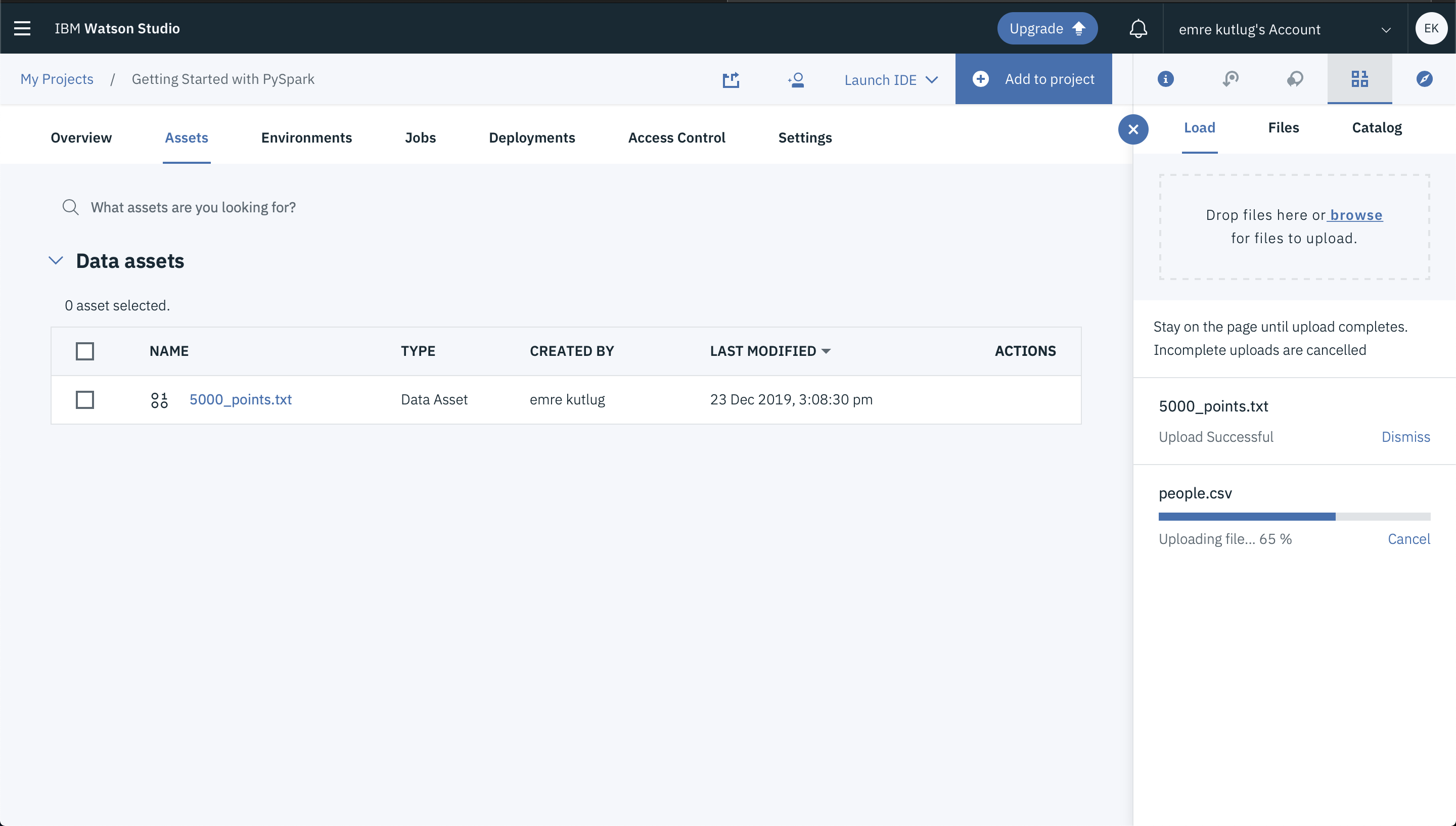
Drag the files to the drop area or browse for files to upload the data into Watson Studio.
- Wait until the file has been uploaded.
Step 5. Create the notebook
Create a Jupyter Notebook and change it to use the data set that you have uploaded to the project.
In the Asset tab, click Add to Project.
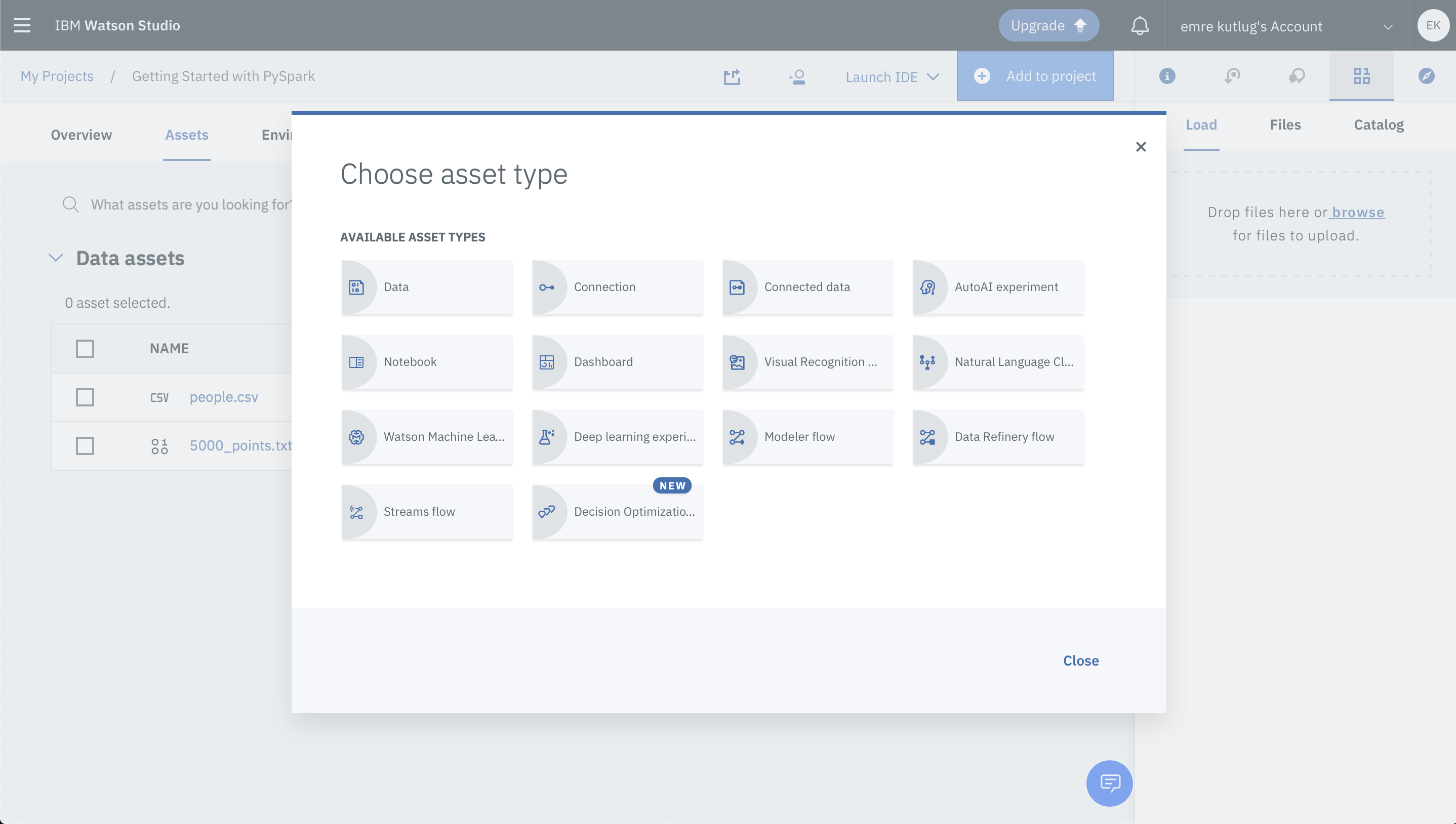
Select the Notebook asset type.
On the New Notebook page, configure the notebook as follows:
Select the From URL tab:
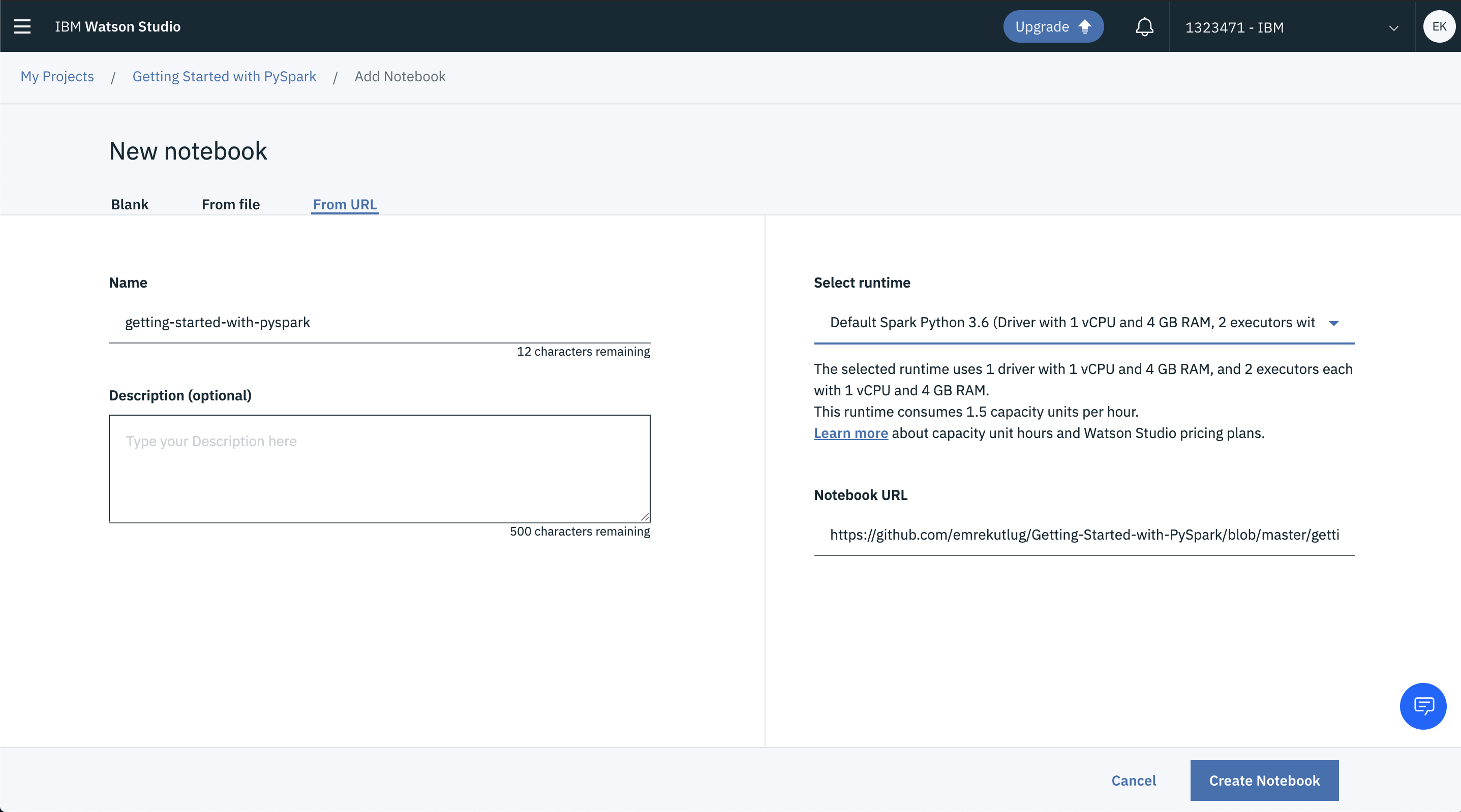
Enter the name for the notebook (for example, ‘getting-started-with-pyspark’).
Select the Spark Python 3.6 runtime system.
Enter the following URL for the notebook:
static/getting_started_with_pyspark.ipynbClick Create Notebook. This initiates the loading and running of the notebook within IBM Watson Studio.
Run the notebook
The notebook page should be displayed.
If the notebook is not currently open, you can start it by clicking the Edit icon displayed next to the notebook in the Asset page for the project.

What is SparkContext?
Spark comes with an interactive python shell that has PySpark already installed. PySpark automatically creates a SparkContext for you in the PySpark Shell. SparkContext is an entry point into the world of Spark. An entry point is a way of connecting to Spark cluster. We can use SparkContext using sc.variable. In the following examples, we retrieve SparkContext version and Python version of SparkContext.

Using map and filter methods with Lambda function in Python
Lambda functions are anonymous functions in Python. Anonymous functions do not bind to any name in runtime, and it returns the functions without any name. They are usually used with map and filter methods. Lambda functions create functions to be called later. In the following example, we use lambda function with map and filter methods.

Creating RDD from Object
RDDs are data stacks distributed throughout a cluster of computers. Each stack is calculated on different computers in the cluster. RDDs are the most basic data structure of Spark. We can create RDDs by giving existing objects like Python lists to SparkContext's parallelize method. In the following example, we create a list with numbers and create a RDD from this list.

Transformations and actions on RDD
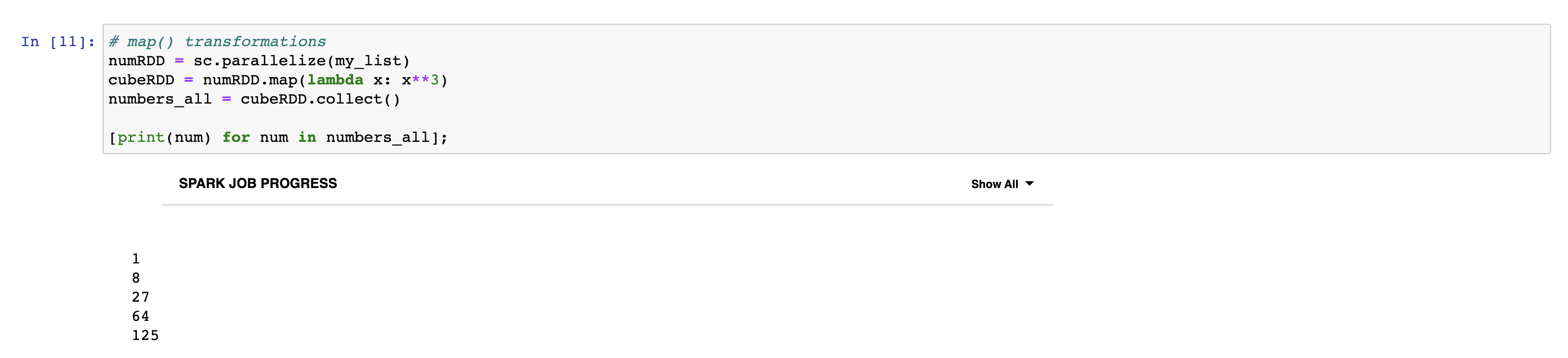
Transformations and actions are two type of operations in Spark. Transformations create new RDDs. Actions performs computation on the RDDs. Map, filter, flatMap and union are basic RDD transformations. Collect, take, first and count are basic RDD actions. In the following example, we create RDD named numRDD from list and then using map transformation we create a new RDD named cubeRDD from numRDD. Finally, we use collect action to return a list that contains all of the elements in this RDD.
Transformations and actions on pair RDD
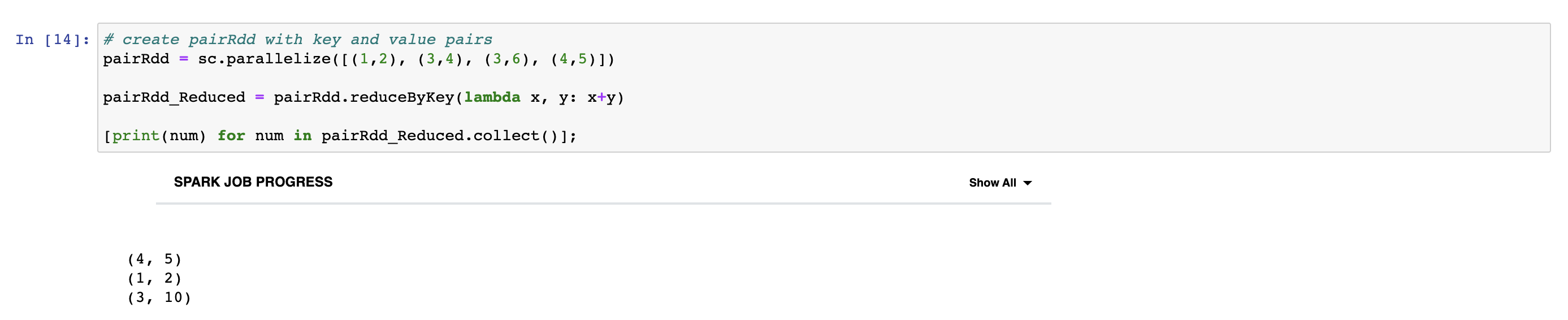
Pair RDD is a special type of RDD to work with data sets with key/value pairs. All regular transformations work on pair RDD. In the following example, we create pair RDD with 4 tuple with two numbers. In each tuple, the first number is key and the second number is value. Then, we apply reduceByKey transformation to pair RDD. ReduceByKey transformation combine values with the same key. Therefore, this transformation adds the values of tuples with the same key.
We can sort keys of tuples using sortByKey transformation like in the following example.

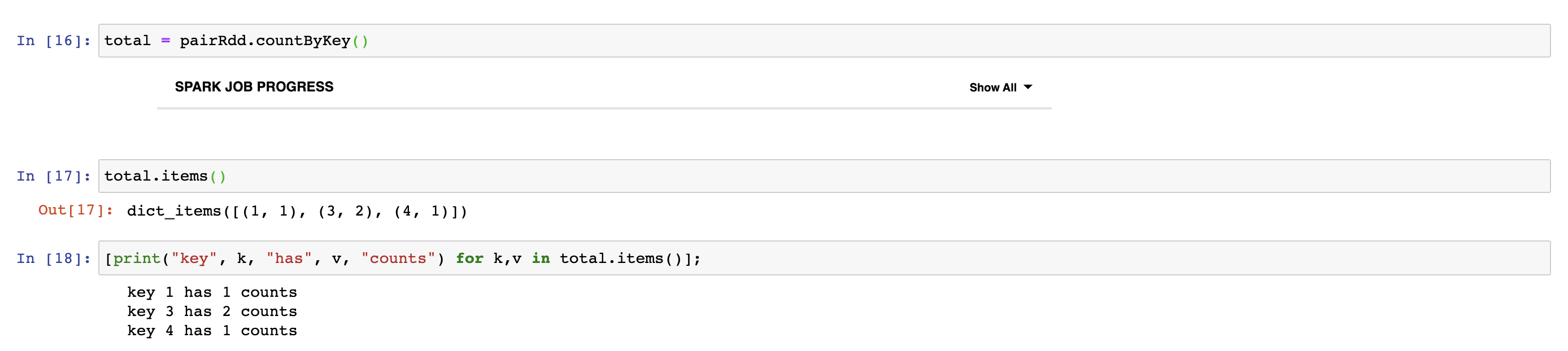
We can count the number of tuples with the same key. In the following example, we see (3,2) because there are two tuple with key 3 in pair RDD.
What is SparkSession?
SparkContext is the main entry point for creating RDDs while SparkSession provides a single point of entry to interact with Spark DataFrames. SparkSession is used to create DataFrame, register DataFrames, execute SQL queries. We can access SparkSession in PySpark using spark variable. In the following examples, we retrieve SparkSession version and other informations about it.

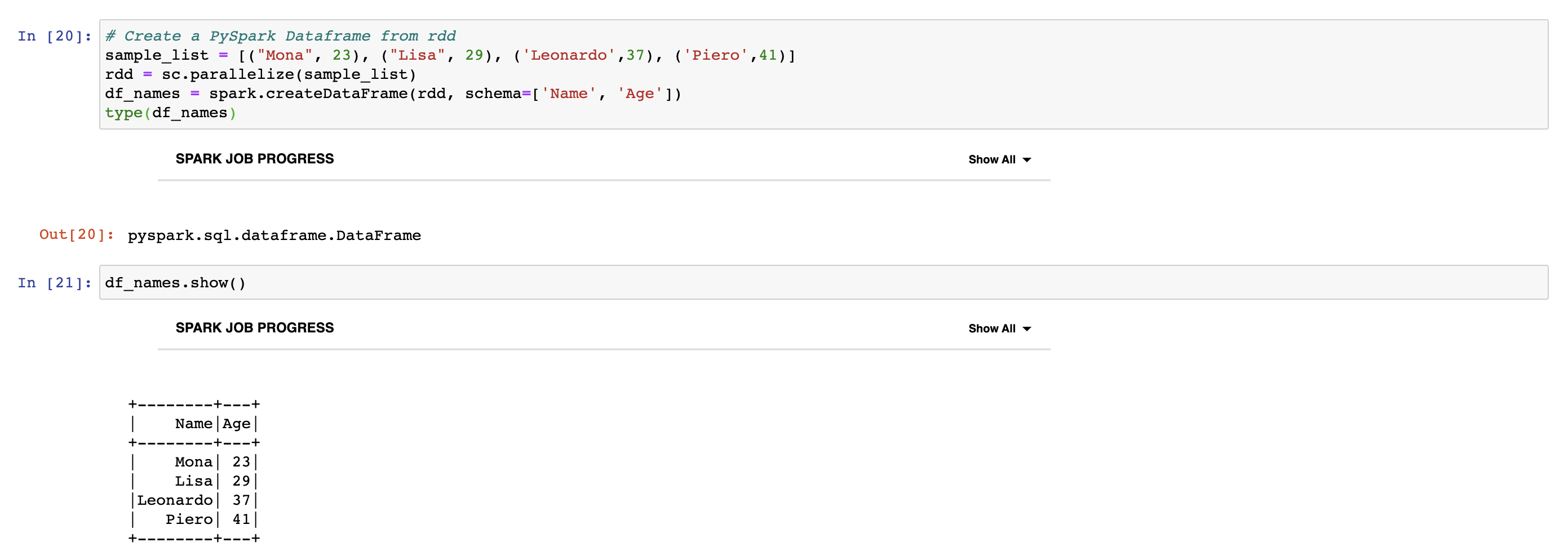
Creating PySpark DataFrame from RDD
Spark SQL, which is a Spark module for structured data processing, provides a programming abstraction called DataFrames and can also act as a distributed SQL query engine. In the following example, we create RDD from list and create PySpark DataFrame using SparkSession's createDataFrame method. When we look at the type of DataFrame, we can see pyspark.sql.dataframe as an output. Furthermore, we can use show method to print out the DataFrame.
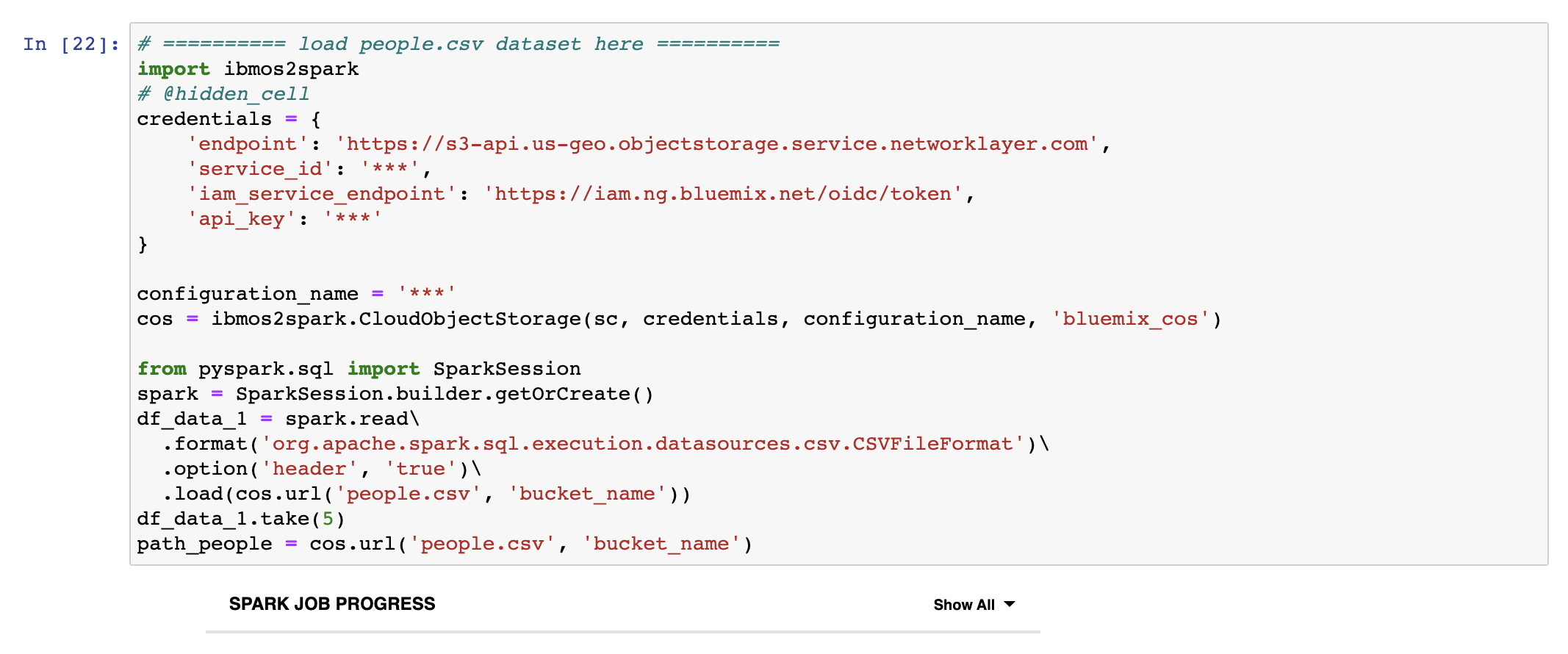
Add data sets
We can use external data sets in the notebook to do this select the cell below. If not already open, click the 1001 data icon at the upper part of the page to open the Files subpanel. In the right part of the page, select the people.csv data set. Click insert to code, and click Insert SparkSession DataFrame.

You can delete df_data_1.take(5) part and then copy cos.url('file_name', 'bucket_name') above it then assign cos.url('file_name', 'bucket_name') to path_people variable and comment out this variable. cos.url('file_name', 'bucket_name') is path to your file you can access the file by using this path.
You can also add 5000_points.txt data set by applying same procedure but click insert to code then click insert credentials then write "file" and "bucket" values inside "path_5000 = cos.url('file_name', 'bucket_name')" expression and comment out path_5000.

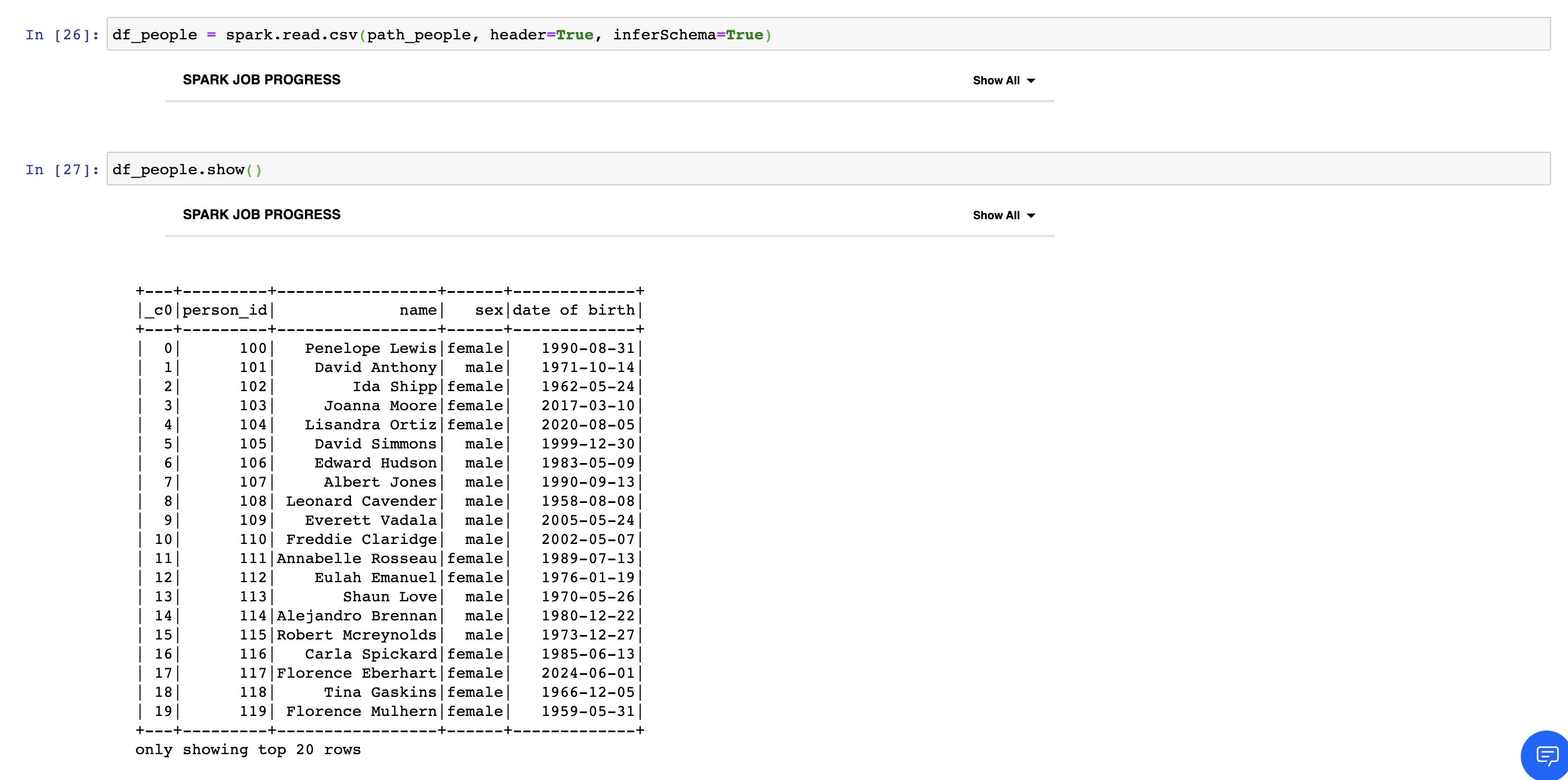
Create PySpark DataFrame from external file
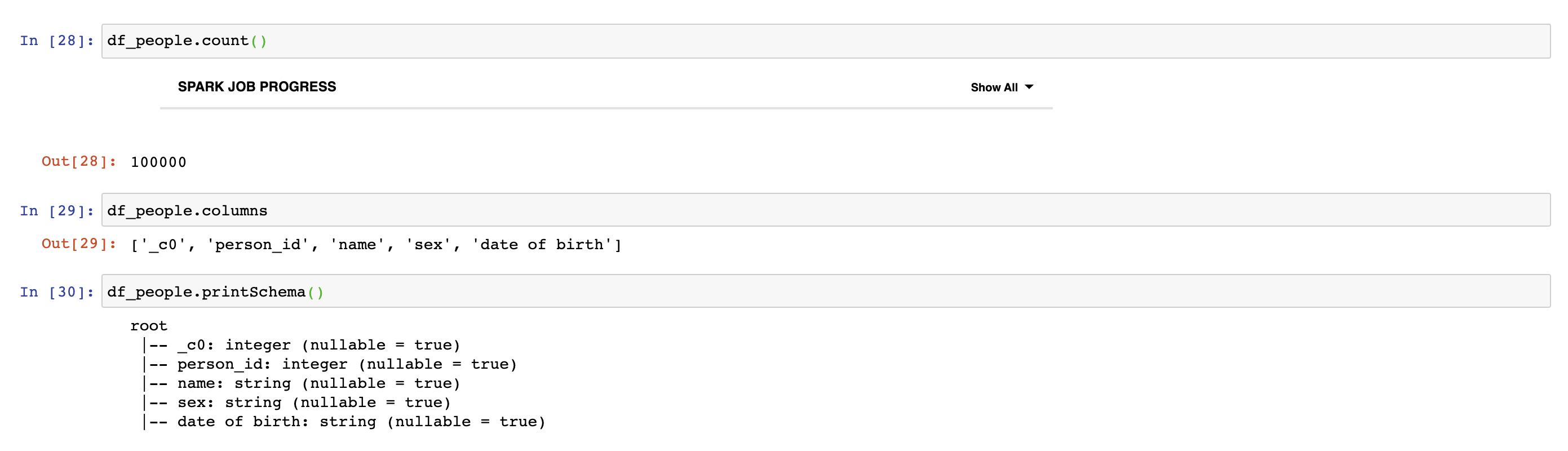
We can create PySpark DataFrame by using SparkSession's read.csv method. To do this, we should give path of csv file as an argument to the method. Show action prints first 20 rows of DataFrame. Count action prints number of rows in DataFrame. Columns attribute prints the list of columns in DataFrame. PrintSchema action prints the types of columns in the DataFrame and tells you if there are null values in columns.
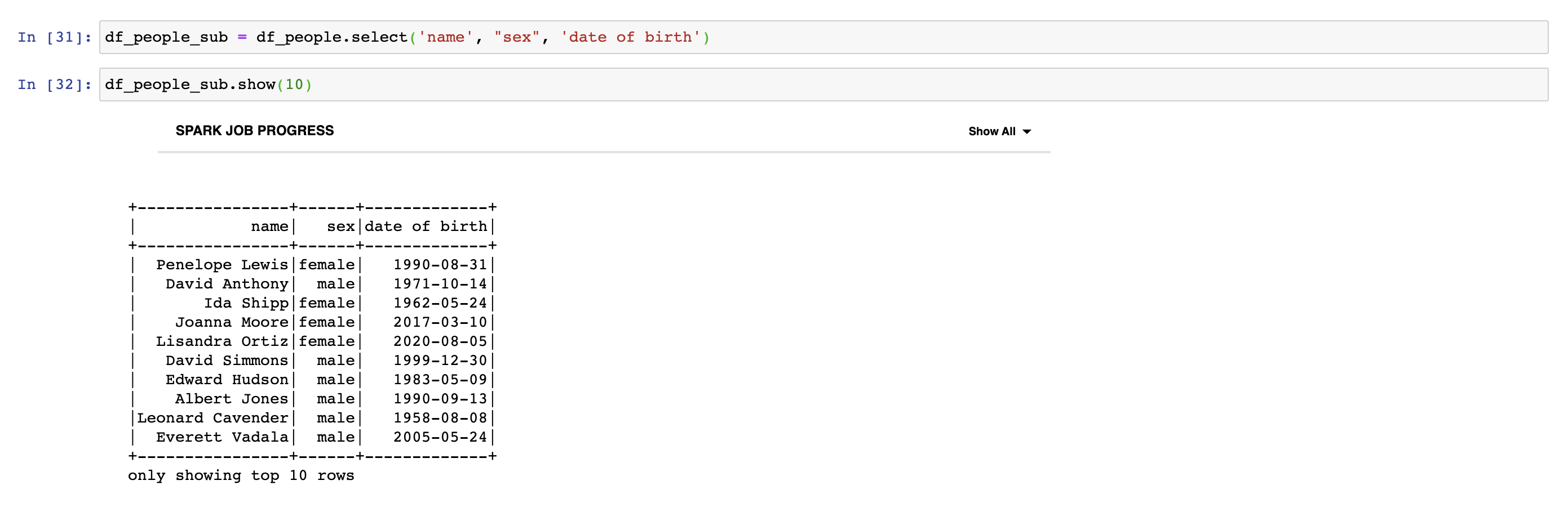
We can use select method to select some columns of DataFrame. If we give an argument to show method, it prints out rows as the number of arguments. In the following example, it prints out 10 rows. dropDuplicates method removes the duplicate rows of a DataFrame. We can use count action to see how many rows are dropped.

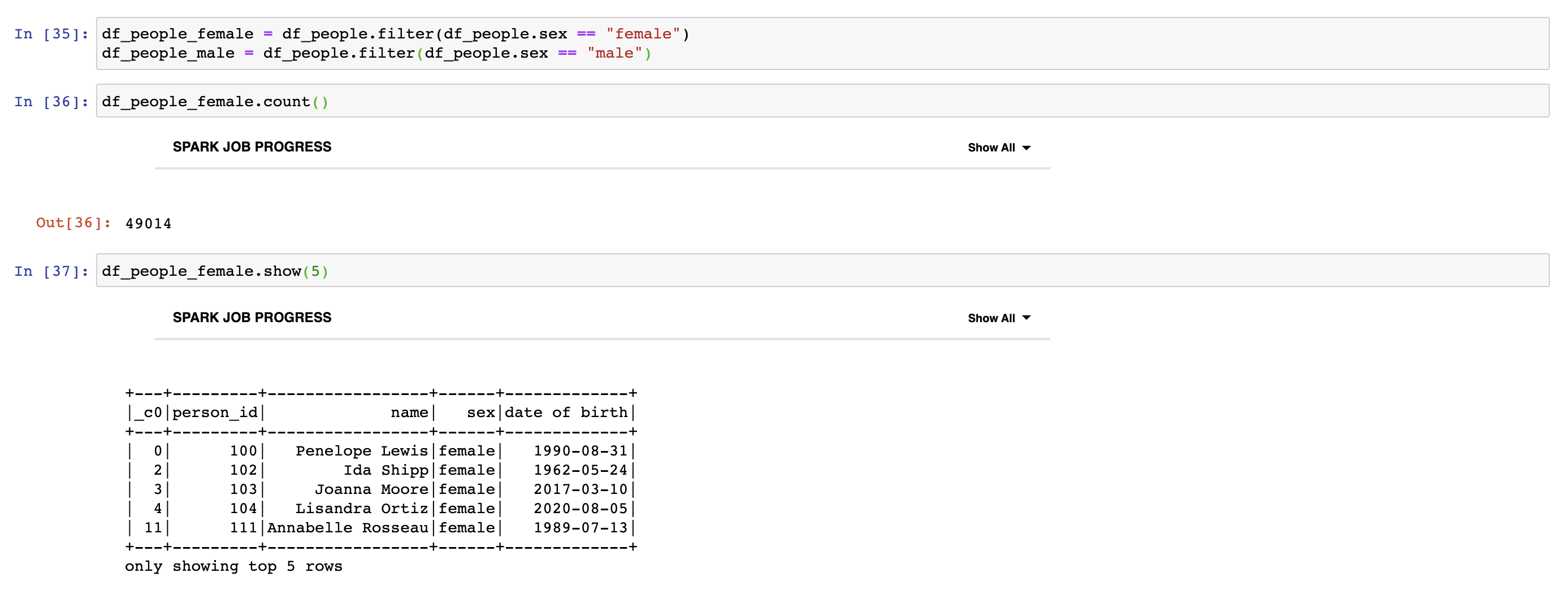
We can filter out the rows based on a condition by using filter transformation as in the following example.
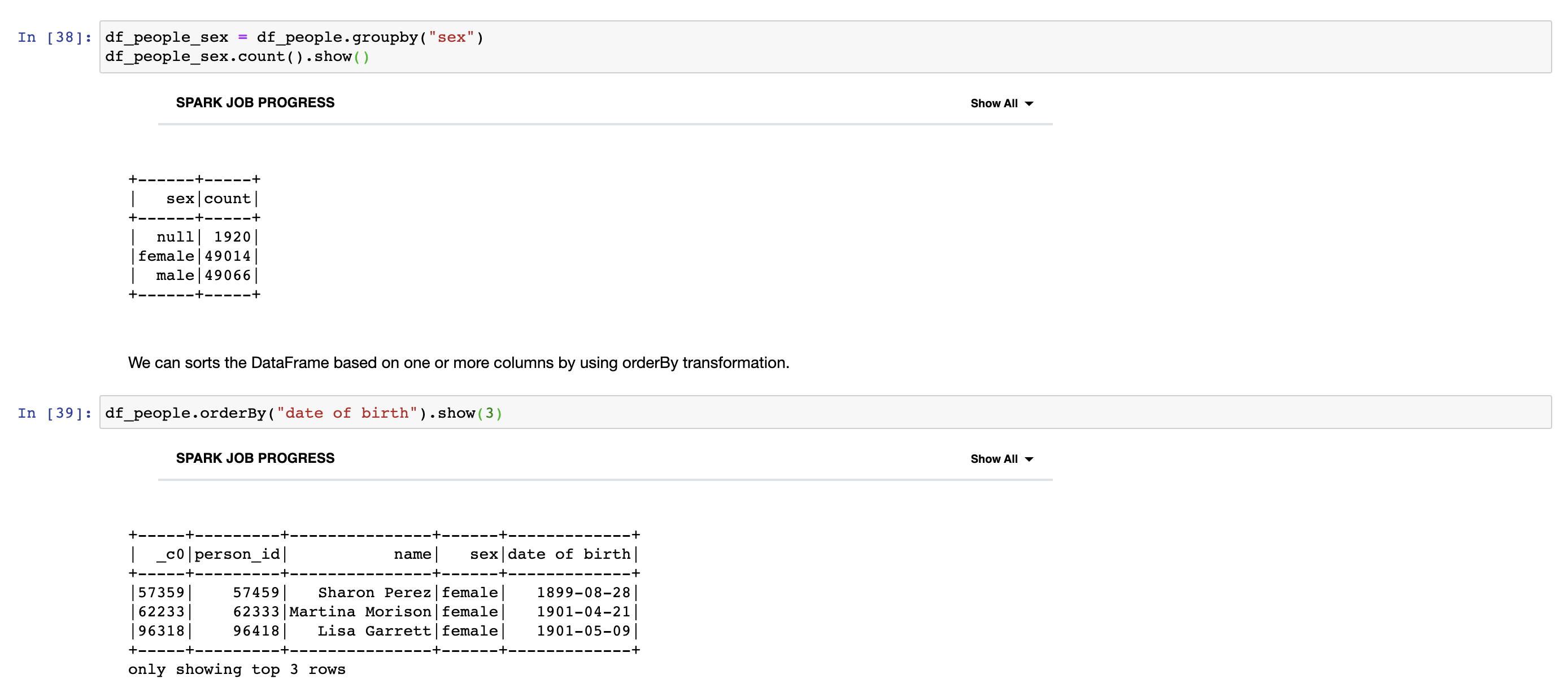
We can group columns based on their values by using group by transformation as in the following example.
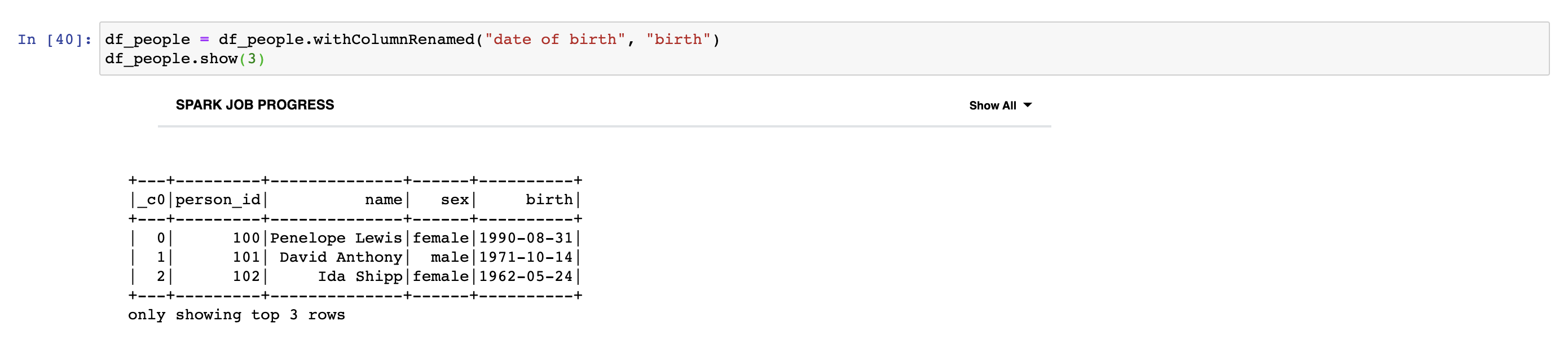
 We can rename a column in DataFrame by using withColumnRenamed transformation.
We can rename a column in DataFrame by using withColumnRenamed transformation.
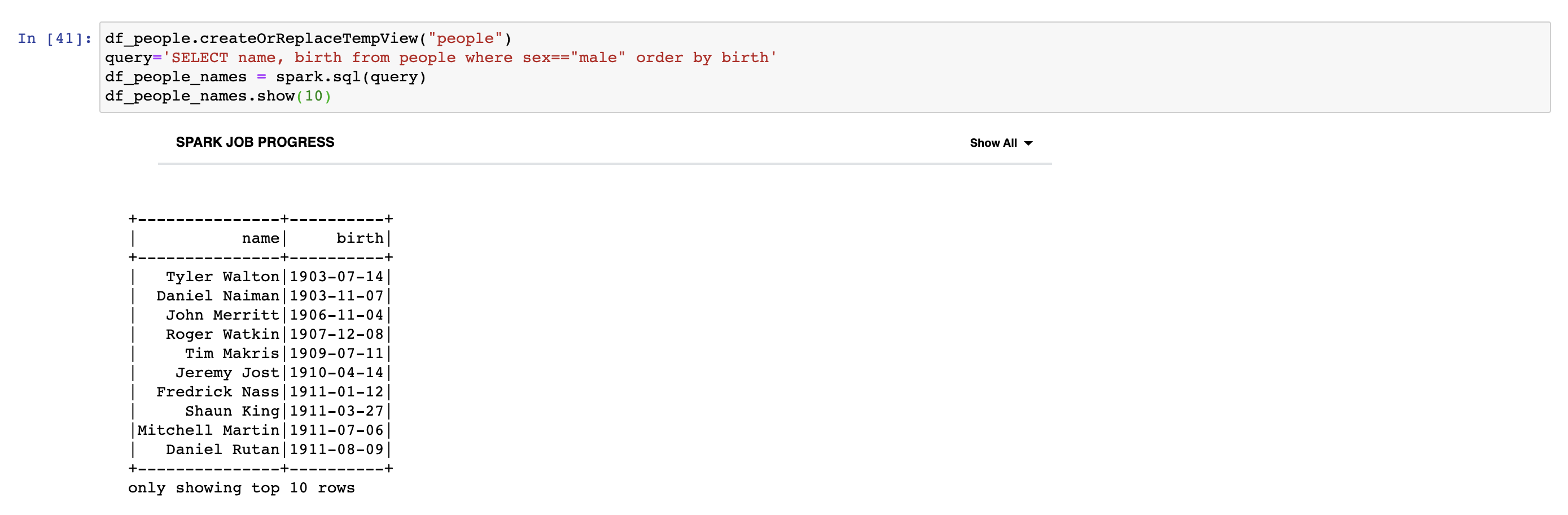
Using SQL queries with DataFrames by using Spark SQL module
We can also use SQL queries to achieve the same things with DataFrames. Firstly, we should create temporary table by using createOrReplaceTempView method. We should give the name of temporary table as an argument to the method. Then, we can give any query we want to execute to SparkSession's sql method as an argument. Look at the following example.
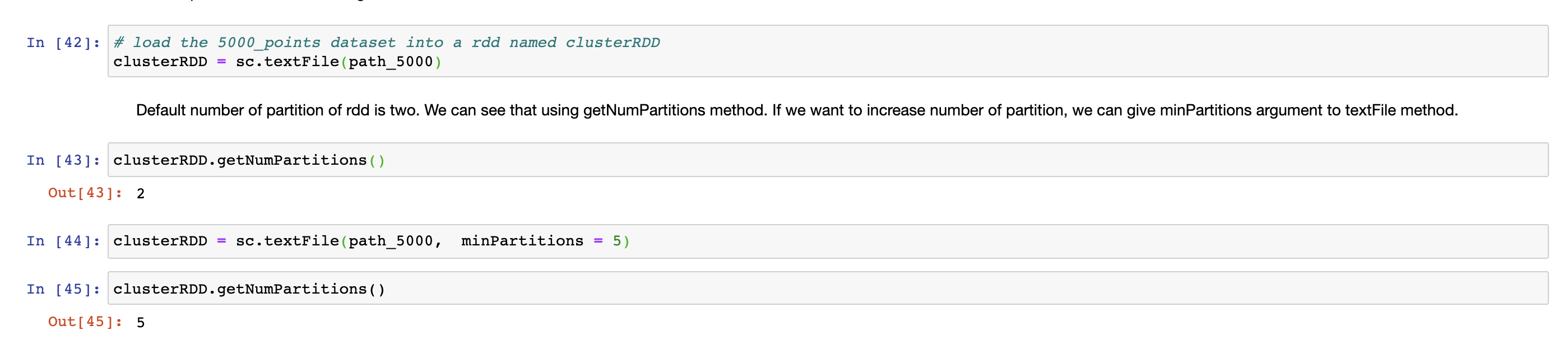
Create RDD from external file
The second and most common way to create RDDs is from an external data set. To do this, we can use SparkContext's textFile method. In the following example, we use 5000_points.txt data set. To do this, we use path to data set as an argument to textFile method.
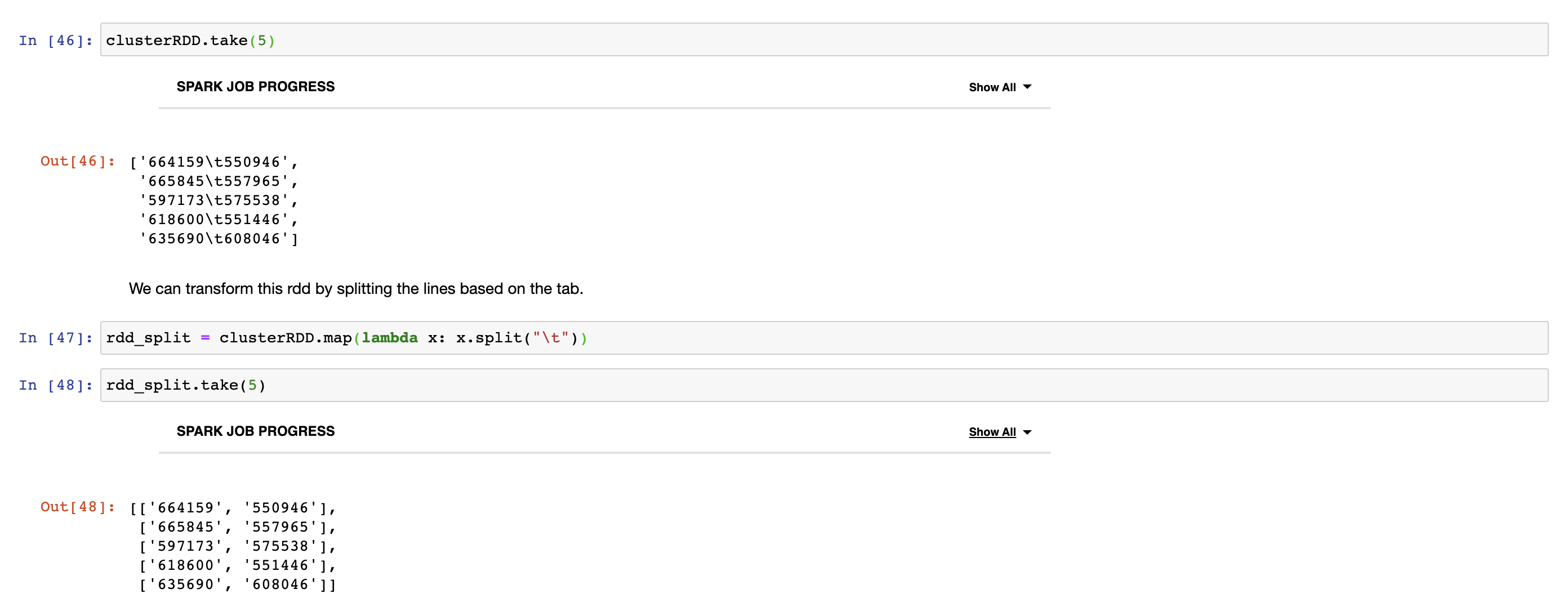
We can also further transform the splitted RDD to create a list of integers for the two columns.

Machine learning with PySpark MLlib
PySpark MLlib is the Apache Spark's scalable machine learning library in Python consisting of common learning algorithms and utilities. We use K-means algorithm of MLlib library to cluster data in 5000_points.txt data set. First, we should define error method to calculate distance from every point to center of its clusters which the points belong to.

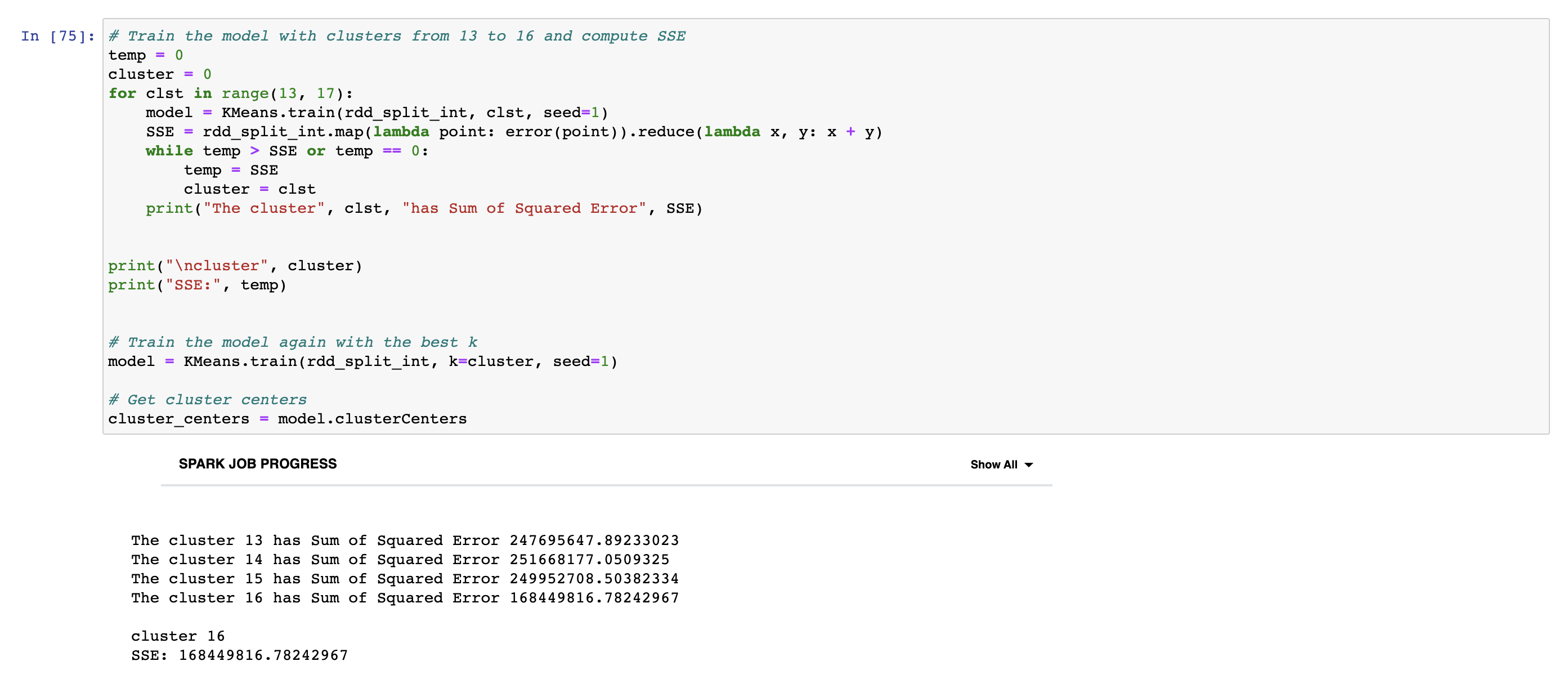
We train the model with 4 different number of clusters from 13 to 16 and then calculate the error for all of them. As you see in the output, 16 clusters give minimum error. We retrain the model with the number of cluster with the smallest error. We then use clusterCenters attribute to see the center of all clusters.
<
We can again use SparkSession's createDataFrame method to create DataFrame from RDD. We must convert PySpark DataFrame to Pandas DataFrame in order to visualize data. To do this, we can use toPandas method. We create another Pandas DataFrame from cluster centers list. Then, using matplotlib's scatter method, we can make plot for clusters and their centers.

Summary
This tutorial covered Big Data via PySpark (a Python package for spark programming). I explained SparkContext by using map and filter methods with Lambda functions in Python. I also created RDD from object and external files, transformations and actions on RDD and pair RDD, SparkSession, and PySpark DataFrame from RDD and external files. Next, I used sql queries with DataFrames (by using Spark SQL module). And finally, I used machine learning with PySpark MLlib library.