Tutorial
Learn to discover data that resides in your data sources
Gain insight about the content of data assets in data sourcesLarge-scale enterprises tend to have a large amount of linked data spread across multiple tables and files. There is a real need for the ability to gain insight about the quality and business content of these tables and files to identify and locate the correct information quickly. Watson Knowledge Catalog on IBM Cloud Pak for Data lets you discover and analyze assets present in various data sources.
The data discovery feature of Watson Knowledge Catalog lets you gain insight about the quality and content of your data assets using one of two methods. Automated discovery provides the means to run a deeper analysis on the assets.
In this tutorial, you learn how to use automated discovery on IBM Cloud Pak for Data to discover and analyze data assets from data sources.
Learning objectives
In this tutorial, you will:
- Discover data assets by using automated discovery
- Look through the automated discovery results
Prerequisites
- An IBM Cloud account
- Db2 on IBM Cloud
- IBM Cloud Pak for Data 4.6
- Watson Knowledge Catalog on IBM Cloud Pak for Data
- Completion of the steps in the Incorporate enterprise governance in your data tutorial
Estimated time
It should take you approximately 60 minutes to complete this tutorial.
About the data
This tutorial uses synthetic patient healthcare data created by using Synthea. The data sets provided as part of this tutorial are:
- PATIENTS: Demographic information about patients
- PAYERS: Information about payers such as an insurance company
- PROVIDERS: Information about providers such as a primary care physician
- ORGANIZATIONS: Information about organizations that the providers are associated with
- ENCOUNTERS: Information about an encounter between patients/providers/payers/organizations
- ALLERGIES: Allergy information for a patient
- CAREPLANS: Information about care plans devised for a patient
- CONDITIONS: Information about identified conditions for a patient
- IMMUNIZATIONS: Information about the immunizations provided to a patient
- MEDICATIONS: Information about the medications that a patient is taking
- OBSERVATIONS: Patients' healthcare observations such as weight/height/blood pressure taken during an encounter
- PROCEDURES: Information about procedures that a patient has undergone
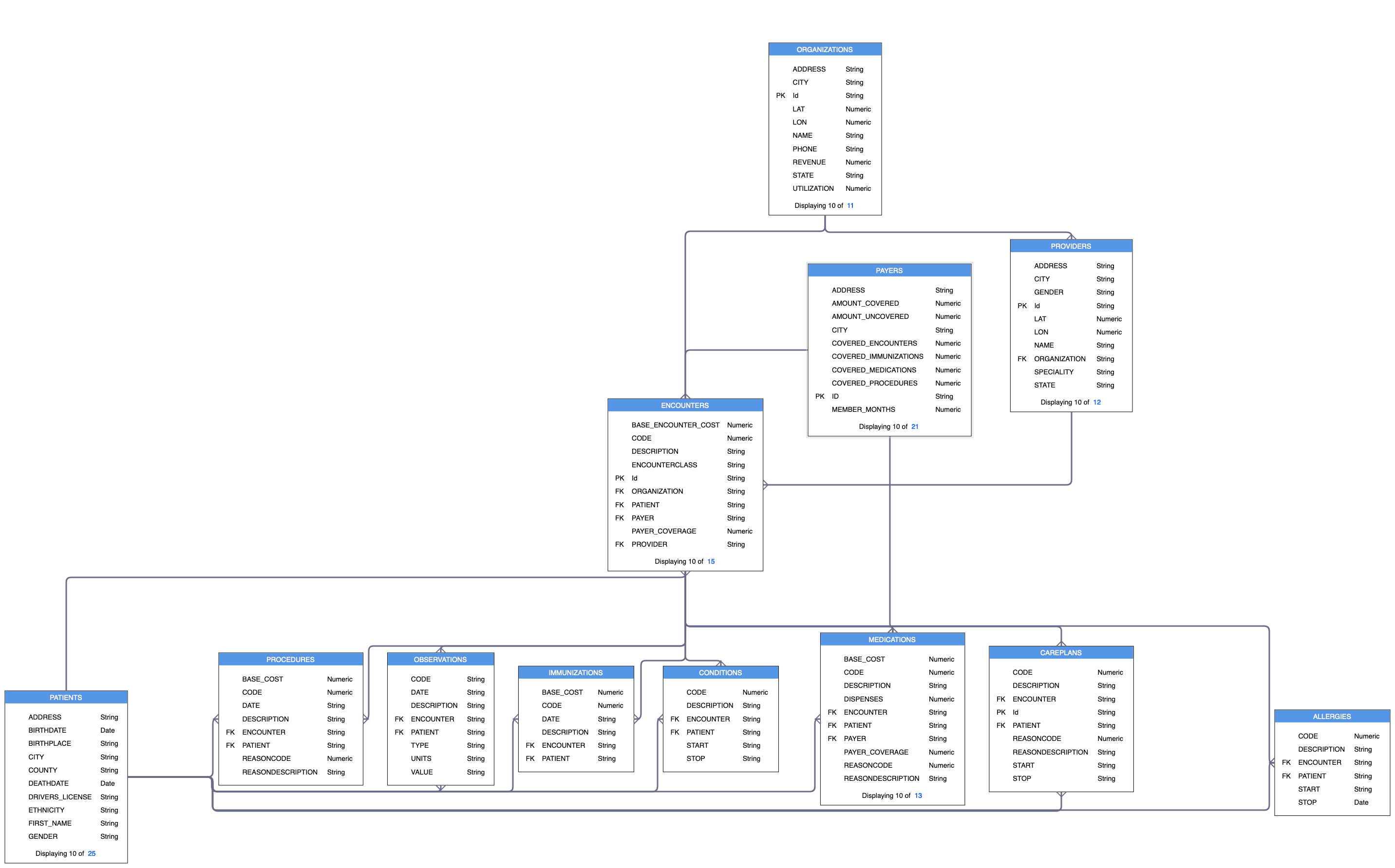
Note: This tutorial provides instructions for discovering and analyzing the PATIENTS and ENCOUNTERS tables. For an extended version of this tutorial, load all 12 data sets.
About data discovery
With data discovery, you can gain insight about the quality and business content of the tables and files within your data sources. You can run a deep analysis on the most interesting or most useful assets by using automated discovery. With automated discovery, the metadata and analysis results are automatically imported into the default catalog. The analysis results are also made available for viewing and updating within a project, and these results include the data quality score, automatically assigned data classes, business terms, data types, formats, and frequency distributions.
Note: As part of this tutorial, you run automated discovery on your data. In the next tutorial within this series, you perform a deeper analysis on the automated discovery results for your data.
Step 1. Load data into the data sources
Note: Ensure that you have provisioned Db2 on IBM Cloud before proceeding.
Download the data sets
- Download and extract the contents of the Healthcare-Data.zip file.
Seed the Db2 database
Open a browser, and log in to your Db2 instance.
Navigate to the side menu and click Data. Go to the Load Data tab, click browse files, and select the
patients.csvfile from the downloaded archive. Then, click Next.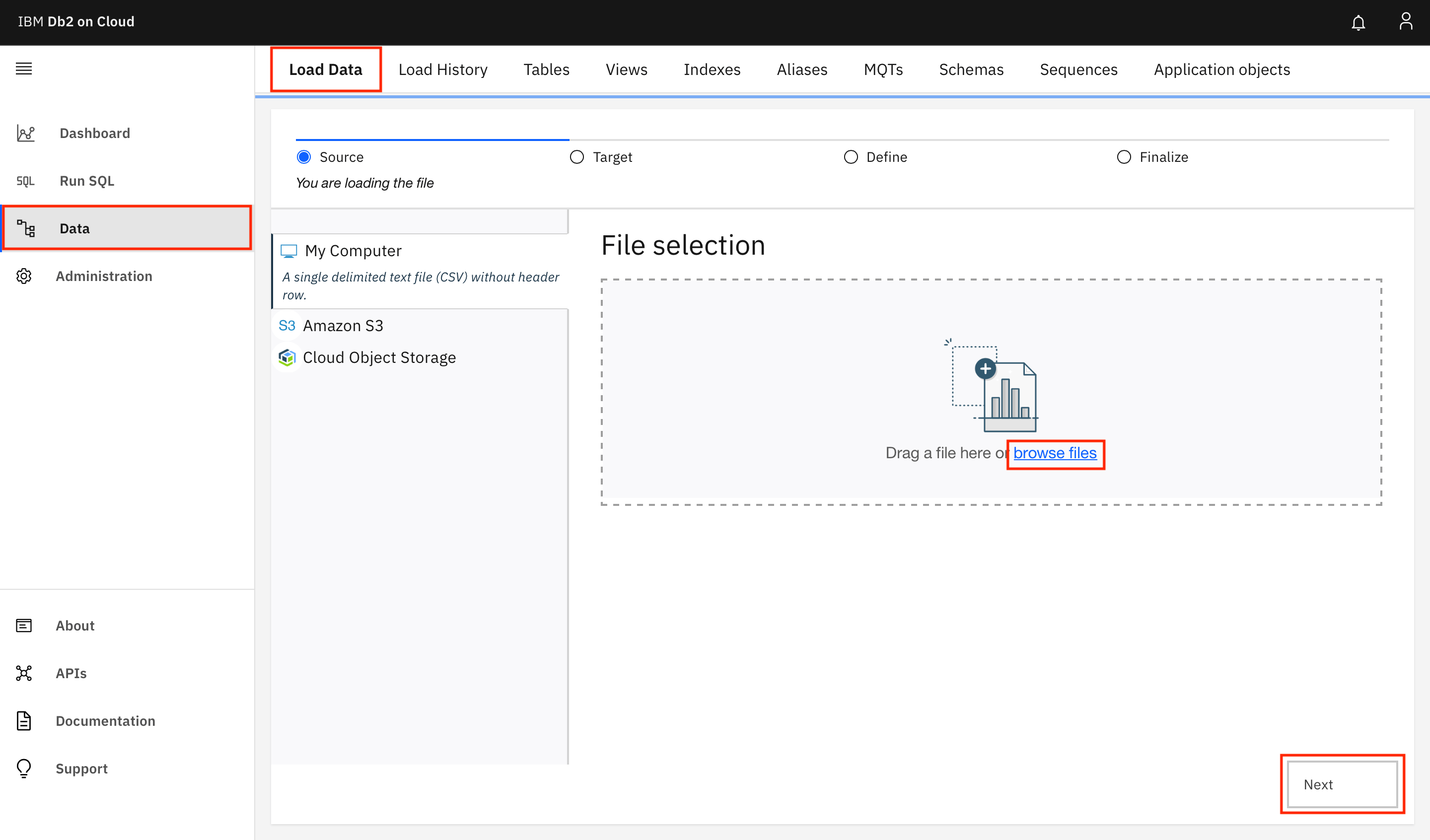
Choose your schema (for a Lite plan, the name will match your Db2 user name) or click New schema + to create a new schema. Then, click New table +. Under Create a new table, provide
PATIENTSas the name of the table, and click Create > Next.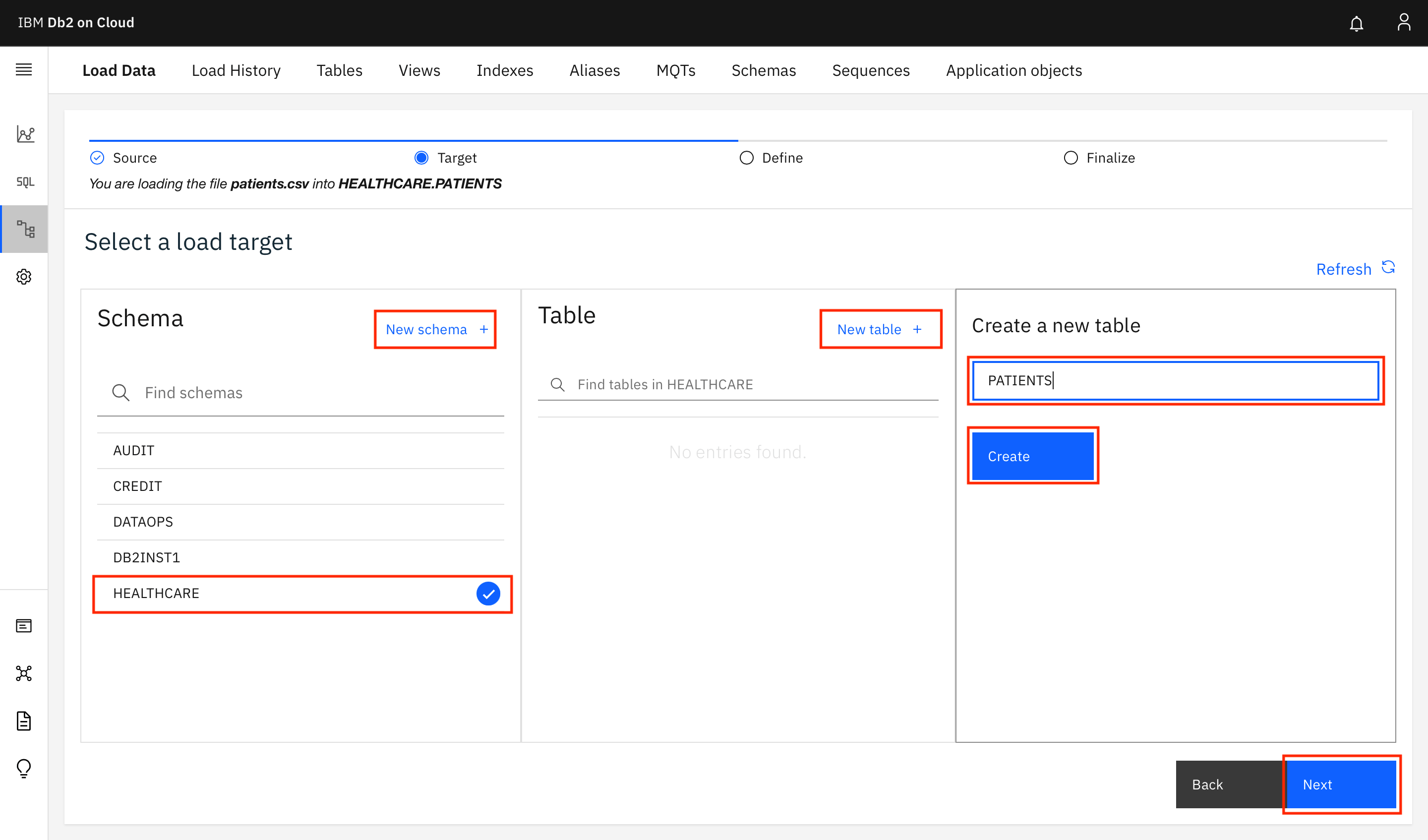
On the next screen, you can define the data types for the columns in your table. The screen shows the data types that are detected by Db2. For now, click Next to continue with the defaults.
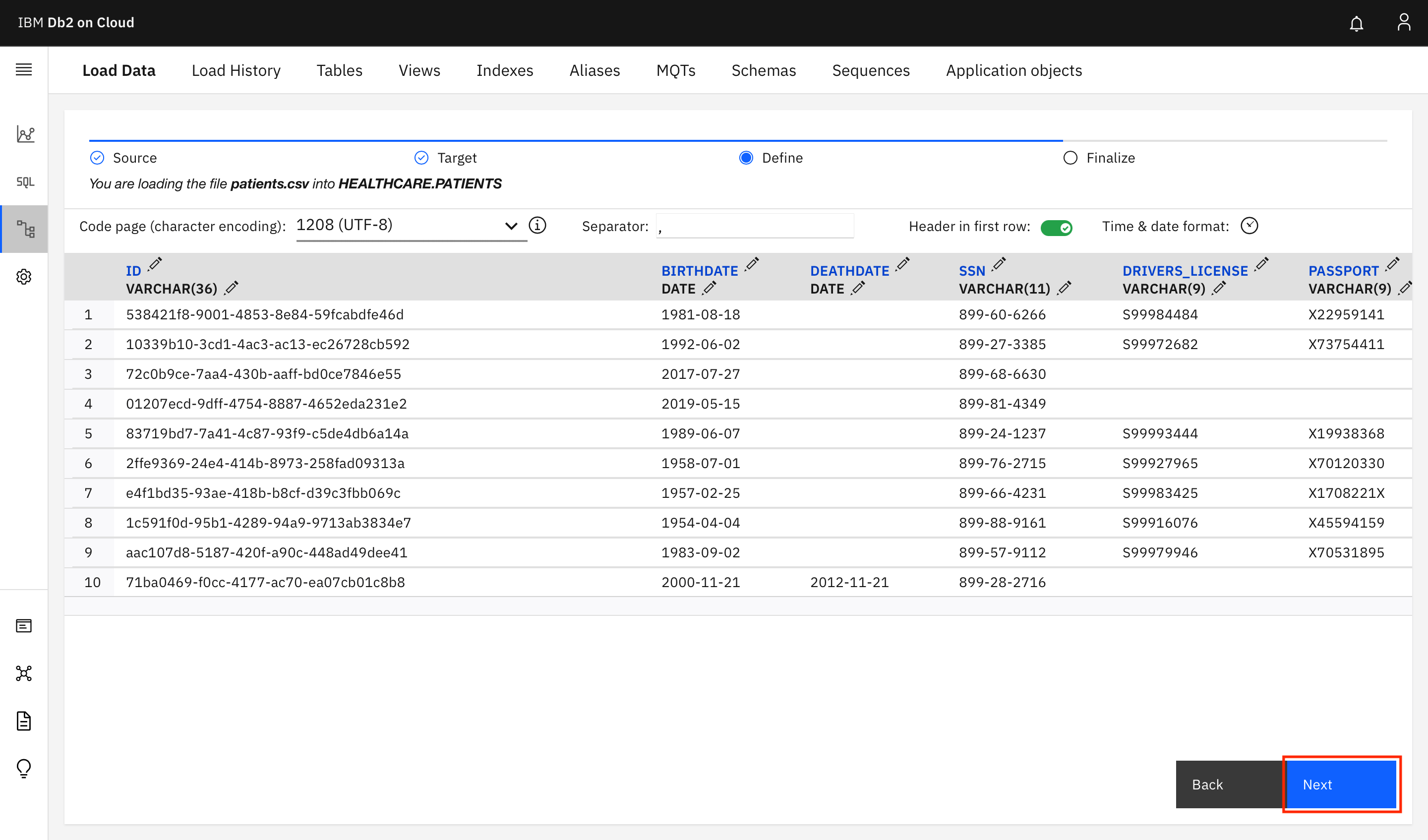
On the next screen, click Begin Load.
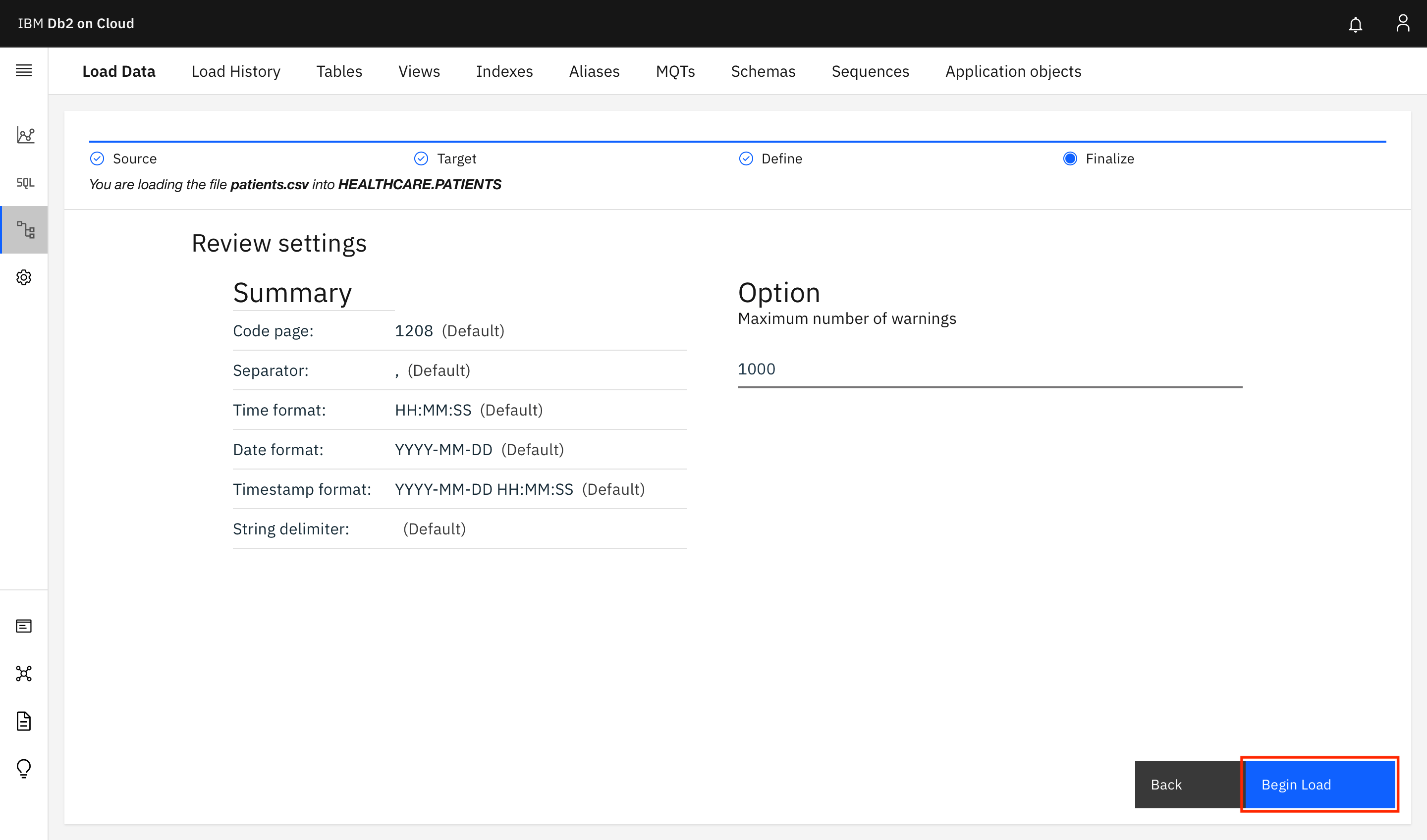
The PATIENTS table is now created by loading the records found in the
patients.csvfile.Repeat the steps to load the
encounters.csvfile into the ENCOUNTERS table.
Note: For the extended version of this tutorial, load all 12 data sets provided in the Healthcare-Data.zip file. The following table provides the table names for each input file.
| File name | Table name |
|---|---|
allergies.csv |
ALLERGIES |
careplans.csv |
CAREPLANS |
conditions.csv |
CONDITIONS |
encounters.csv |
ENCOUNTERS |
immunizations.csv |
IMMUNIZATIONS |
medications.csv |
MEDICATIONS |
observations.csv |
OBSERVATIONS |
organizations.csv |
ORGANIZATIONS |
patients.csv |
PATIENTS |
payers.csv |
PAYERS |
procedures.csv |
PROCEDURES |
providers.csv |
PROVIDERS |
Get the database connection information
Log in to IBM Cloud, and navigate to your Db2 resource.
Go to Service Credentials, and click New credential +. A new set of service credentials is created. Expand the entry to look at the credentials.
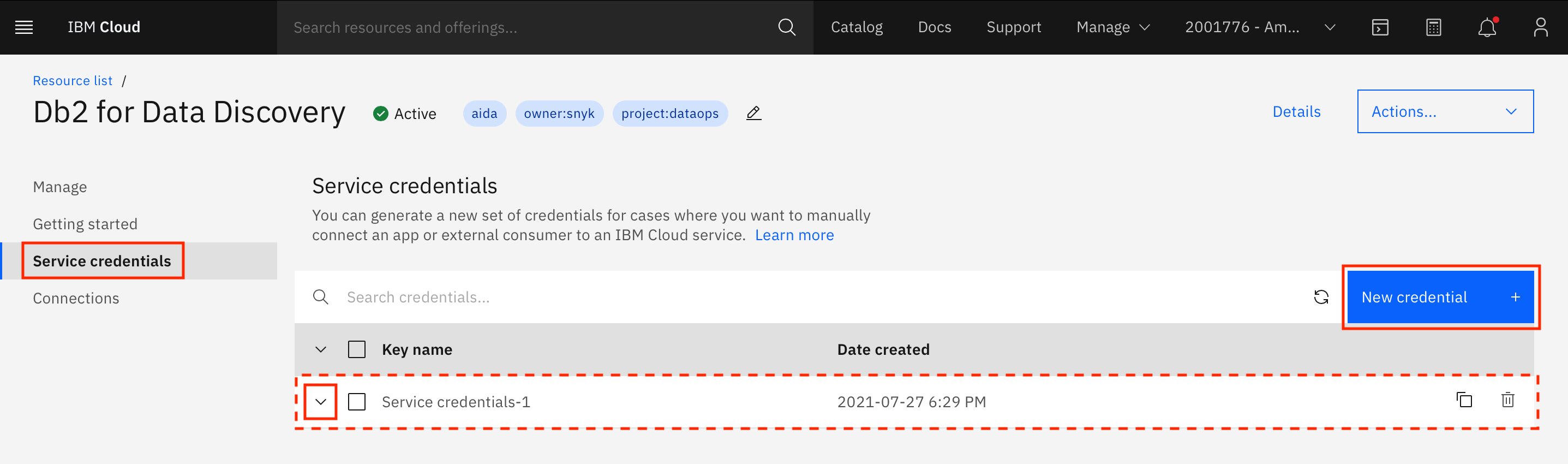
From the service credentials, extract the following values. You need them later in this tutorial when you create a platform connection for this Db2 instance in your IBM Cloud Pak for Data instance.
hostnameportusernamepassworddatabasecertificate_base64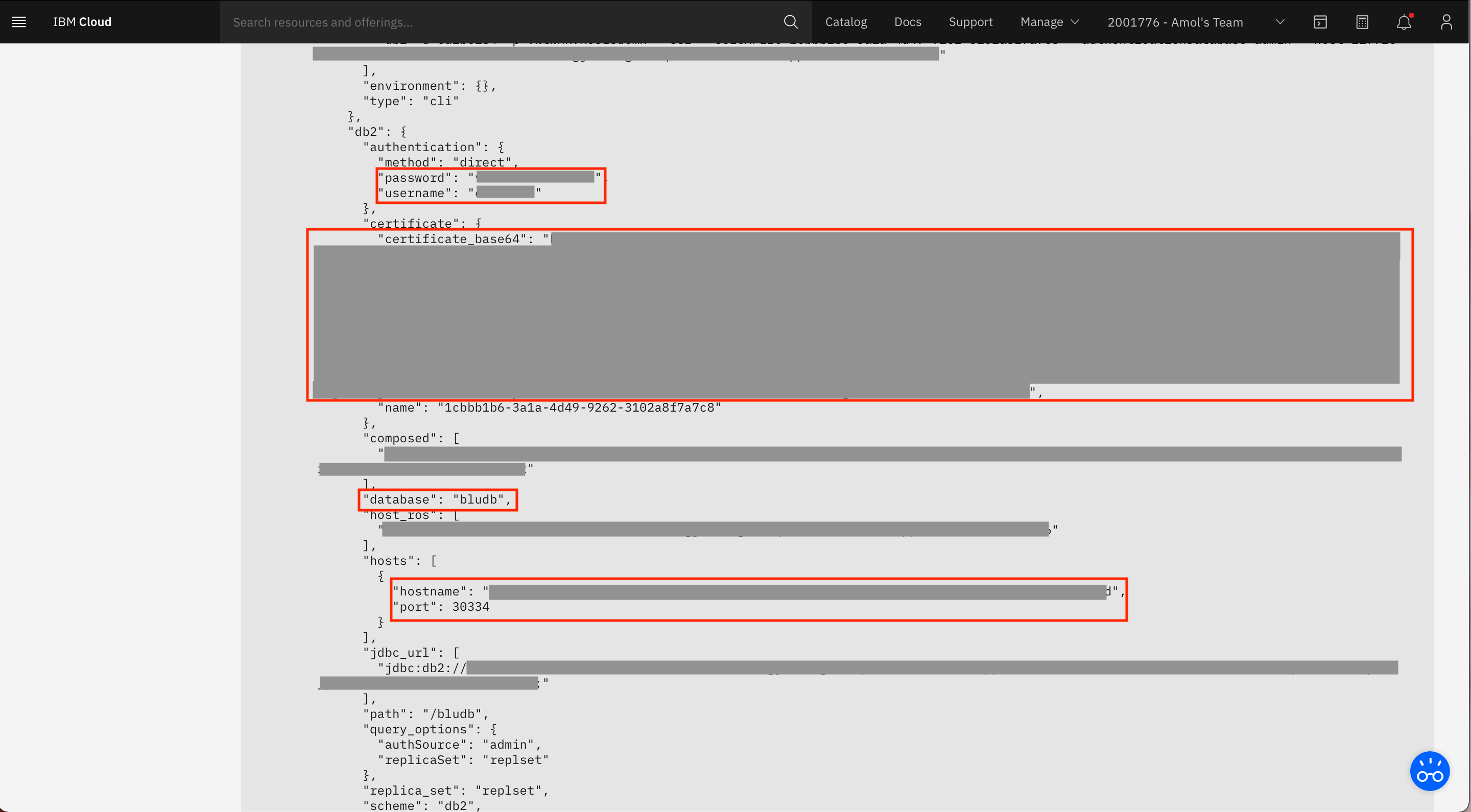
The SSL certificate is in the base64-encoded DER format, and Data Discovery on IBM Cloud Pak for Data requires that the certificate be in the PEM format. Save the
certificate_base64value in a file (db2_certificate.pfx). Then, run the following command in a terminal (or command prompt) to convert the certificate:openssl base64 -d -A -in db2_certificate.pfx -out decoded_db2_certificate.pem
The decoded_db2_certificate.pem file contains the decoded certificate that is needed while creating the platform connection on your IBM Cloud Pak for Data instance.
Step 2. Add connection to IBM Cloud Pak for Data
You now add the Db2 instance as a platform connection to IBM Cloud Pak for Data.
Log in to your IBM Cloud Pak for Data instance as a user with admin privileges.
To add a new data source, go to the Navigation Menu, expand Data, and click Platform connections.
At the overview, click New connection +.
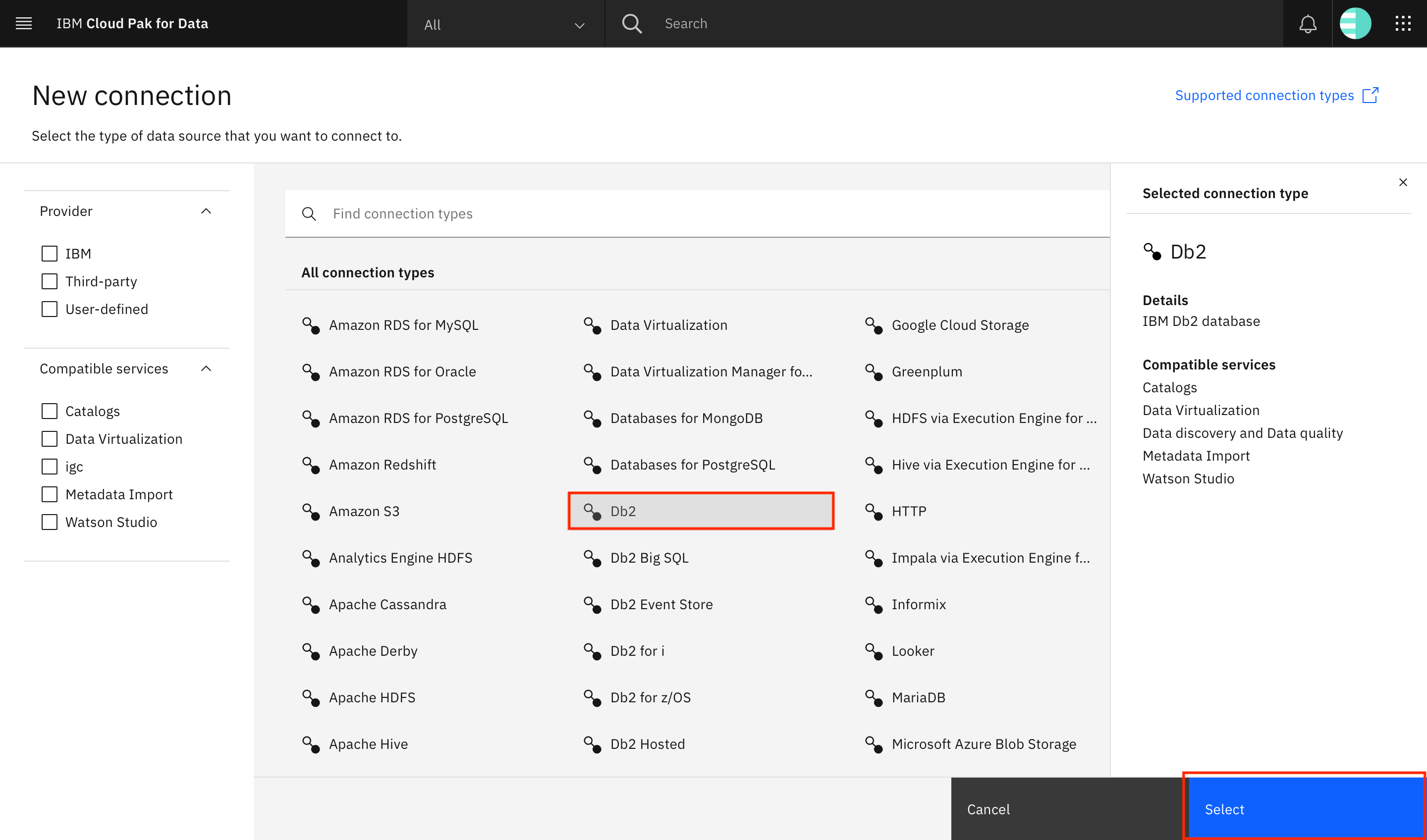
Click Db2 > Select.
Provide a name for the connection. Ensure that there are no white spaces in the name.
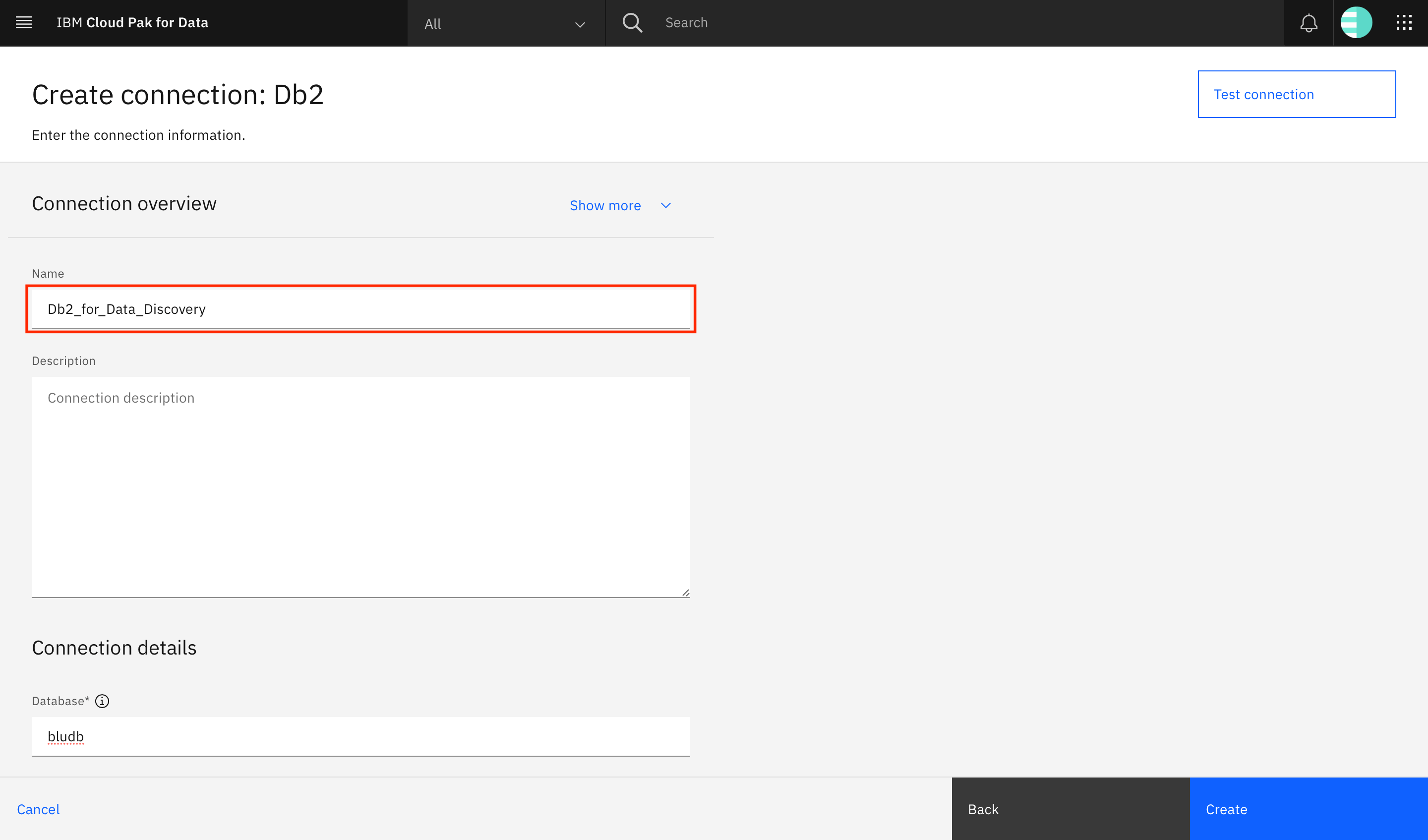
Scroll to the Connection details section. Provide the connection details (database name, host, port, username, and password) that were obtained in Step 1: Get the database connection information.
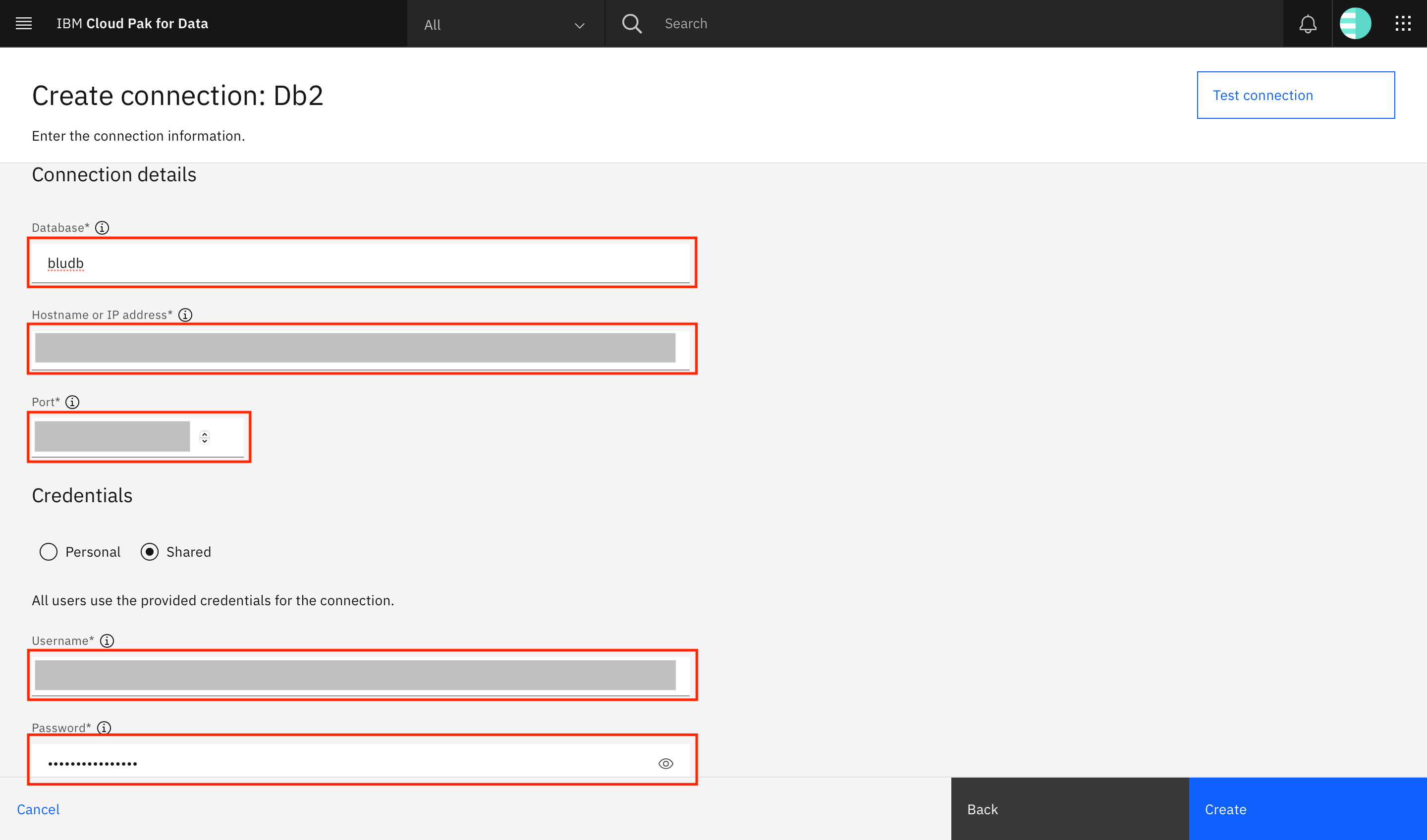
Select the Port is SSL-enabled checkbox and provide the converted SSL certificate (from the
decoded_db2_certificate.pemfile) in the SSL certificate field. Click Test connection to test the connection. When the test is successful, you see a notification at the top of the screen. Click Create to create the connection. (Refer back to Step 1: Get the database connection information for instructions on how to obtain the necessary username, password, and values.)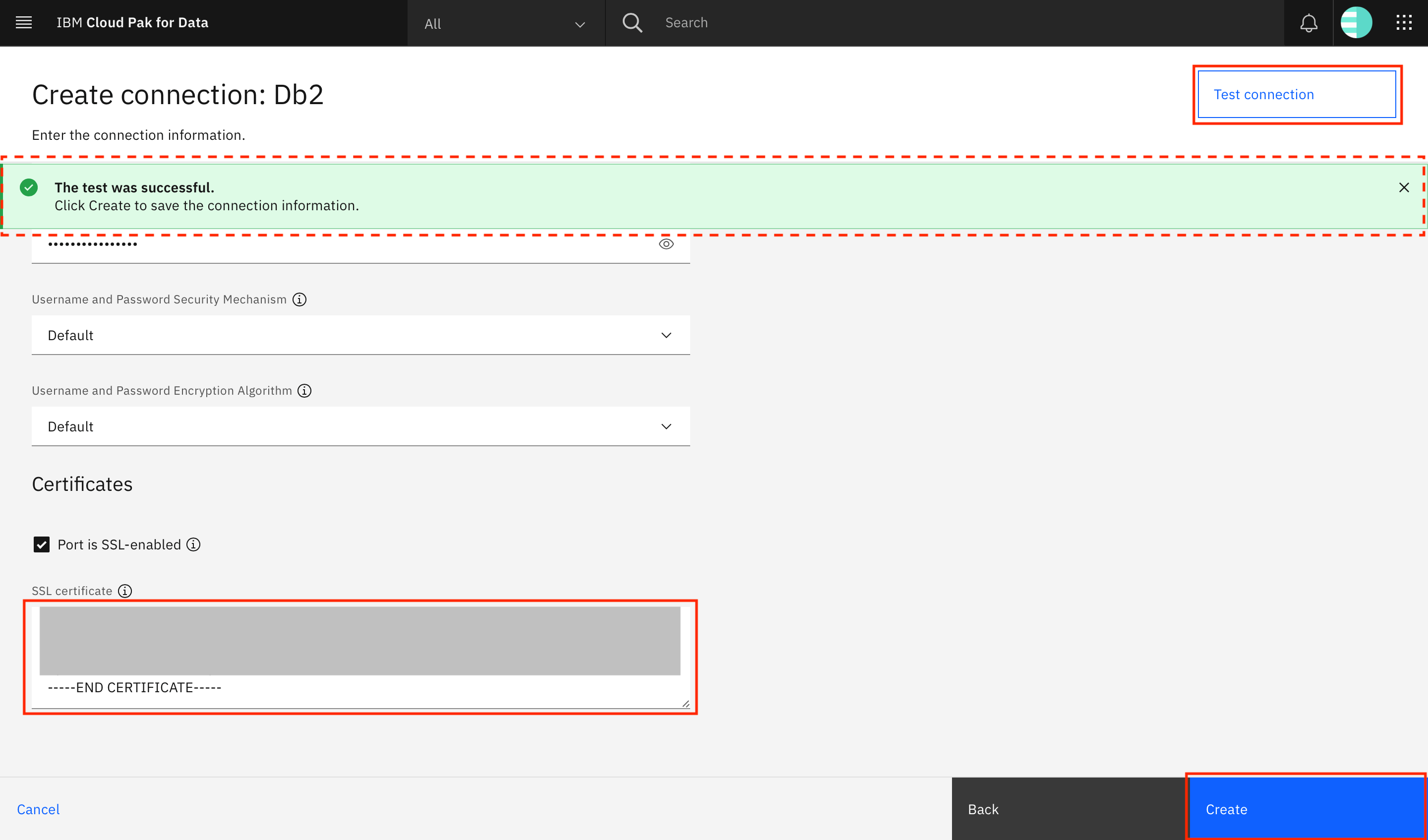
Step 3. Perform automated data discovery
Now, you can analyze your data assets by using automated data discovery.
Note: Ensure that you have completed the steps outlined in the Incorporate enterprise governance in your data tutorial and that the required governance artifacts are available.
Go to the Navigation Menu, expand Governance, and click Data discovery. Click New automated discovery.
Expand the Select a connection list, and choose the Db2 connection.
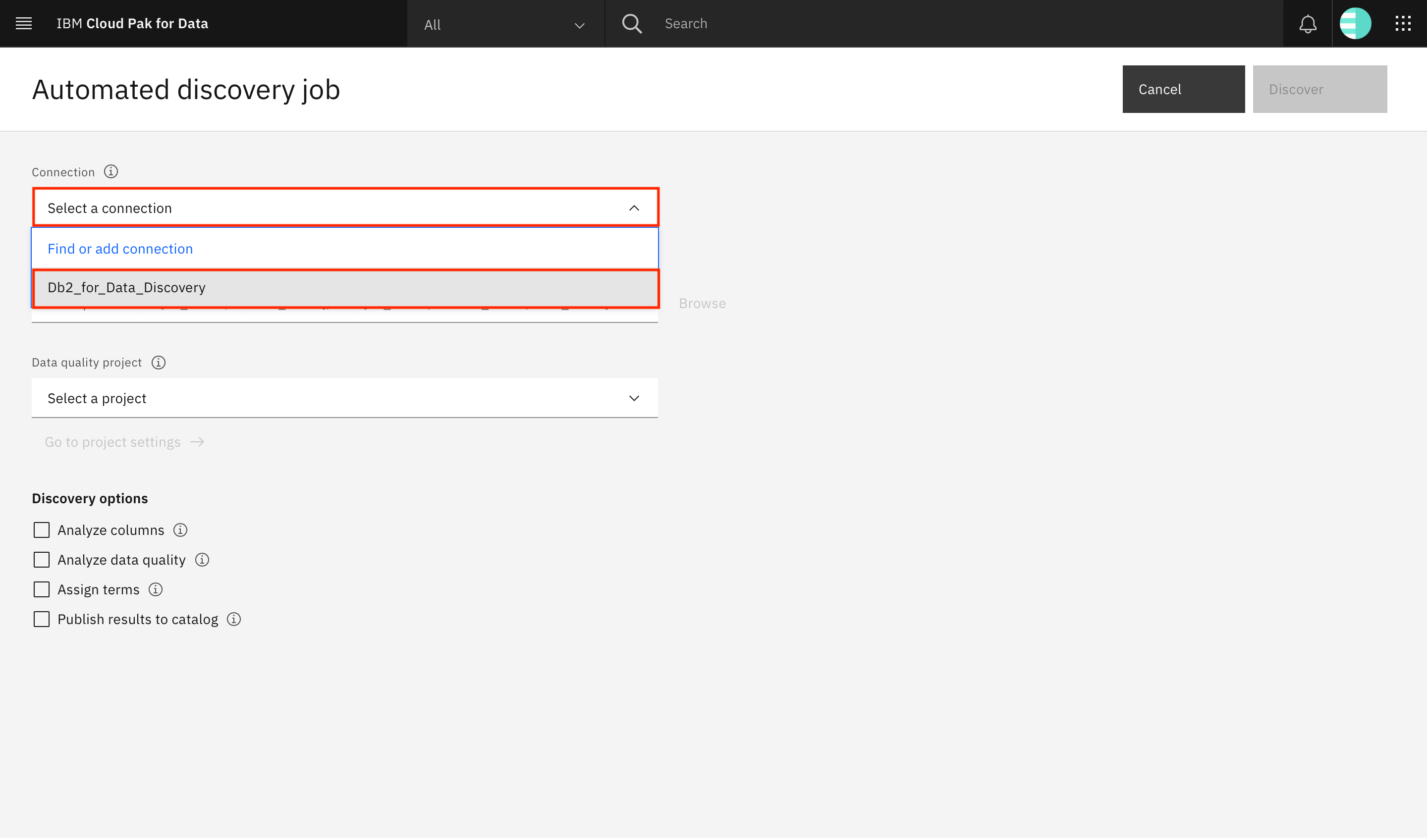
Click Browse to select the discovery root. This enables you to restrict which schemas or tables within the Db2 database are discovered.
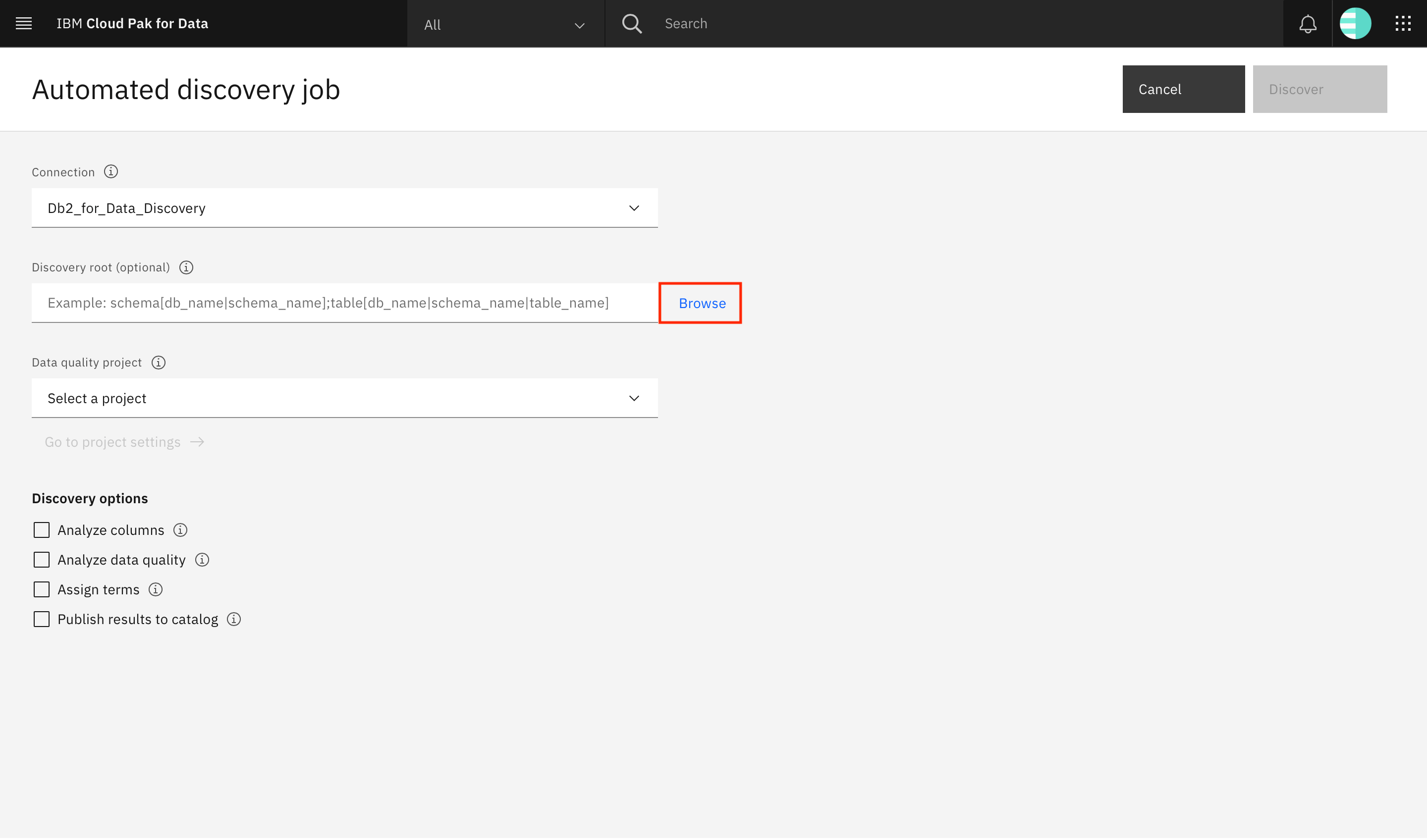
With automated discovery, you can drill further down and choose tables within the schema. Therefore, you can select which tables that you want to perform the deeper quality analysis on. However, for now, select the schema so you can perform automated discovery on all of the tables in the schema. Select the schema where you created the tables, and click Select.
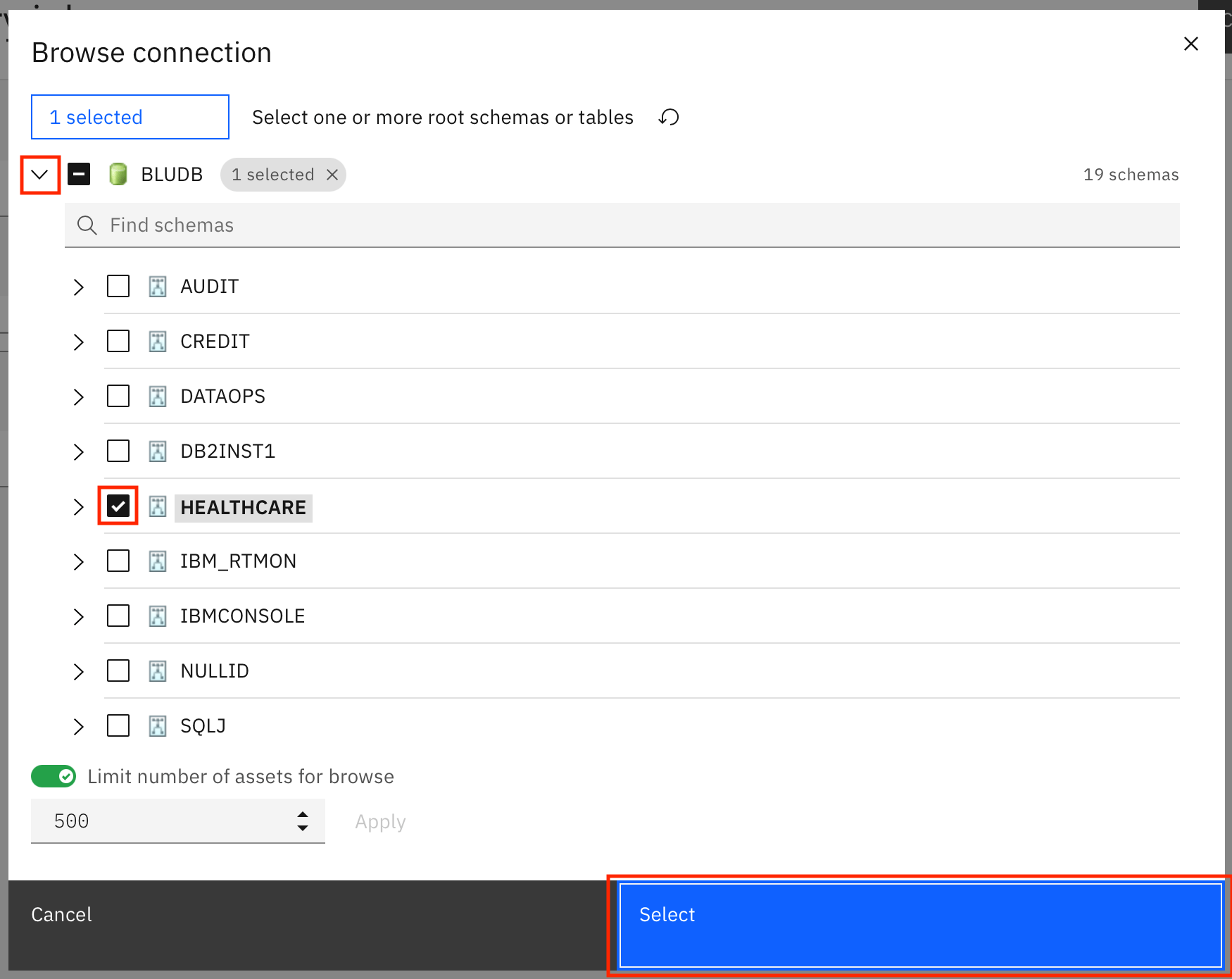
Back on the automated discovery job creation screen, click Select a project > Add a project.
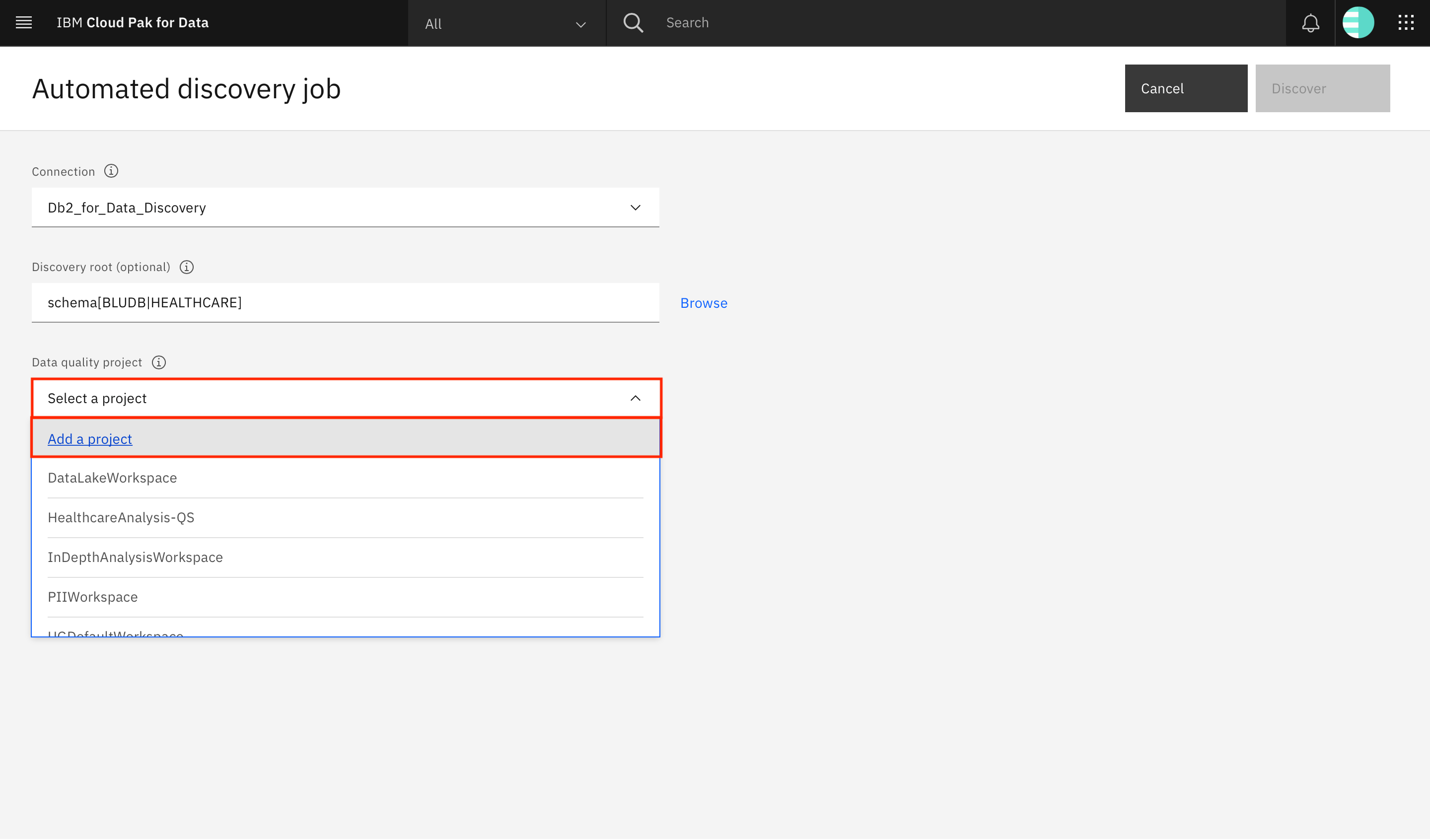
Name the project (
HealthcareAnalysis), and click Create.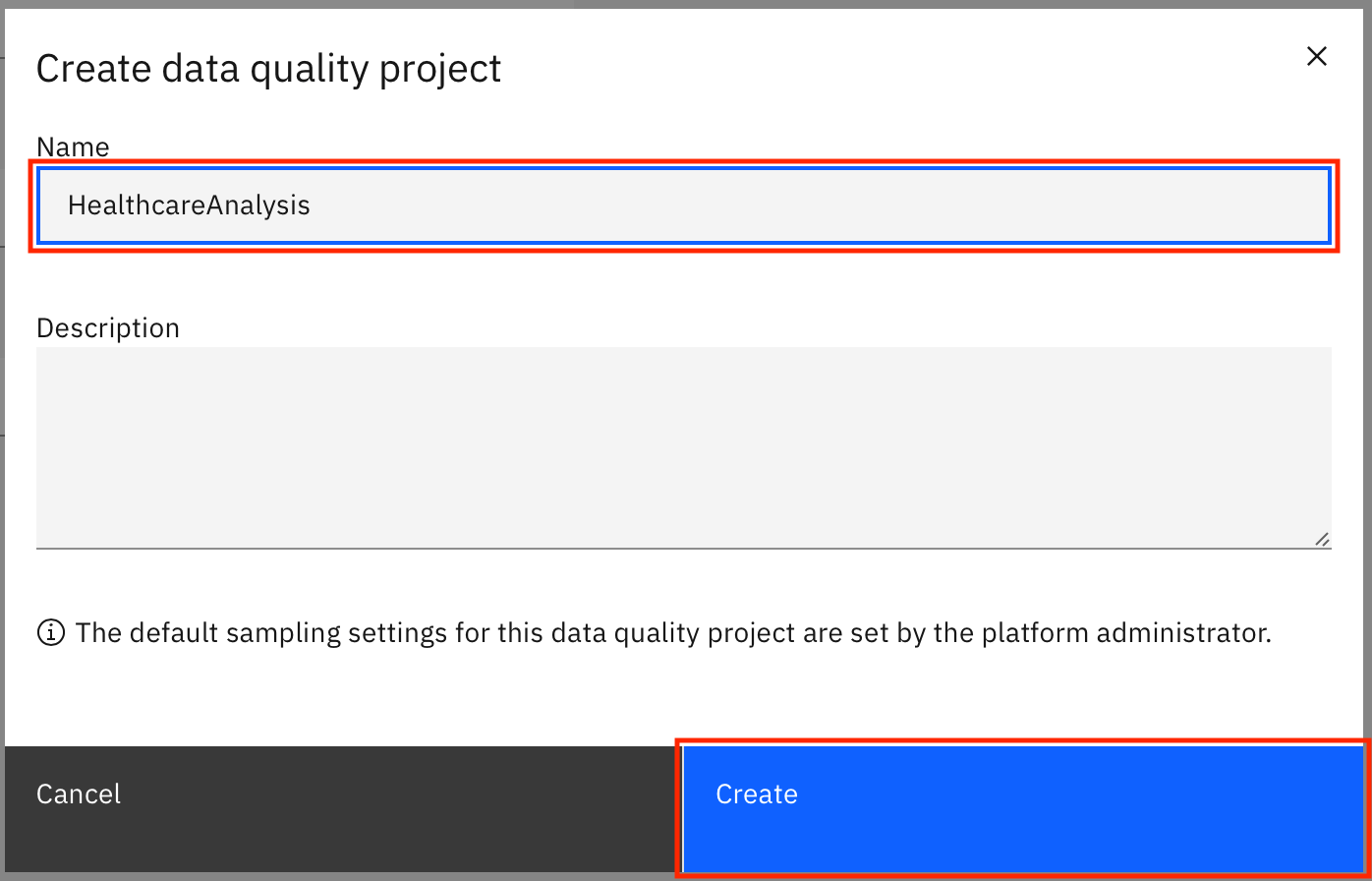
Click Go to project settings to update the project's settings.
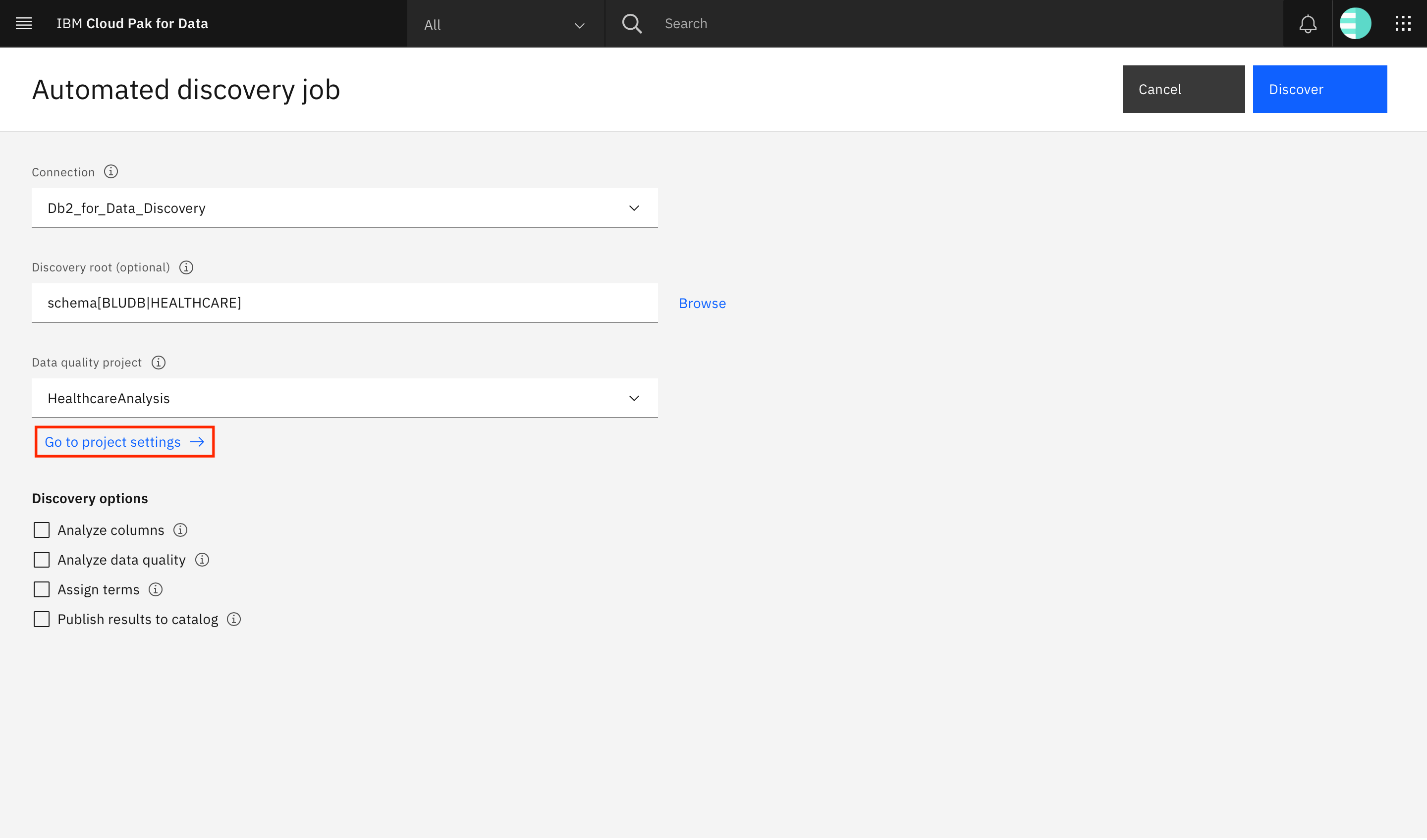
The project settings open in a new browser tab. Click the Keys and relationships tab, scroll to Foreign key settings, and update Maximum percentage of allowed orphan values to
99.Update Minimum percentage of common distinct values to
0.1and update Minimum confidence for the relationships to0.1.Click Save and close the browser tab.
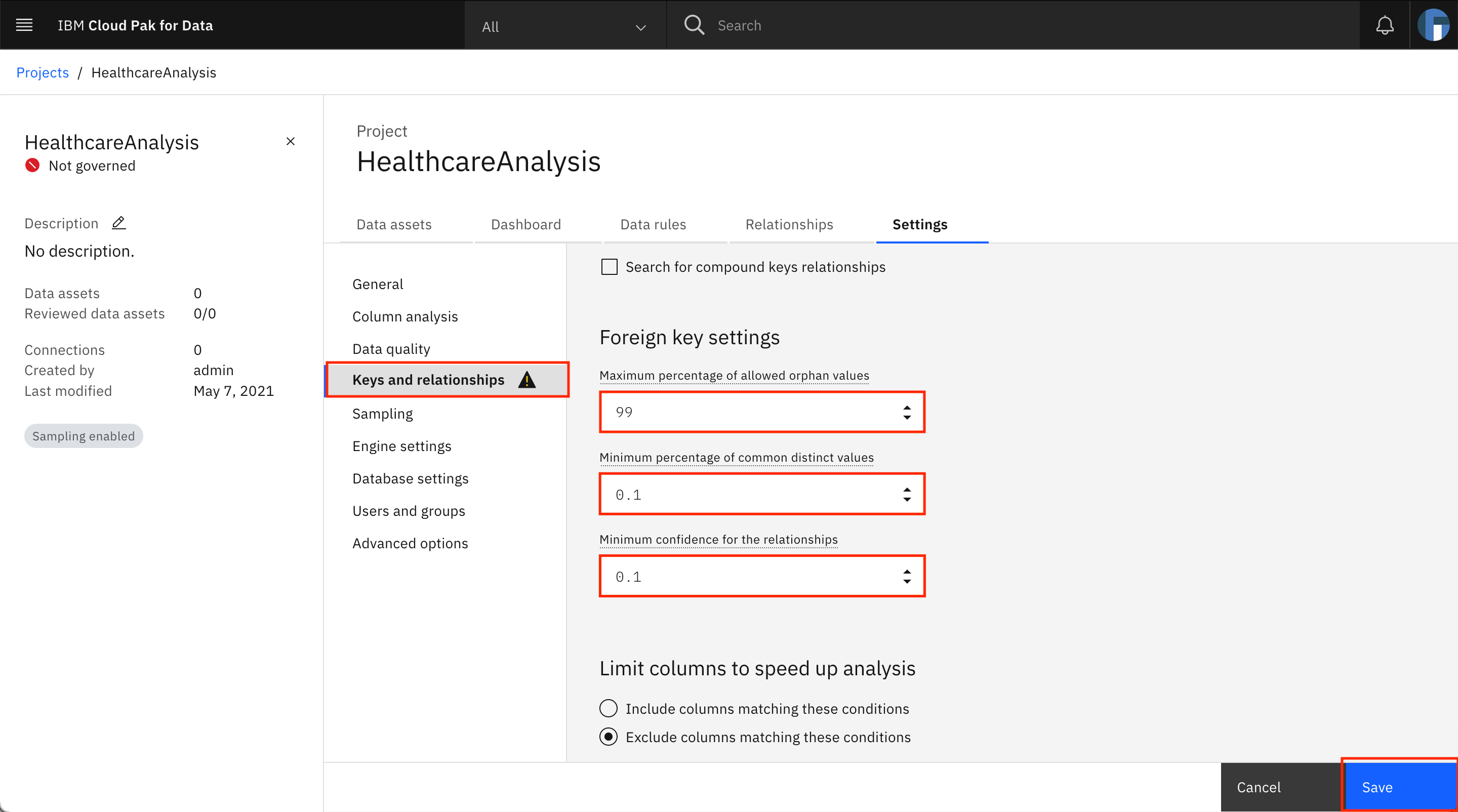
Back on the automated discovery job creation screen, check the checkbox for Analyze columns, Analyze data quality, and Use data sampling.
Select Use a random sampling and enter
1234as the seed and100as the percentage.Click Discover to start discovering the assets.
Note: While the automated discovery job creation screen lets you publish results to the catalog after the completion of the discovery and analysis processes (by using the Publish results to catalog option), keep the box unchecked for now. You will publish the results to the catalog as part of another tutorial in this series.
While you can provide a different seed, using the same seed results in the same records being selected in your sample as in the example in this tutorial. As a result, you are able to see the same results when the data discovery process is complete.
A new automated discovery job starts, and your schema name should be listed under Discovered assets. It should take a few minutes to import and analyze the assets, and the status is reflected on the screen. Click the refresh icon or refresh your browser to get the updated status. Finally, the status of the import and analyze processes displays as
Finished. Click the project name (HealthcareAnalysis) to go into your project.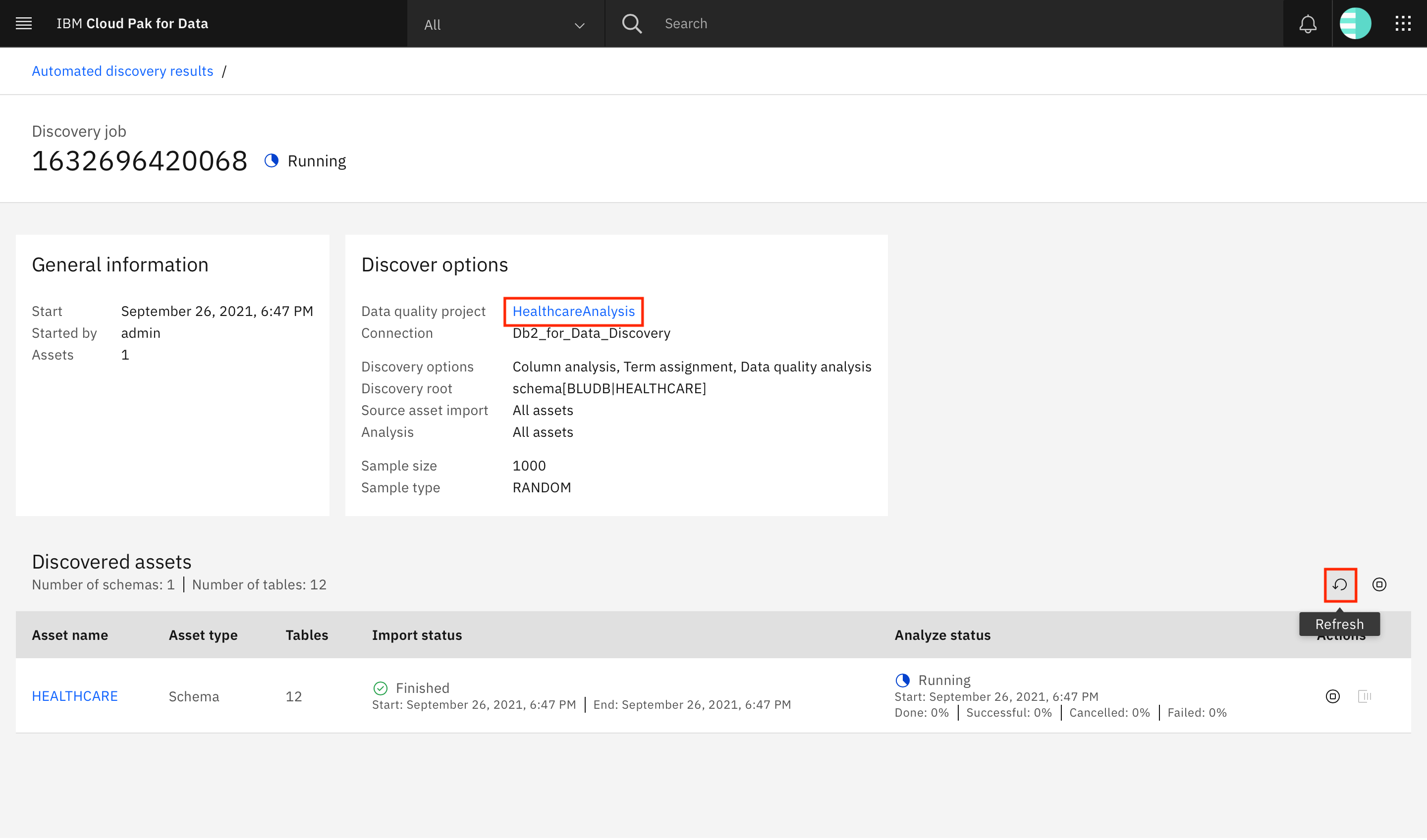
Step 4. Review automated discovery results
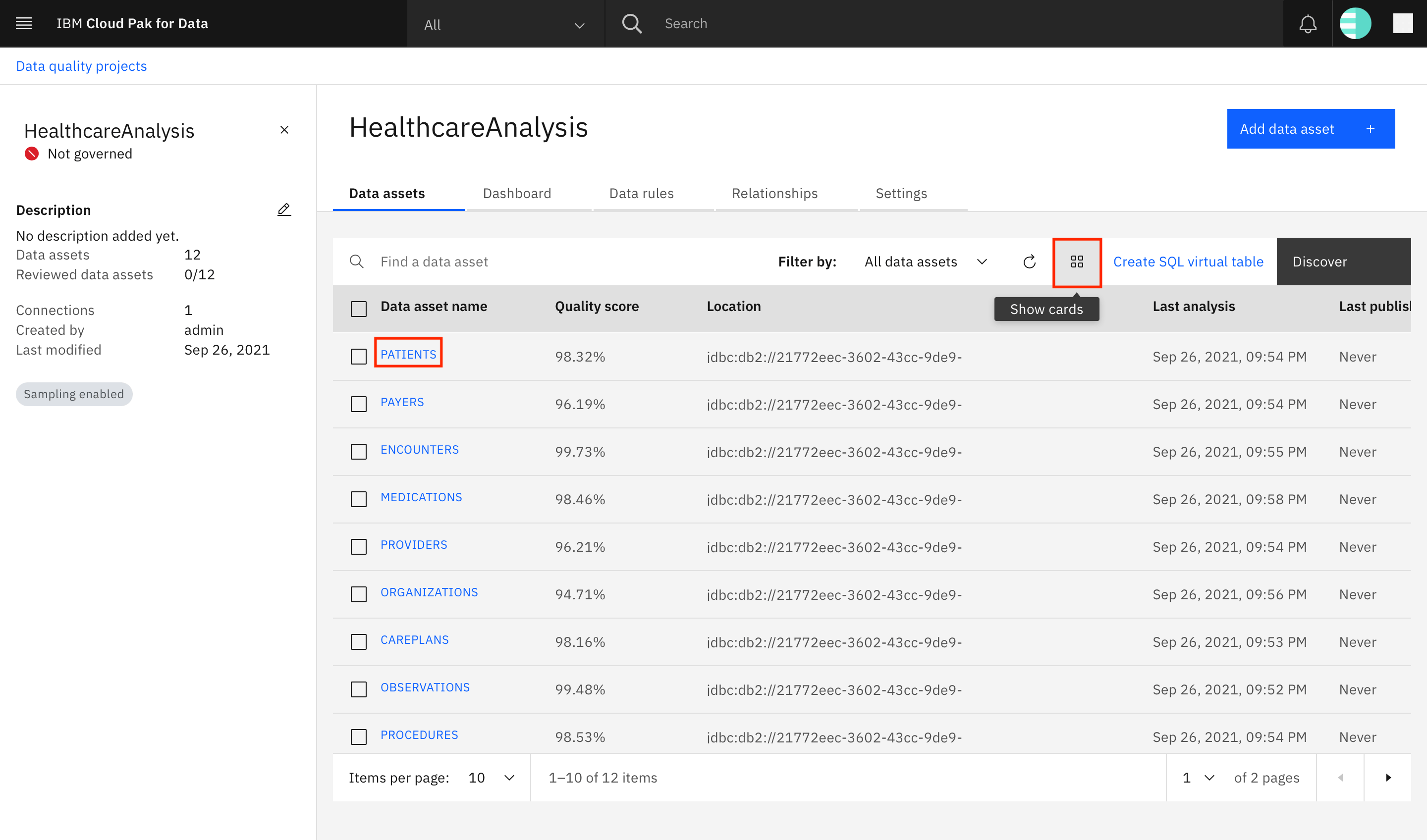
All of the discovered assets are displayed on the screen. You can switch the display for these assets between list and cards. Take a look at the different tabs present on the screen, which provide a lot of information about the project.
- The Data assets tab has information about the data assets in the project.
- The Dashboard tab has analytics about the most recent analysis performed on the assets.
- The Data rules tab has information about the rules applied to the project and the ones available to be applied.
- The Relationships tab has information about the relationships between the data assets.
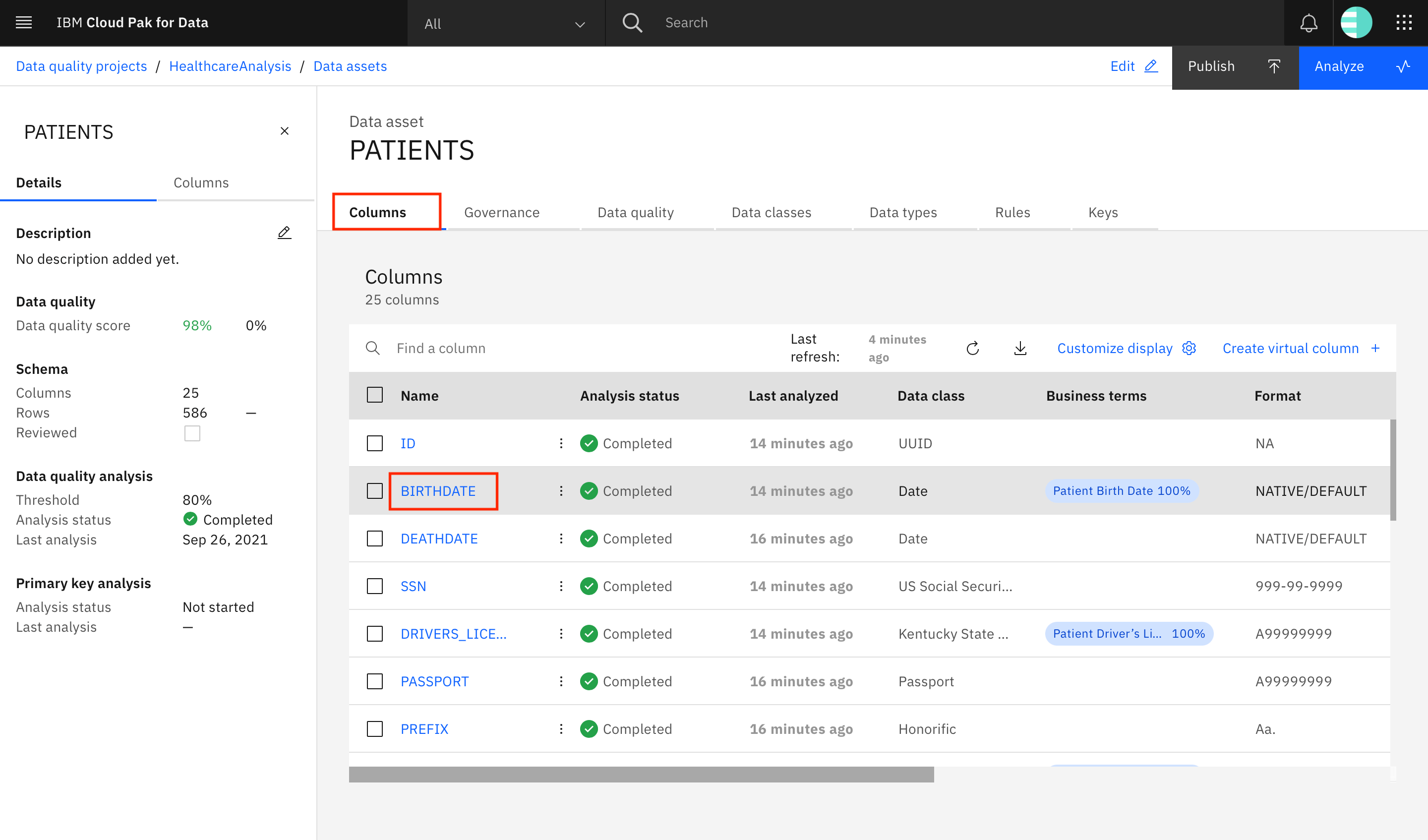
The Settings tab is where the project-specific settings can be applied. Find and click the PATIENTS data asset to see more details about it.
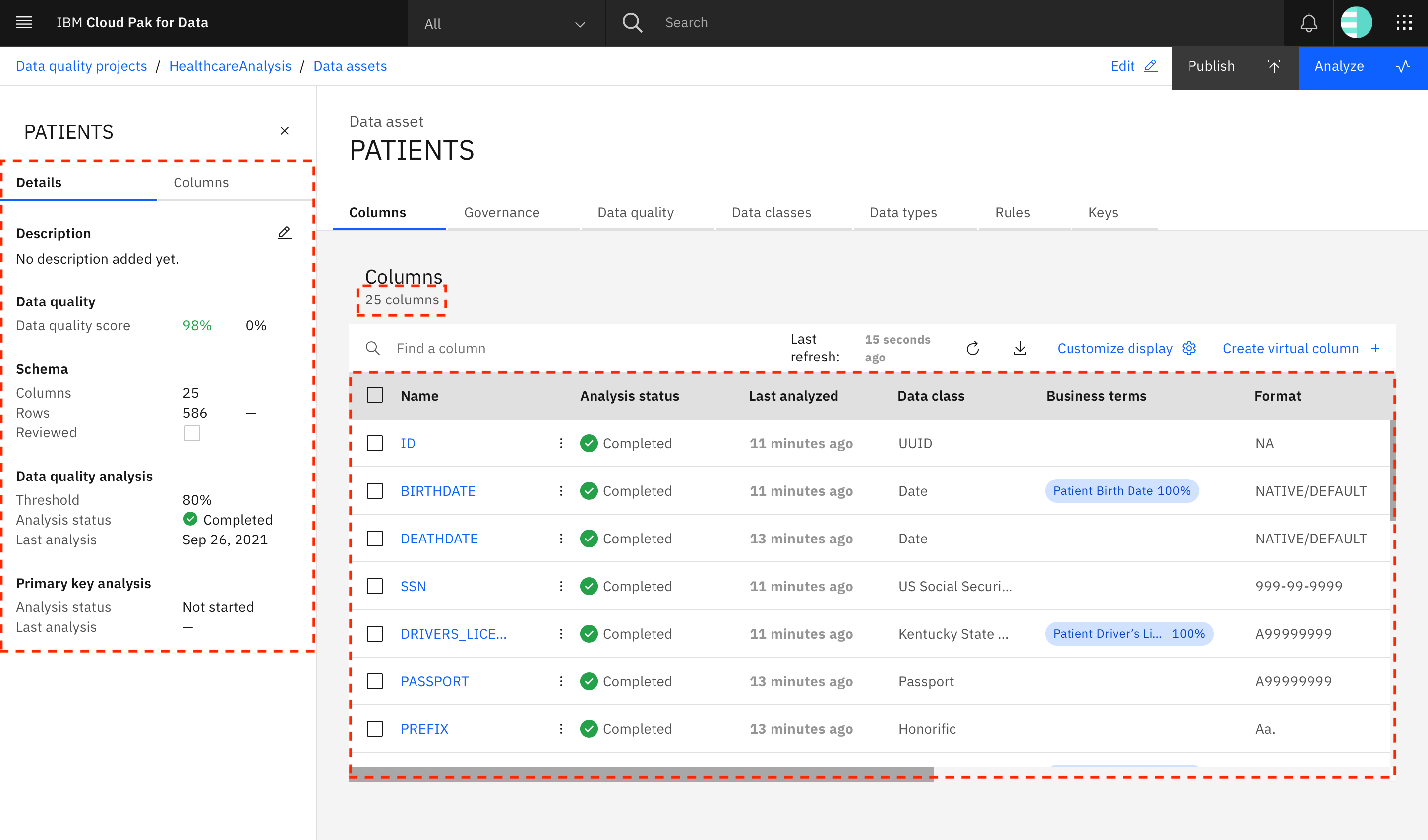
On the Columns tab is information about the columns in the asset. You can see that the discovery process found 25 columns in the PATIENTS data asset. The table provides information regarding the analysis status and last analyzed time of the columns as well as information identified and auto-assigned by the analysis process such as data classes, business terms, format, and data types. Scroll and view all of the information that is present in the table against each record.
The Details panel shows the data quality analysis results, the data quality score, and the status of the primary key analysis. The Columns panel shows the data quality scores for each column in the PATIENTS table.
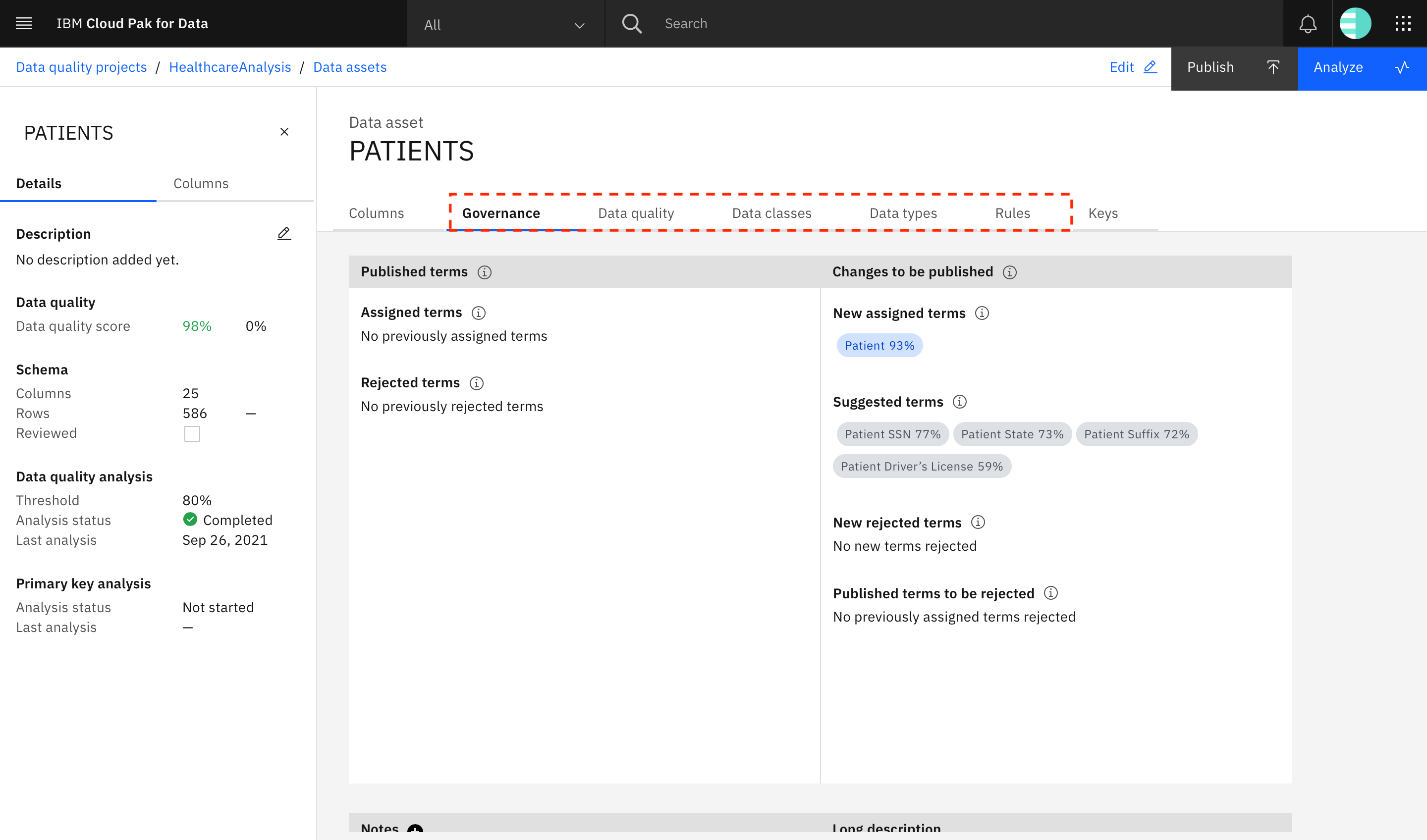
Look through the other tabs.
- The Governance tab has information about suggested business terms for the data asset, and you can assign them or reject previously assigned terms.
- The Data quality tab has information about the data quality score and lists the columns/values that do not satisfy the criteria as specified by the data quality dimensions.
- The Data classes tab has a summary of the data classes that were found and the ones that were selected.
- On the Data types tab is a summary of the types of data found in the data asset.
On the Rules tab is information about rules added to the asset and the rule violations found when running the rules.
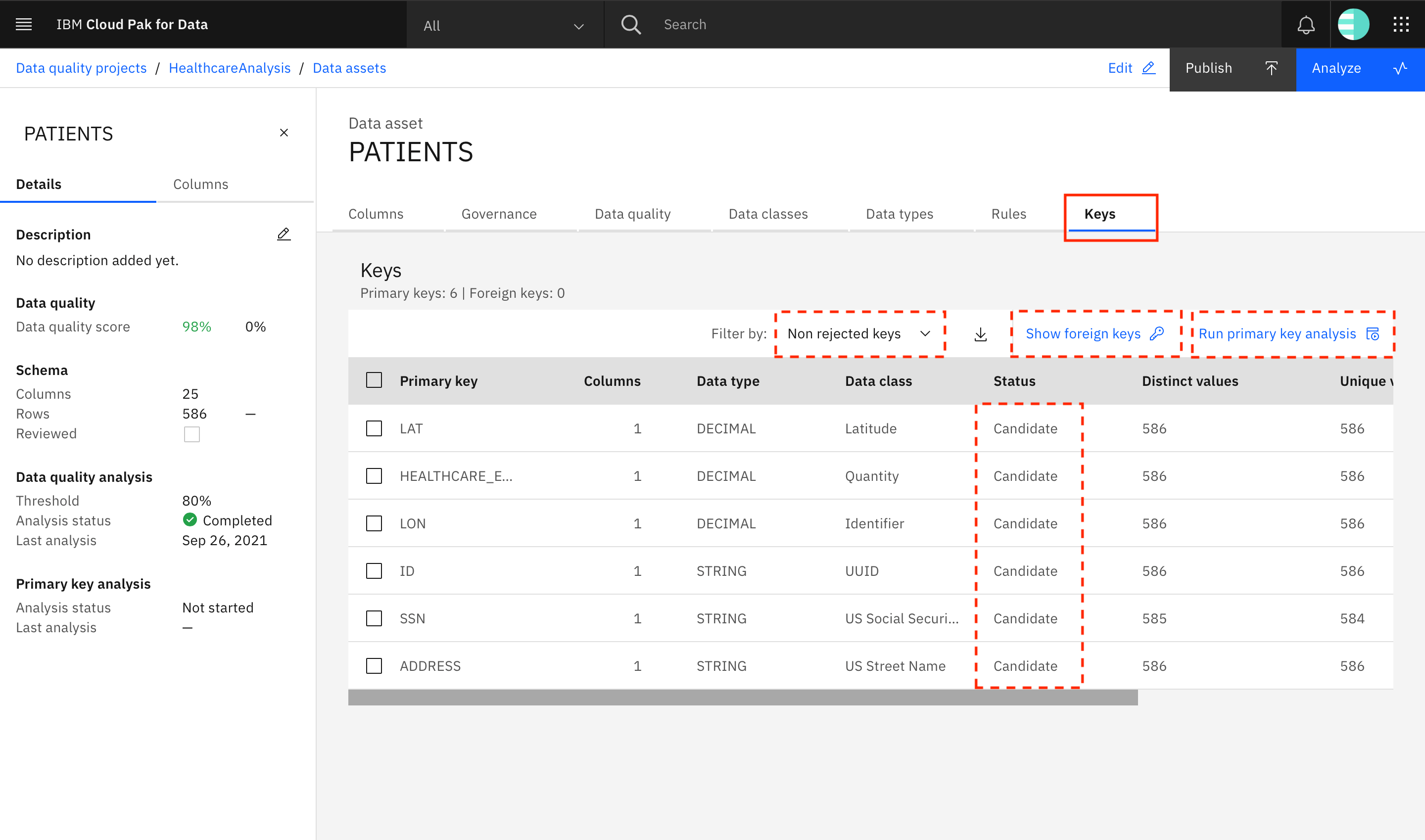
Finally, click the Keys tab. Here, you can see the results of the primary key analysis process. The status column shows that currently there are six columns that were identified as Candidate primary keys. By default, the filter is set to Non rejected keys, meaning that only the Candidate and Selected keys are displayed in the list. You can use the filter to show the rejected keys (currently, there are none).
By clicking Show foreign keys, you see all foreign key relationships that the data asset participates in. (Currently, there are none because the relationship analysis has not been run on the data assets in the project.) Run primary key analysis provides the ability to re-run primary key analysis on this asset.
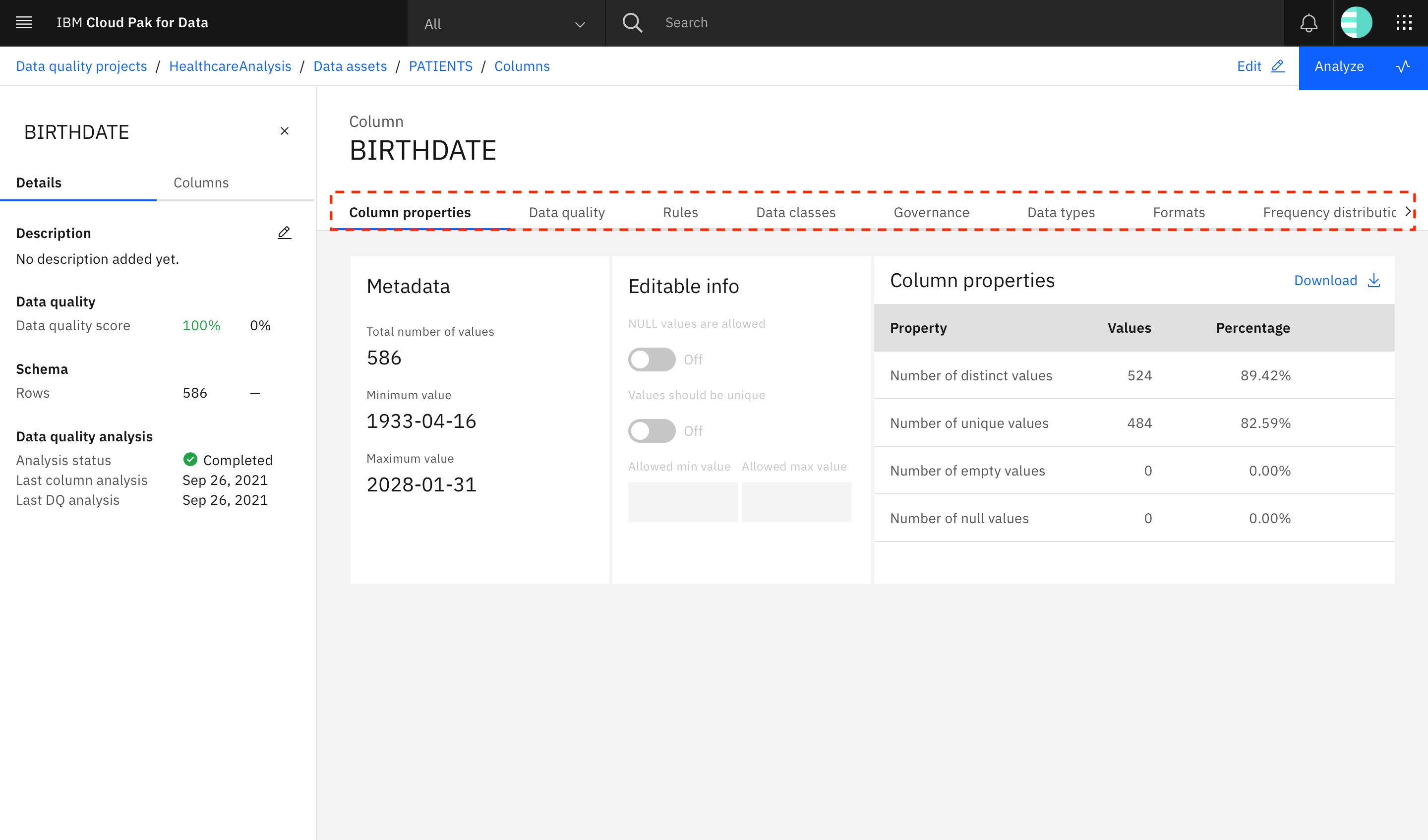
Now, look at one of the columns within the PATIENTS data asset. Go back to the Columns tab, and click BIRTHDATE.
Go through the different tabs to view information about the BIRTHDATE column in the PATIENTS data asset.
- The Column properties tab is metadata about values present in the column.
- The Data quality tab lists the values that do not satisfy the criteria as specified by the data quality dimensions.
- The Rules tab has information about rules added to the asset that are related to the column and the rule violations found when running the rules.
- The Data classes tab specifies the various data classes detected for the column along with the confidence that Watson Knowledge Catalog has for each data class. It also mentions the data class that was selected for the column and lets you change the selected data class.
- The Governance tab has information about suggested business terms for the column and provides the ability to assign or reject previously assigned terms.
- The Data types tab specifies the various data types detected for the column, the confidence that Watson Knowledge Catalog has for each detected data type, and specifies the data type that was selected.
- The Formats tab has information about the different formats found for the data in the column, along with the number of records that adhere to each of the formats.
The Frequency distribution tab, as the name suggests is the frequency distribution of the values in the column.
Summary
In this tutorial, you learned how to use data discovery on the IBM Cloud Pak for Data platform to discover data assets in your data sources. You ran automated discovery on your data assets. Watson Knowledge Catalog identified the governance artifacts for the assets and performed automatic assignment of these artifacts to your data. It then calculated a quality score for your data assets.
In addition to the scores, automated discovery also displays data quality dimension violations, which give you more insight into the reasoning behind the quality scores. Automated discovery identifies and assigns data classes and business terms to assets. In addition, automated discovery identifies and allows updates for data types and formats for each column. Finally, automated discovery provides the ability to identify and select primary keys for data assets as well as foreign key relationships between the data assets.
Note: This tutorial is part of the An introduction to the DataOps discipline series.