Tutorial
Build and extend Docker container images with middleware functions
Adding applications to leverage Docker image layeringArchive date: 2026-01-01
This content is no longer being updated or maintained. The content is provided “as is.” Given the rapid evolution of technology, some content, steps, or illustrations may have changed.To transition an IT environment to the cloud, enterprises are using container technology, primarily Docker containers. This approach helps to streamline resource consumption and further automate operational processes. At the same time, several services are required to support enterprise-grade business applications, that is, the existing middleware functions. Such services can apply to integration, messaging, APIs, or hosting applications in a controlled, managed application server environment.
But, to run a Docker container, you must have an image. This tutorial explains how to create and extend Docker images that contain middleware functions so that you can add applications that leverage Docker image layering.
Inside a Docker image
The concept of having an image for a Docker container is similar to how you must specify an image to start a new virtual machine. However, Docker images are different in the following ways:
- They are "an ordered collection of root file system changes and the corresponding execution parameters for use within a container runtime," according to the Docker image specification.
- They support multiple, stacked layers, where each layer adds its own changes and parameters to the image it is layered on top of.
A Docker image is read-only. When Docker runs a container from an image, it adds a read-write layer on top of the image (by using a union file system) in which an application can then run.
Moreover, each Docker image is, by definition, extensible. You can add more layers to an existing image to create your own. You should design each image in a way that makes it easy to customize it by adding more layers.
When you deploy a new Docker container, you specify the name and tag of the image that you want to use for the container. The Docker host checks if that image is locally available. If it is not available, the Docker host downloads all of the layers that are needed for that particular image. If layers are shared between images, they are never downloaded twice. For example, you want to run a container with WordPress and another container with MySQL. Both containers are based on a base Ubuntu image, and the layers that make up that Ubuntu image are only downloaded once. This split into layers makes Docker images more easily available, because a Docker image is not one large, monolithic file.
Docker images are also completely portable between Docker hosts, regardless of the operating system that the host runs on (even running on bare metal servers), if the host runs on the same hardware architecture. That is, an x86-based Docker image can run only on a Docker host on that architecture. It wouldn't run on, for example, a host that is based on an IBM POWER server.
Although a Docker image can contain only the files that are needed to run an operating system, avoid deploying an "empty image" into a container. A container is expected to represent an application or at least part of an application, for example, a microservice. You should not deploy, for example, a container that is running Ubuntu and then try to remotely log in to it to manually install other software. The Ubuntu image on the Docker hub has been and continues to be one of the most popular images. However, it is typically used as the base for other images that carry higher-level functions in them.
Similarly, a Docker container should also run only one process. That is, each Docker image must define an executable command that runs when the container starts. This command starts the application or service that the container offers. You can specify to pass additional parameters to this command, or define your own command when you start the container as explained in the Docker image customization section.
The Dockerfile
New Docker images are built by using a file, called the Dockerfile, which specifies the following elements, among others:
- The base image that the new image is based on because it inherits all layers of the base image
- Files that need to be copied into the new image
- Network ports that the new image should expose
- Commands, such as installing additional packages, that should be run when building the new image
- Environment variables that can be set when the image is used to start a container
- The command that is run when the container starts
The Dockerfile is passed to the docker build command that builds the new image. The following example shows a simple Dockerfile that defines an image that is based on Ubuntu, exposes port 80, and runs a custom shell script:
FROM ubuntu
EXPOSE 80
COPY myscript.sh /usr/local/bin/
CMD ["myscript.sh"]You can find more realistic examples of Docker images in GitHub. The Docker website and several other websites provide best practices for how to build good Dockerfiles.
By using a Dockerfile, you can add extension points to an image that also serve as a way to customize a container, without needing to build a new image each time. For example, you can pass environment variables into a container at deployment time that can then can influence some of the logic within that container. You can extend and customize the behavior of a container in several ways, such as by using a Dockerfile. For more information about these examples, see the Sample use case section.
Running middleware in containers
A Docker image should represent an application or service, not an operating system. The Docker image exists with a minimal set of operating system libraries in it. A prime example is the Ubuntu image, which is a basic image that is meant to be extended, not run in a container.
Between a basic operating system and an application is an intermediate layer, which is referred to as middleware. The most common examples of middleware are application servers or messaging environments. For example, if you want to take advantage of middleware in the context of a Dockerized environment, you must create Docker images that contain that middleware as additional layers. However, these images are not intended to ultimately be deployed into a container. Instead, you should build them in a way that makes it easy to extend the middleware with an actual application.
The following figure shows how containers use Docker images that consist of multiple layers that cover the operating system and middleware parts, but that ultimately host an application.
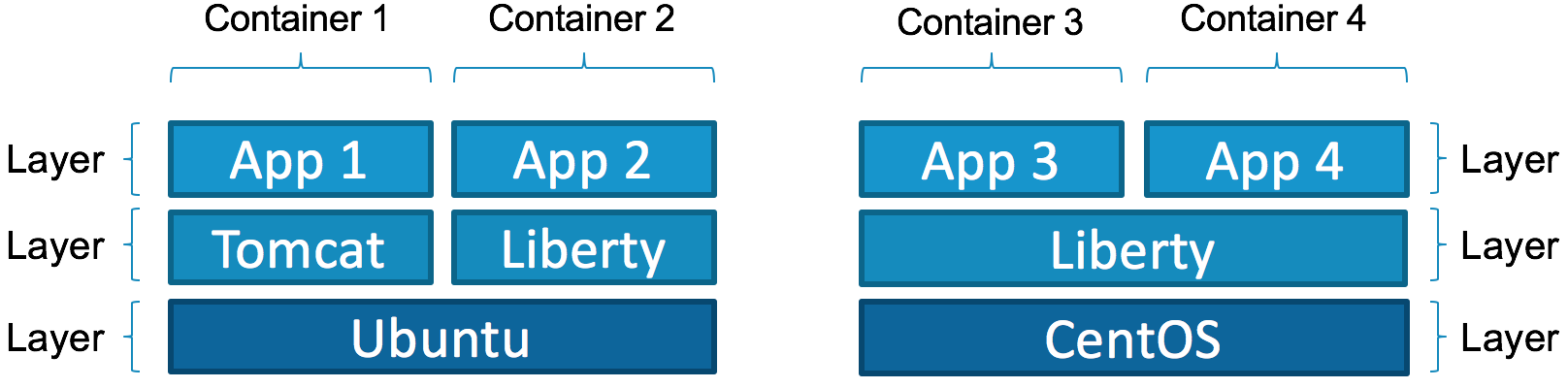
Some middleware Docker images serve a role only as the basis for a container that adds the application. Therefore, you can define two roles that are relevant in this context:
- The middleware provider, who adds the relevant software packages to a base image and possibly does some preliminary configuration
- The application provider, who adds to the middleware image by installing an application and performing any extra configuration that might be needed
Eventually, Docker images for middleware must provide proper extension points that make it easy to add an application. Showing the various means to do so is one of the key points of this tutorial.
Sample use case
To demonstrate this idea of image reuse and extension, consider a series of images that are built one upon the other, progressing from middleware toward an image that is suitable for production application deployment. The IBM WebSphere Liberty and Tradelite sample are used in this depiction. In this scenario, contributions are made by multiple parties. The Docker image is the asset with added value that is relayed to teams or organizations who then further customize the image before they provide it to another team or organization as illustrated in the following figure.
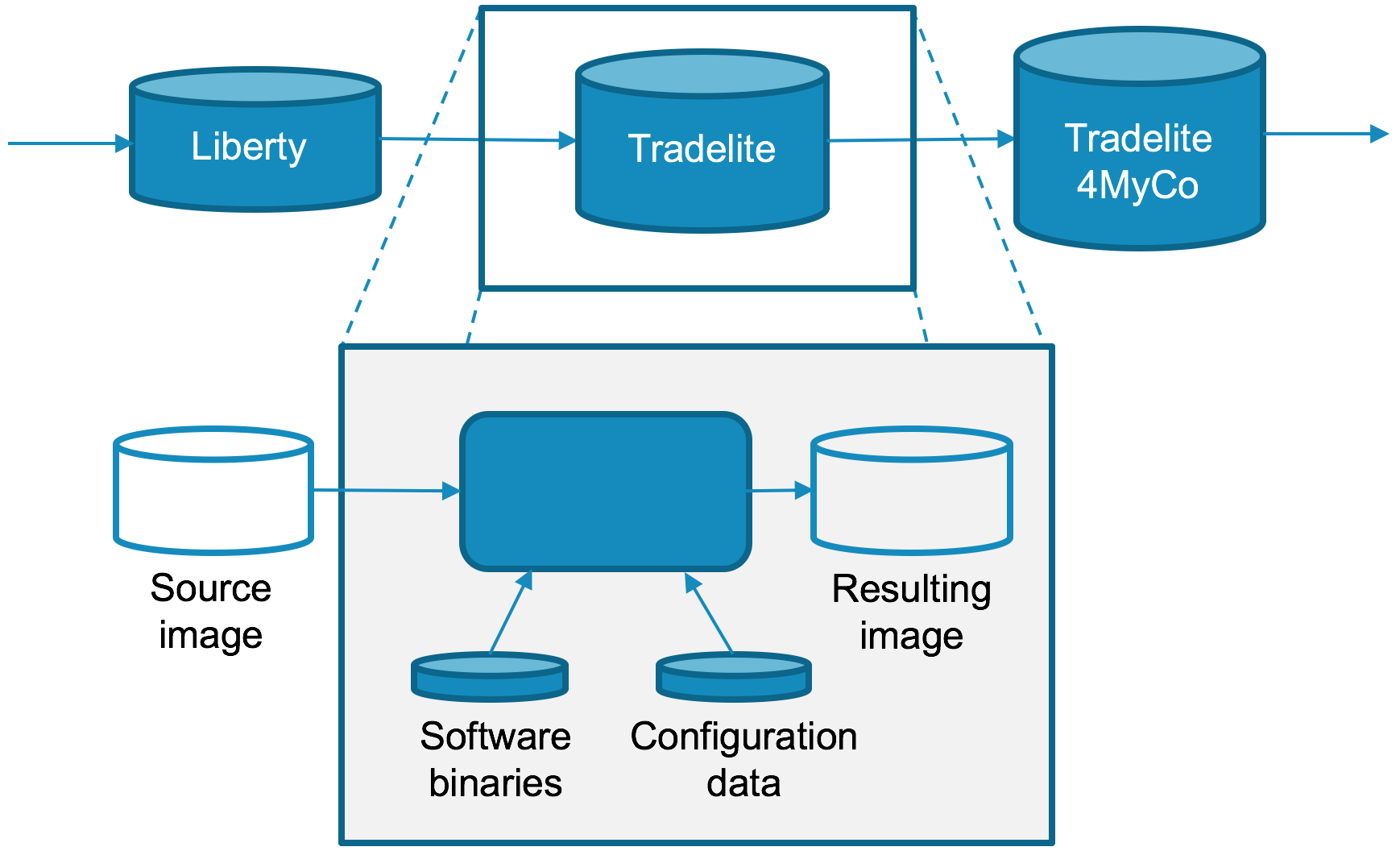
This example uses the following images:
- WebSphere Liberty. This image was built by the IBM team and provides the application server middleware. This image itself is an extension of a base image that contains the required operating system file systems.
- Tradelite. This image is produced by an independent solution vendor. It provides the core application functions while remaining cloud neutral.
- Tradelite4MyCo. This image applicationization specific to the fictional MyCo cloud.
When building an image, an image developer must consider the downstream uses for the image and the target audience. The lifecycle of a Docker image has multiple interjection points that are used in this discovery process: image build, container creation, and container runtime. The next section looks at common use patterns that are related back to these interjection points. Then, these patterns are applied to the example use case.
Docker image customization
Docker provides several ways to manipulate the behavior of the container process, either by providing input to the process itself or by editing the file system content that might be read by the process. In any case, the mechanisms that are applicable to a particular container are dictated either to the unique aspects of either a particular mechanism or the process that is being containerized.
Environment variables
Environment variables represent the most common and flexible means of providing default parameter values that can be overridden later in the next image layers or when the container is created.
To define an environment variable at image build time, use the ENV Dockerfile instruction:
ENV myName="John Doe" myDog=Rex\ The\ Dog
myCat=fluffyIf the same environment variable is specified later in the Dockerfile or in an extending Dockerfile, the previous value is overwritten. Then, a new environment value is established that is persisted into the image. The environment variable can also be set when the container is created:
docker run –e "myName=\"Bob\"Environment variables have several use limitations. First, this mechanism works best for simple data values and can be a burden when passing structured data. A possible workaround is to map from simple variable names to structured content within the container process. A second limitation is that environment variables can be provided at image build time or container creation time, but they cannot be manipulated dynamically after the container is created. If you alter an environment variable at runtime, you must destroy the container and recreate it with a different value. Environment variables have a tendency to be displayed in log files. Therefore, they might not be the best choice for passing secrets to a container process.
Command-line arguments
Docker breaks down what is traditionally regarded as the command line of a process into two parts: the entrypoint and the command. The entrypoint represents the process to be launched, and the command consists of the arguments that are provided to that process. For example, a common entrypoint in a base operating system image is /bin/bash –ccode, and a command line might be ls. The effect of launching such a container is to run the process:
/bin/bash –c lsSimilar to environment variables, the entrypoint and command parameters can be provided by a Dockerfile instruction or when the container is created. However, the command-line interface (CLI) for a particular process is usually well-defined. Therefore, its most common use is to change the target process characteristics rather than to act as a mechanism for sending parameters to a particular container. Some software, such as WebSphere Liberty, recognize few command-line parameters, reserving files to provide both application binary files and configuration data that are related to an application.
Files and volumes
As mentioned previously, a container has a layered file system. You can add files or edit content in an image layer or in a running container instance. These modifications are then recorded when the layer is captured.
The Docker build process provides two mechanisms for adding files to the container file system: ADD and COPY. ADD remains in the instruction set that is understood by Docker build. However, COPY is the preferred instruction because it is use is easier to understand and is considered more transparent in its use.
To use the COPY instruction, specify a source and destination in the Dockerfile:
COPY [source] [destination]Docker also provides data volumes, which have a separate lifecycle from the container itself. Data volumes do not use the layered file system, which is advantageous for data that is frequently read and written. These volumes are used from a container by mounting into the primary layered file system. This mounting obfuscates any layered data that is at that directory point.
You can declare a volume from the Dockerfile by using the VOLUME instruction. A unique feature of declaring the volume from the Dockerfile is that, when a container is created after the VOLUME instruction, the data is copied from the layered container file system into the newly created volume.
Using the VOLUME instruction has several implications:
- Volumes cannot be removed after they are created. If the volume does not make sense to a downstream extension image, defer volume creation to a later time.
- Docker build creates a new container for each instruction in the Dockerfile. The result is the transfer of data from the layered container file system into the new volume, which can degrade Docker build performance after the VOLUME instruction.
- In layers after the VOLUME instruction, the layered file system is no longer accessible. Any files that you add to or modify in the directories in the volume are not preserved.
You can also create volumes by using the Docker volume command or the –v runtime switch:
docker run –v [volume]:[path]Defer volume creation to the time that is closest to its use, whether this means using the Dockerfile instruction in a layer that is closest to the layer to be run or having the operator create the volume.
Applying customizations
You should now have a basic understanding of how Docker persists and uses environment variables, command-line arguments and image layers between image build, container creation, and container runtime. Next, you see how to apply this information in an example scenario.
Tradelite is a Java Enterprise Edition (Java EE) application that requires an application server to provide the required functions. WebSphere Liberty provides the application server capability in this scenario.
Although a single Dockerfile can represent the entire software stack from the base operating system to the application, such usage is often difficult to maintain and does not account for multiple contributions by independent organizations. Instead, the preference is to break the overall Dockerfile instruction set into building blocks. Each block is individually buildable. The output is tagged for reuse, and each Dockerfile and binary image can be owned and maintained in separate source control and registry systems.
Base image selection
A Docker container is merely a process that is started on a host, but with special behaviors attributed to it. One of these behaviors is the visible file system, which is represented by the container image when the host file system is not visible. Because the container process is started after the image file system is mounted, the image file system minimally must contain the target executable file. However, it can contain additional executable files for use from the Dockerfile or from the docker exec command after the container is started. That is, a Docker base image is not an operating system, but it can be a virtual subset that is sufficient to act as though it is an operating system.
For WebSphere Liberty, the process bootstrap is triggered by a shell script and starts a Java Runtime Environment (JRE). To support the shell, you need to select a base image that contains a shell environment. You also need to provide some Linux shared libraries to start the process (such as libpthread, libc, and ld-linux).
The example scenario in this tutorial uses the Liberty Docker image, which you can find in the Docker hub or in IBM Containers. Considering that the container process primarily uses libraries that are maintained with the Linux kernel and are consistent among all well-maintained Linux distributions, we do not need to rebuild this image to select a different base operating system. If this image is reused in other Java EE applications in the target environment, the result is greater consistency between Java EE images and a slightly more efficient use of mass storage and transfer bandwidth.
Declaring volumes
The WebSphere Liberty image has a broad audience. Therefore, an important characteristic of this image is that any actions that are taken in this image can be undone or substituted in a subsequent Dockerfile. As mentioned previously, you cannot remove a volume after you create one. For this reason, the WebSphere Liberty team chose not to declare any volumes, leaving the choice up to the extender or operator instead. Volumes for known transactional data, such as logs, are declared in the final image but can also be deferred to runtime creation.
Adding software binary files and configuration data
In each Dockerfile in our example scenario, we might need to add some software binary files. We can add them to the image by using either the ADD or COPY instructions. Our preference is to use the COPY instruction because of it is less complex and has a familiar syntax.
Adding binary files is generally straightforward. Each layer tends to add more binary files or replaces an existing binary file. Therefore, you should not need to edit a binary file or directly influence its disk content at runtime. Always embed any remote retrieval of software binary files into the image. A running container should not download binary updates, but instead should attempt to keep the binary content idempotent. If the binary file needs to be updated, provide a new image for that purpose.
Configuration data presents difficulties that are less likely to be experienced than with binary data. Should you provide the configuration with the image? Should a subsequent image layer replace configuration data? How is configuration data provided at runtime?
In our example, most of the configuration content is related to the WebSphere Liberty server.xml file and its corresponding set of files. Some of this content must be provided in the next layers. For example, we might need to declare an EAR file and certain deployment attributes that are associated with that EAR file, but other content might be related to the deployment environment, such as database connection information.
Environment variables are slightly easier for an operator to define. Therefore, the operator should define the data by using environment variables. Alternatively, application deployment elements should be provided at the same time as the binary files. These files are configured by editing or providing the server.xml content in the Docker build.
A custom server.xml file is then added by using the Dockerfile:
COPY ./server.xml /opt/ibm/wlp/usr/servers/defaultServer/server.xmlThe server.xml file configures the application EAR file and shows the operator environment variables for the database:
<application name="tradelite" context‑root="/" location="trade.war" type="war"/>
<dataSource id='db2' jdbcDriverRef='db2‑driver' jndiName='jdbc/TradeDataSource' statementCacheSize='30' transactional='true'>
<properties.db2.jcc id='db2‑props' databaseName='${env.DB2_DATABASE}'
user='DB2_USER' password='${env.DB2_PASS}'
portNumber='${env.DB2_PORT}' serverName='${env.DB2_HOST}'/>
</dataSource>
<jdbcDriver id='db2‑driver' libraryRef='db2‑library'/>
<library id='db2‑library'>
<fileset id='db2‑fileset' dir='${server.config.dir}/lib' includes='db2jcc.jar'/>
</library>The server.xml file shows the following environment variables to the operator:
- DB2_USER
- DB2_PASS
- DB2_PORT
- DB2_HOST
Although environment variables are not ideal for passing secrets, in this case, the environment variables were advantageous in prioritizing parallelism between the other configuration settings and simplicity over obfuscation of the password parameter in a file.
Location of the environment-specific configuration in the image
The environment variable mechanism works well for simple values, but what about the complex runtime configuration of structural data? An example of this type of data that applies to WebSphere Liberty is a Lightweight Directory Access Protocol (LDAP) configuration and Transport Layer Security (TLS) configuration. It might be possible to map some of this data to environment variables as done previously. However, TLS secrets and certificates in particular are almost always provided through a file mechanism.
By far the easiest way to deal with file content is to add it directly to the image. However, this might disturb the cloud portability of the application image and show a vulnerability risk if secret data is added to the image. Docker registries are not suitable stores for secret data, such as server private keys. Always provide this data directly at runtime.
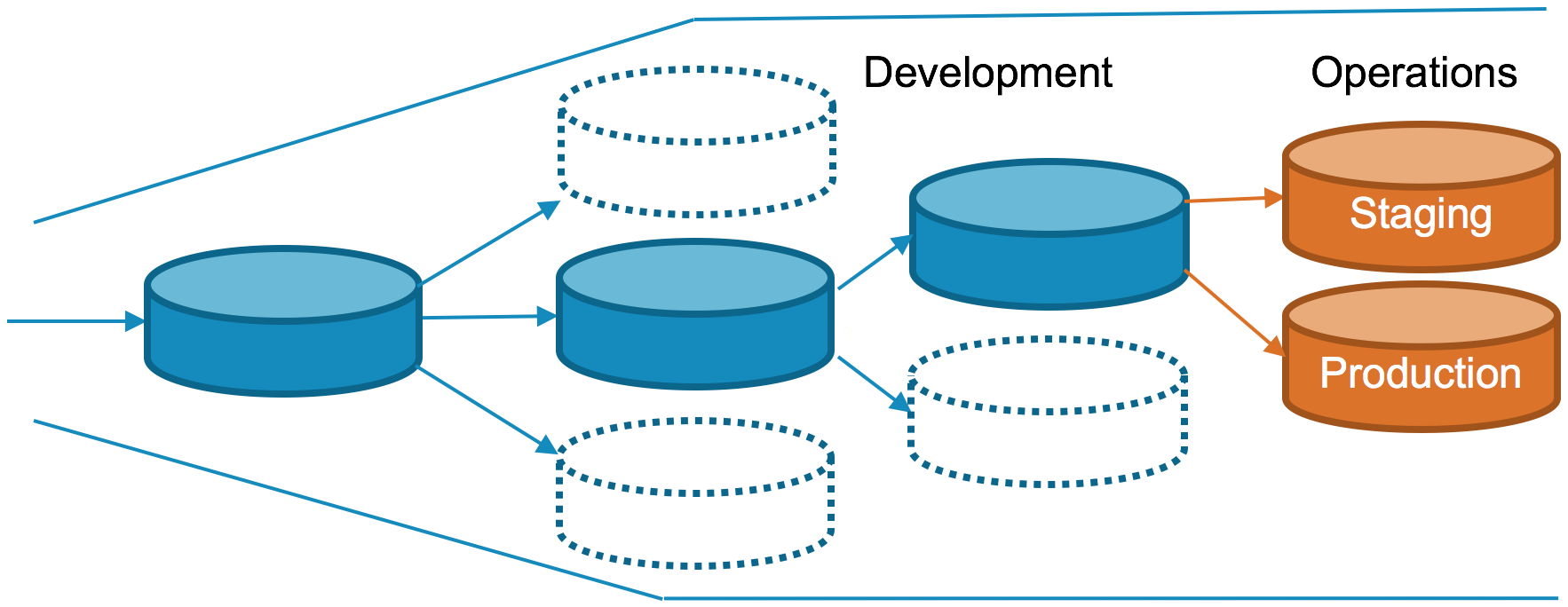
In each situation, you need to determine whether to provide complex configuration data by this image extension mechanism or by using a runtime volume. Regardless of the approach that is suitable for the current situation, you can reach a point of overextending the Docker image. That is, never tightly bind an image so tightly to a particular usage that a separate image is required for each operational instance as illustrated in the following figure.
Conclusion
In this tutorial, you learned how to build Docker images, especially in the context of using middleware to apply enterprise-level functions to an application. These middleware Docker images must be extensible from the ground up, considering that they will always serve as an intermediate format to which you can add concrete applications.
Several mechanisms exist for you to extend a Docker image. For example, you can use a Dockerfile to create a new Docker image on top of an existing one and use various ways to change and influence the resulting Docker container. Ideally, you will always use a mix of these mechanisms, based on the practices and guidance that are provided in this tutorial.