Tutorial
Use IBM SPSS Statistics to analyze COVID-19 data
Learn how you can use IBM SPSS Statistics for a variety of descriptive and predictive analyses of data, such as those generated by the COVID-19 pandemicYou can use IBM SPSS Statistics for various descriptive and predictive analyses of data, such as those generated by the COVID-19 pandemic. SPSS Statistics features an easy-to-use graphical user interface (GUI), but almost all of what the GUI allows you to do is performed behind the scenes by a powerful command syntax language. The command syntax provides flexible programming of analyses, the ability to save instructions for the reproduction of future outcomes, and allows for adaptation to new data or problems. For information regarding SPSS Statistics command syntax, see Working with Command Syntax.
The data for this example is from the full_data.csv file that was obtained from the highly informative Coronavirus Disease (COVID-19) – Statistics and Research website. This site contains a substantial amount of useful information on data and other aspects of the COVID-19 pandemic. The data is maintained by Hannah Ritchie, and was downloaded directly from Coronavirus Source Data.
The full_data.csv file was downloaded on April 1, 2020, and contains COVID-19 data through the end of March (based on the timelines maintained by the European Centre for Disease Prevention and Control). Refer to the notes at Coronavirus Disease (COVID-19) – Statistics and Research for details regarding exact dates. The data values presented here might not exactly match data from other sources (for various reasons).
Loading the data file into SPSS Statistics
Because the full_data.csv data file is not a native SPSS Statistics file (*.sav), the file must first be imported into the application. Instructions for importing *.csv files through the GUI can be found at Reading CSV Files.
Command syntax can also be used to read the data into SPSS Statistics.
Open a new Syntax Editor session in SPSS Statistics by selecting File > New > Syntax.
Copy the following syntax into the Syntax Editor dialog box.
PRESERVE. SET DECIMAL DOT. GET DATA /TYPE=TXT /FILE="/<path>/full_data.csv" /ENCODING='UTF8' /DELIMITERS="," /QUALIFIER='"' /ARRANGEMENT=DELIMITED /FIRSTCASE=2 /DATATYPEMIN PERCENTAGE=95.0 /VARIABLES= date AUTO location AUTO new_cases AUTO new_deaths AUTO total_cases AUTO total_deaths AUTO /MAP. RESTORE. CACHE. EXECUTE. DATASET NAME DataSet1 WINDOW=FRONT.Change
<path>on the/FILEsubcommand of theGET DATAcommand to reference the directory where the full_data.csv file is located on your system.Highlight the previous syntax, and click the green Run Selection icon on the toolbar (you can also select Run > Selection from the menu).
The file structure is fairly simple. It contains a date variable, a location variable (which indicates the country or territory), and variables that provide daily counts of new recorded cases, newly recorded deaths, total recorded cases, and total recorded deaths. In addition to data for the entire world, there is data for 199 specific locations where at least one COVID-19 case has been reported.
The file contains a total of 7996 rows (referred to as records or cases). There are 92 records for the world, and variable numbers for specific locations. Some of the locations did not have cases reported until well after the time period covered by the data (which begins December 31, 2019, for some locations).
Converting the date variable
Because the date variable in the data file does not match any of the many defined SPSS Statistics date formats, you must edit the date variable information to convert it to a format that SPSS Statistics recognizes. The following commands replace dashes in the variable strings with slashes, change the variable type from string to date, assign the variable to an ordinal measurement level, add variable labels to the variables, and provide counts with the same format (0 decimals).
Note: The ordinal measurement level for the dates is useful because it provides variable flexibility when charting (it maintains the sorting order, but marks it as categorical, which some chart functions require).
Copy the following syntax into the Syntax Editor dialog box.
COMPUTE date=REPLACE(date,'-','/'). EXECUTE. ALTER TYPE date (A10 = SDATE10). VARIABLE LEVEL date (ORDINAL). VARIABLE LABELS date 'Date' /location 'Location' /new_cases 'New Cases' /new_deaths 'New Deaths' /total_cases 'Total Cases' /total_deaths 'Total Deaths'. FORMATS new_cases TO total_deaths (F8.0).Highlight the previous syntax, and click the green Run Selection icon on the toolbar (you can also select Run > Selection from the menu).
Analyzing COVID-19 data by location
SPSS Statistics offers multiple options for analyzing data separately for each location. If you want to perform the same analysis on each location, you can use the SPLIT FILE command to submit data to a statistical procedure (one location at a time). The command can produce completely separate output, or results for locations stacked in output tables. To focus on a particular subset of data (such as for the world or the United States), you can filter out all other locations, or create a new data set that contains only the location of interest.
The following commands create a data set that contains data solely for the United States.
Copy the following syntax into the Syntax Editor dialog box.
DATASET ACTIVATE DataSet1. DATASET COPY US. DATASET ACTIVATE US. FILTER OFF. USE ALL. SELECT IF (location = 'United States'). EXECUTE.Highlight the previous syntax, and click the green Run Selection icon on the toolbar (you can also select Run > Selection from the menu).
Generating a histogram chart
The following commands generate a histogram chart of new COVID-19 cases by day. The ordinal categorical measurement level for the date variable is required to produce the histogram.
Note: The following commands invoke the SPSS Statistics Chart Builder charting engine. For more information, see Building Charts (for the GUI), or Introduction to GPL (for command syntax).
Copy the following syntax into the Syntax Editor dialog box.
GGRAPH /GRAPHDATASET NAME="graphdataset" VARIABLES=date new_cases MISSING=LISTWISE REPORTMISSING=NO /GRAPHSPEC SOURCE=INLINE. BEGIN GPL SOURCE: s=userSource(id("graphdataset")) DATA: date=col(source(s), name("date"), unit.category()) DATA: new_cases=col(source(s), name("new_cases")) GUIDE: axis(dim(1), label("Date")) GUIDE: axis(dim(2), label("New Cases")) GUIDE: text.title(label("Simple Histogram of New Cases by date")) SCALE: linear(dim(2), include(0)) ELEMENT: interval(position(date*new_cases), shape.interior(shape.square)) END GPL.Highlight the previous syntax, and click the green Run Selection icon on the toolbar (you can also select Run > Selection from the menu). The resulting histogram chart displays in the SPSS Statistics Output Viewer.
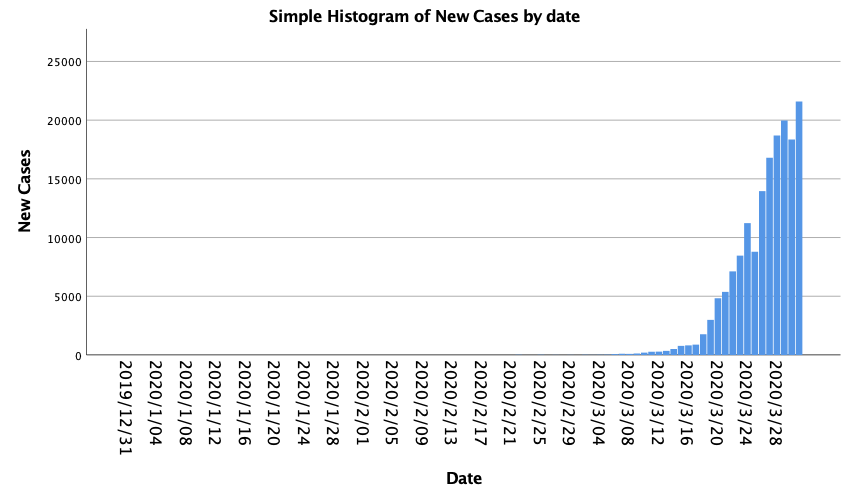
Generating a scatterplot chart
The data can also easily be visualized by using a scatterplot of new cases versus dates, as shown in the following code.
Copy the following syntax into the Syntax Editor dialog box.
GGRAPH /GRAPHDATASET NAME="graphdataset" VARIABLES=date new_cases MISSING=LISTWISE REPORTMISSING=NO /GRAPHSPEC SOURCE=INLINE /FITLINE TOTAL=NO. BEGIN GPL SOURCE: s=userSource(id("graphdataset")) DATA: date=col(source(s), name("date"), unit.category()) DATA: new_cases=col(source(s), name("new_cases")) GUIDE: axis(dim(1), label("Date")) GUIDE: axis(dim(2), label("New Cases")) GUIDE: text.title(label("Simple Scatter of New Cases by date")) SCALE: linear(dim(2), include(0)) ELEMENT: point(position(date*new_cases)) END GPL.Highlight the previous syntax, and click the green Run Selection icon on the toolbar (you can also select Run > Selection from the menu). The resulting scatterplot chart displays in the SPSS Statistics Output Viewer.

Note: Both of these graphs were generated by using the SPSS Statistics Chart Builder GUI. The GPL (Graphics Programming Language) used here is based on Leland Wilkinson's Grammar of Graphics, and is extremely powerful and flexible.
Advanced features
If you're new to data modeling, SPSS Statistics provides options that make it easy to get started with more complex methods, such as time series modeling and nonlinear regression.
Time Series Modeler
The TSMODEL command can be accessed through a Time Series Modeler GUI, and includes an Expert Modeler mode that attempts to find the best model for a given series. Expert Modeler also has an automatic outlier detection capability. The following example lets Expert Modeler select a model for the new cases series and predicts it 30 days beyond the existing data.
Copy the following syntax into the Syntax Editor dialog box.
PREDICT THRU 122. TSMODEL /MODELSUMMARY PRINT=[MODELFIT] /MODELSTATISTICS DISPLAY=YES MODELFIT=[ SRSQUARE] /MODELDETAILS PRINT=[ PARAMETERS] /SERIESPLOT OBSERVED FORECAST /OUTPUTFILTER DISPLAY=ALLMODELS /SAVE PREDICTED(Predicted) /AUXILIARY CILEVEL=95 MAXACFLAGS=24 /MISSING USERMISSING=EXCLUDE /MODEL DEPENDENT=new_cases PREFIX='Model' /EXPERTMODELER TYPE=[ARIMA EXSMOOTH] /AUTOOUTLIER DETECT=ON.Highlight the previous syntax, and click the green Run Selection icon on the toolbar (you can also select Run > Selection from the menu). The resulting Time Series Modeler tables and chart display in the SPSS Statistics Output Viewer.


The rather complicated ARIMA (autoregressive integrated moving average) model with seven outliers fitted by the TSMODEL procedure's Expert Modeler fits the observed data almost perfectly, but eventually begins to predict a straight line increase in new cases forever (which obviously cannot happen). The model is also
difficult to interpret.
In the early stages of an epidemic or pandemic, the growth in new cases is often well-modeled as an exponential function of time. Although there's a date variable in the data set, dates in SPSS Statistics are expressed in seconds since the beginning of the Gregorian calendar, so it's easier to work with a metric like days for interpreting most models.
The following example computes a Day variable for each case in the data set using a useful $CASENUM system variable that indexes sequential cases.
Copy the following syntax into the Syntax Editor dialog box.
COMPUTE Day=$CASENUM. EXECUTE.Highlight the previous syntax, and click the green Run Selection icon on the toolbar (you can also select Run > Selection from the menu).
Nonlinear regression
Next, we fit a nonlinear regression model using an exponential function of the number of days. This model type requires complete specification of the model's functional form, including parameter naming and starting value provisioning. The model we fit has two parameters, a b0 intercept, and a b1 growth parameter that is raised to the power of time in days.
Copy the following syntax into the Syntax Editor dialog box.
MODEL PROGRAM b0=.1 b1=1.2. COMPUTE PRED=b0 * b1 ** Day. NLR new_cases /SAVE PRED.Highlight the previous syntax, and click the green Run Selection icon on the toolbar (you can also select Run > Selection from the menu).


This model also fits the data quite well, with an R^2 value above 0.96. The value of the b1 growth parameter is approximately 1.159. Taking the ratio of the logarithm of 2, divided by the logarithm of this value, gives us the predicted doubling time in days (which is approximately 4.7). According to this model, the results mean that on average, new cases are doubling approximately every 4.7 days.
Let's see how the forecasts from the two models compare. The SUMMARIZE command lists out the days, new cases, and predictions and forecasts from the two models.
Copy the following syntax into the Syntax Editor dialog box.
SUMMARIZE /TABLES=Day new_cases Predicted_new_cases_Model_1 PRED /FORMAT=VALIDLIST NOCASENUM NOTOTAL /TITLE='Case Summaries' /FOOTNOTE 'Last two columns are predictions and forecasts from time series and exponential '+ 'nonlinear regression models.' /MISSING=VARIABLE /CELLS=NONE.Highlight the previous syntax, and click the green Run Selection icon on the toolbar (you can also select Run > Selection from the menu).





Summary
Both models forecast eternal growth in the number of new cases, but the forecasts from the exponential nonlinear regression model grow explosively, predicting over two million new cases per day by the end of April!
A famous statistician has often been quoted or paraphrased as saying that all models are wrong, but some are useful. Neither of these models are correct, but the simpler exponential model is known by epidemiologists to provide a good approximation to the behavior of viral infections when left unchecked (that is, until so many people become infected that the virus runs out of new people to infect). This is why extreme, and for many of us, unprecedented, measures are being taken to battle the COVID-19 pandemic.
Your challenge in the SPSS Statistics version of the IBM Call for Code is to use SPSS Statistics, along with any fully publicly available data, to build models and model visualizations that aid in the understanding of the course of the COVID-19 pandemic and the effects of our responses to the coronavirus.