Tutorial
How to use Watson Text to Speech features
Learn how to get your own speech with specific customizationArchive date: 2023-07-13
This content is no longer being updated or maintained. The content is provided “as is.” Given the rapid evolution of technology, some content, steps, or illustrations may have changed.The IBM Watson Text to Speech service converts written text to natural-sounding speech to provide speech-synthesis capabilities for applications. It gives you the freedom to customize your own preferred speech in different languages.
This cURL-based tutorial can help you get started quickly with the service.
Learning objectives
This guide is for new developers who want to understand more about the Watson Text to Speech service and its features.
Prerequisites
Before beginning this tutorial, you'll need:
- An IBM Cloud account: If you do not have an IBM Cloud account, you can create one here.
- A Java IDE: I used Eclipse.
- Create a Java project and import the Watson Java SDK.
Estimated time
Completing this tutorial should take approximately 15 minutes.
Steps
Create your first speech (Synthesis)
To be able to call the Text to Speech service from your code you will need to create the service and get the service credentials. To create the service, click here.
Name the service (or leave default), select the region, and click Create.
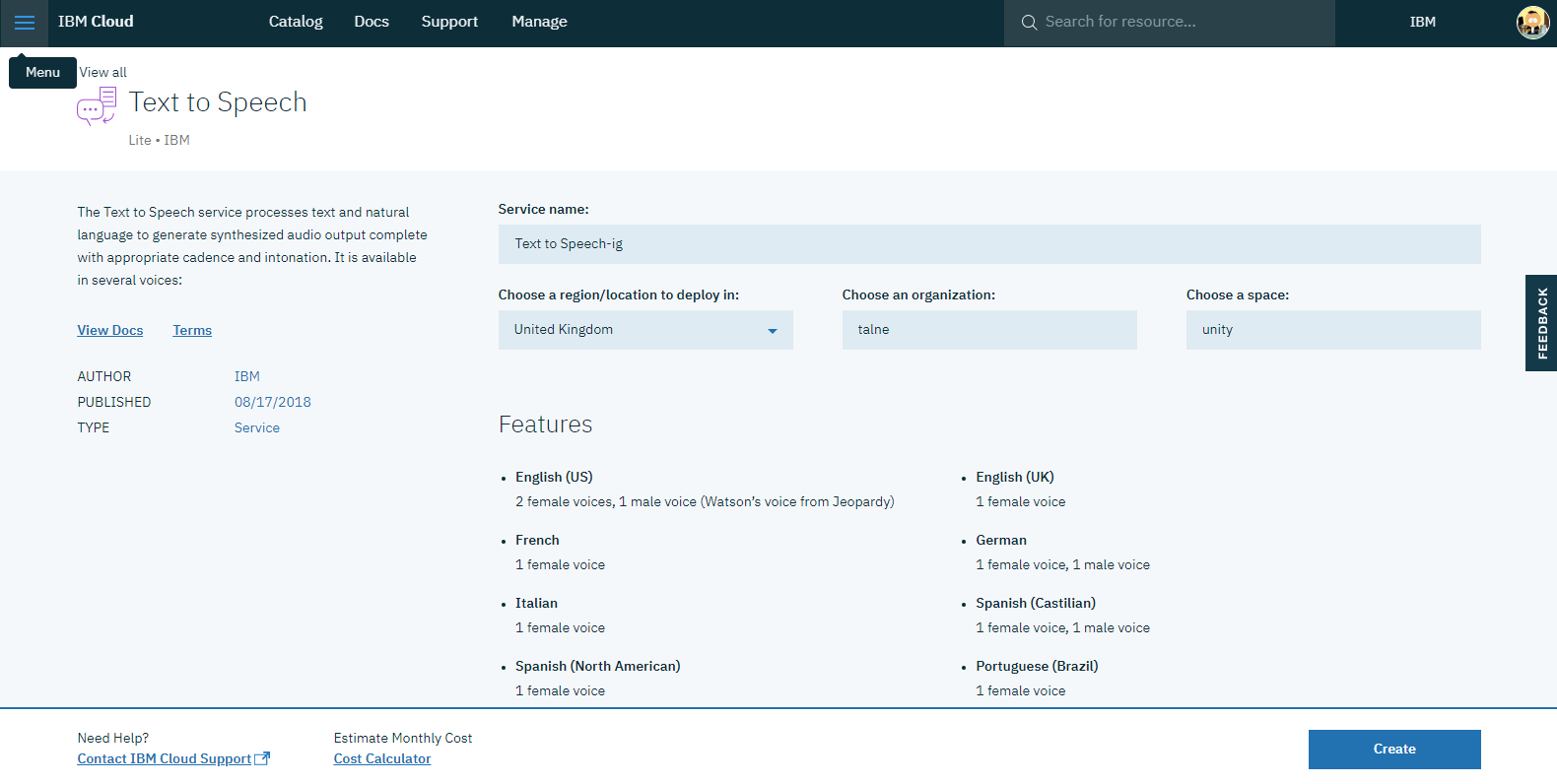
You are redirected to the service page, and there you will find the credentials that you need (username and password). Copy them for later use.
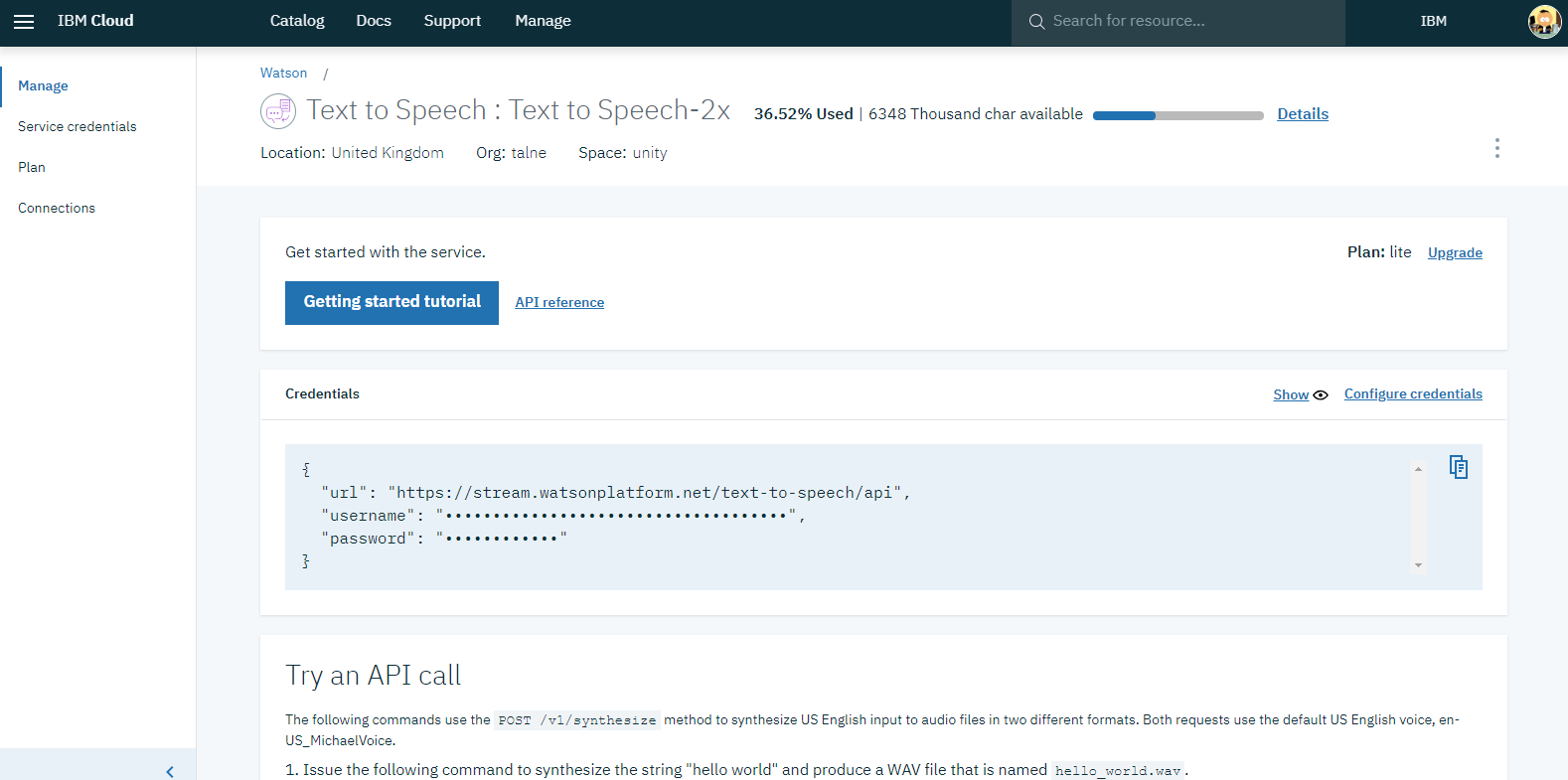
Copy and paste the following code to your .java file. Paste the credentials in the right place, and press Run.
import java.io.FileOutputStream; import java.io.IOException; import java.io.InputStream; import java.io.OutputStream; import com.ibm.watson.developer_cloud.text_to_speech.v1.TextToSpeech; import com.ibm.watson.developer_cloud.text_to_speech.v1.model.SynthesizeOptions; import com.ibm.watson.developer_cloud.text_to_speech.v1.util.WaveUtils; public class Main { public static String username = "{username}"; public static String password = "{password}"; public static void main(String[] args) { TextToSpeech textToSpeech = new TextToSpeech(); textToSpeech.setUsernameAndPassword(username, password); try { SynthesizeOptions synthesizeOptions = new SynthesizeOptions.Builder() .text("Hello World!") .accept("audio/wav") .voice("en-US_AllisonVoice") .build(); InputStream inputStream = textToSpeech.synthesize(synthesizeOptions).execute(); InputStream in = WaveUtils.reWriteWaveHeader(inputStream); OutputStream out = new FileOutputStream("test.wav"); byte[] buffer = new byte[1024]; int length; while ((length = in.read(buffer)) > 0) { out.write(buffer, 0, length); } out.close(); in.close(); inputStream.close(); } catch (IOException e) { e.printStackTrace(); } } }Go to the project folder (the default is: C:\Users\user_name\workspace\WatsonCheck). There you'll find the test.wav file that the service created for the text. Click it.
Understand SSML
The Speech Synthesis Markup Language (SSML) is an XML-based markup language that provides annotations of text for speech-synthesis applications. SSML gives developers of speech applications a standard way to control aspects of the synthesis process by enabling you to specify pronunciations, volume, pitch, speed, and other attributes through markup. The elements are available for all supported languages.
Let's try an example. Copy the following code and replace it with the "Hello World!".
"<speak version=\"1.0\"> " +
"Different sized <break strength=\"none\">no pause</break>" +
"Different sized <break strength=\"x-weak\">x-weak pause</break>" +
"Different sized <break strength=\"weak\">weak pause</break>" +
"Different sized <break strength=\"medium\">medium pause</break>" +
"Different sized <break strength=\"strong\">strong pause</break>" +
"Different sized <break strength=\"x-strong\">x-strong pause</break>" +
"Different sized <break time=\"1s\">one-second pause</break>" +
"Different sized <break time=\"1500ms\">1500-millisecond pause</break>" +
"</speak>"
This is an example on the <break> element. As you can hear, it gives you different break times between sentences. A second example you can try is with the <emphasis> element. To try this, replace the text with the following code.
"<speak version=\"1.0\">" +
"<emphasis> I am sorry, I know how it feels.</emphasis>" +
"</speak>"
Learn about Expressive SSML
By default, the Text to Speech service synthesizes text in a neutral declarative style. The service extends SSML with an <express-as> element that produces expressiveness by converting text to synthesized speech in various speaking styles. The element is analogous to the SSML element <say-as>, which specifies text normalization for formatted text such as dates, times, and numbers. This feature is only supported in the US English Allison voice.
There are three types of expressions: GoodNews, Apology, and Uncertainty. You can replace the text again with the following code to test them.
"<speak>" +
"I have been assigned to handle your order status request." +
"<express-as type=\"Apology\">" +
"I am sorry to inform you that the items you requested are backordered." +
"We apologize for the inconvenience." +
"</express-as>" +
"<express-as type=\"Uncertainty\">" +
"We don't know when the items will become available. Maybe next week," +
"but we are not sure at this time." +
"</express-as>" +
"<express-as type=\"GoodNews\">" +
"But because we want you to be a satisfied customer, we are giving you" +
"a 50% discount on your order!" +
"</express-as>" +
"</speak>\""
Learn about Voice transformation SSML
The Text to Speech service, like most speech synthesis systems, can speak in only a limited number of voices. Moreover, some languages offer only one or two voices. To expand the range of possible voices, the service extends SSML with a <voice-transformation> element. You can use this element to realize different virtual voices by controlling aspects of a default voice. There are built-in transformations that you can use such as "Young" or "Soft". To try it, use the following code.
"<voice-transformation type=\"Young\" strength=\"80%\">" +
"I am just a young little girl" +
"</voice-transformation>"
As you can hear, it's not perfect, but you can make it much better if you tune it yourself with the custom attributes (pitch, breathiness, timbre, and so on).
Using the example of Granny voice, replace the text with the following code.
"<voice-transformation type=\"Custom\" glottal_tension=\"-27%\" breathiness=\"18%\" pitch=\"-19%\" pitch_range=\"0%\" timbre_extent=\"100%\" rate=\"-57%\" hoarseness=\"23%\" growl=\"0%\" tremble=\"86%\" timbre=\"map{400_400.0_1200_1200.0_3000_3000.0_4000_4000}\">Can you help this old lady?</voice-transformation>"
You can also create a new transformation by yourself, but the following code gives you a few more examples that you might like to try.
Giant Voice :
text = "<voice-transformation type=\"Custom\" glottal_tension=\"-10%\" breathiness=\"-67%\" pitch=\"-70%\" pitch_range=\"0%\" timbre_extent=\"100%\" rate=\"-50%\" hoarseness=\"0%\" growl=\"0%\" tremble=\"0%\" timbre=\"map{300_165.0_900_630.0_1800_1440.0_4000_4000}\">How are you my little friend? I am the giant of the north</voice-transformation>"
voice = "en-US_MichaelVoice"
Dwarf Voice :
text = "<voice-transformation type=\"Custom\" glottal_tension=\"-17%\" breathiness=\"-12%\" pitch=\"65%\" pitch_range=\"20%\" timbre_extent=\"100%\" rate=\"12%\" hoarseness=\"0%\" growl=\"0%\" tremble=\"0%\" timbre=\"map{300_490.0_900_1191.0_1800_2370.0_4000_4000}\">I am a little dwarf, what do you want from me? I dont have any gold.</voice-transformation>"
voice = "en-US_MichaelVoice"
Witch Voice :
text = "<voice-transformation type=\"Custom\" glottal_tension=\"-87%\" breathiness=\"52%\" pitch=\"-93%\" pitch_range=\"79%\" timbre_extent=\"100%\" rate=\"-55%\" hoarseness=\"0%\" growl=\"0%\" tremble=\"0%\" timbre=\"map{400_732.5_1200_1784.0_3000_3728.0_4000_4000}\">I put a spell on you, and now you're mine</voice-transformation>"
voice = "en-US_AllisonVoice"
Synchronous and asynchronous requests
The Java SDK supports both synchronous (blocking) and asynchronous (non-blocking) execution of service methods. All service methods implement the
ServiceCallinterface.To call a method synchronously, use the
executemethod of theServiceCallinterface. You can call theexecutemethod directly from an instance of the service (like I did in this guide).To call a method asynchronously, use the
enqueuemethod of theServiceCallinterface to receive a callback when the response arrives. TheServiceCallbackinterface of the method's argument providesonResponseandonFailuremethods that you override to handle the callback.
textToSpeech.method(parameters).enqueue(new ServiceCallback<ReturnType>() {
@Override public void onResponse(ReturnType response) {
. . .
}
@Override public void onFailure(Exception e) {
. . .
}
});
Summary
After you have learned the basics of the Text to Speech service, you can explore more. The Resource links give you resources to help you build your own awesome speaking bot.