Article
The PowerHA for AIX (formerly HACMP) cheat sheet
Building a redundant environment for high availability with AIXThere are some types of computing environments in which you can't afford downtime — the applications and data are so important that if one machine dies, you want another to be able to pick up and immediately take over. Fortunately, in IBM® AIX®, a special piece of software called PowerHA can provide redundancy and high availability to meet these needs. This article provides an introduction to PowerHA and shows how to set up and configure a simple two-node cluster.
PowerHA at work
PowerHA is designed to keep resources highly available with minimum downtime by gathering resources in ways that allow multiple IBM System p servers to access them. PowerHA manages disk, network, and application resources logically, passing control to individual machines based on availability and preference. From a systems administration point of view, the main concept behind PowerHA is to keep everything as redundant as possible to ensure that there is high availability at all levels.
Figure 1 below illustrates a simple PowerHA configuration.
Figure 1. Simple PowerHA configuration
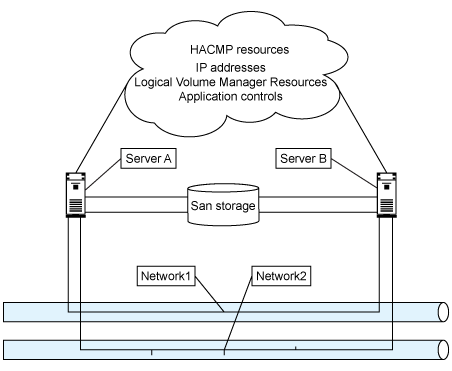
Here, two System p servers share a common set of SAN storage and communicate on two networks. They share between them a set of IP addresses, some Logical Volume Manager (LVM) resources, and application controls — all managed by PowerHA.
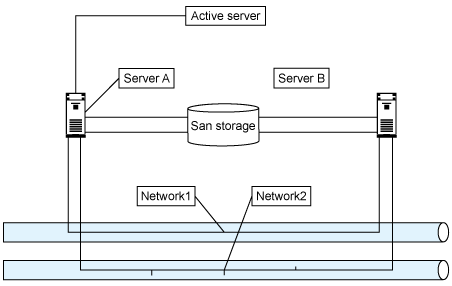
One of these servers is considered to be "active" and is in control of these resources, while the other is idle and sits ready in case it is needed, as shown in Figure 2.
Figure 2. Active and idle servers
When a problem occurs with the availability of some of the physical resources, such as some wires being accidentally unplugged, PowerHA senses the errors and makes the other server take over. There is a momentary pause in the availability of the resources, but then everything comes up as though it were on the original machine, and no one can tell the difference, as shown in Figure 3.
Figure 3. PowerHA controls failover in the event of a resource failure
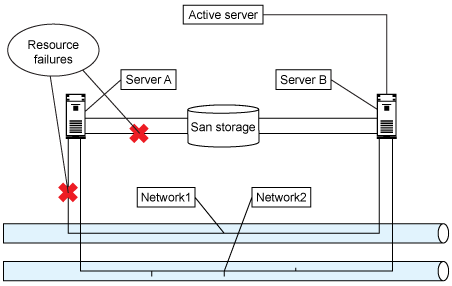
Once the hardware becomes available again, the resources can remain where they are or go back to the original server. It is completely at the discretion of the administrator.
However, hardware failures aren't the only reason for making resources move from one server to another. You can also use this technology for things like operating system upgrades, firmware maintenance, or other activities that may require downtime, all of which adds to the versatility and usefulness of PowerHA.
Key PowerHA terms
The following terms are used throughout this article and are helpful to know when discussing PowerHA:
- Cluster: A logical grouping of servers running PowerHA.
- Node: An individual server within a cluster.
- Network: Although normally this term would refer to a larger area of computer-to-computer communication (such as a WAN), in PowerHA network refers to a logical definition of an area for communication between two servers. Within PowerHA, even SAN resources can be defined as a network.
- Boot IP: This is a default IP address a node uses when it is first activated and becomes available. Typically — and as used in this article — the boot IP is a non-routable IP address set up on an isolated VLAN accessible to all nodes in the cluster.
- Persistent IP: This is an IP address a node uses as its regular means of communication. Typically, this is the IP through which systems administrators access a node.
- Service IP: This is an IP address that can "float" between the nodes. Typically, this is the IP address through which users access resources in the cluster.
- Application server: This is a logical configuration to tell PowerHA how to manage applications, including starting and stopping applications, application monitoring, and application tunables. This article focuses only on starting and stopping an application.
- Shared volume group: This is a PowerHA-managed volume group. Instead of configuring LVM structures like volume groups, logical volumes, and file systems through the operating system, you must use PowerHA for disk resources that will be shared between the servers.
- Resource group: This is a logical grouping of service IP addresses, application servers, and shared volume groups that the nodes in the cluster can manage.
- Failover: This is a condition in which resource groups are moved from one node to another. Failover can occur when a systems administrator instructs the nodes in the cluster to do so or when circumstances like a catastrophic application or server failure forces the resource groups to move.
- Failback/fallback: This is the action of moving back resource groups to the nodes on which they were originally running after a failover has occurred.
- Heartbeat: This is a signal transmitted over PowerHA networks to check and confirm resource availability. If the heartbeat is interrupted, the cluster may initiate a failover depending on the configuration.
Prep work
A number of steps must take place before you can configure an PowerHA cluster and make it available. The first step is to make sure that the hardware you will be using for the two servers is as similar as possible. The number of processors, the quantity of memory, and the types of Fibre Channel and Ethernet adapters should all be the same. If you are using logical partition (LPAR) or virtual I/O (VIO) technology, be consistent: Don't mix hardware strategies like logical Host Ethernet Adapters (LHEA) on one node with standard four-port Ethernet adapters on the other.
The second step, which should coincide with the first, is to size the environment in such a way that each node can manage all the resource groups simultaneously. If you decide that you will have multiple resource groups running in the cluster, assume a worst-case scenario where one node will have to run everything at once. Ensure that the servers have adequate processing power to cover everything.
Third, you need to assign and/or share the same set of resources to each server. If you use SAN disks for storage, the disks for the shared volume groups need to be zoned to all nodes. The network VLANs, subnets, and addresses should be hooked up in the same fashion. Work with your SAN and network administrators to get addresses and disks for the boot, persistent, and service IP addresses.
Fourth and finally, the entire operating system configuration must match between the nodes. The user IDs, third-party software, technology levels, and service packs need to be consistent. One of the best ways to make this happen is to build out the intended configuration on one node, make a mksysb backup, and use that to build out all subsequent nodes. Once the servers are built, consider them joined at the hip: make changes on both servers consistently all the time.
With all of the virtualization technology available today, it's far more worthwhile to use VIO to create a pair of production and development LPARs on the same set of System p servers and hardware resources than to try to save a few dollars at the expense of sacrificing the true purpose for which PowerHA was designed. Use things like shared processor weights, maximum transmission unit (MTU) sizes, and RAM allocation to give the production LPARs more clout than the development LPARs. Doing so creates an environment that can handle a failover and assures managers and accountants that finances are being used wisely.
Configuring a two-node PowerHA cluster
Now for the actual work. In this example, you set up a simple two-node cluster across two Ethernet networks: one shared volume group on a SAN disk that also uses a second SAN disk for a heartbeat and with an application managed by PowerHA in one resource group.
Note: This process assumes that all IP addresses have been predetermined and that the SAN zoning of the disks is complete. Unless otherwise stated, you must run the tasks here on each and every node of the cluster.
Step 1. Install the PowerHA software
You can purchase this software from IBM directly (see Related topics for a link); the file sets all start with the word cluster. Use the installp command to install the software, much like any other licensed program package (LPP).
Step 2. Edit some flat files
Put all of the IP addresses associated with the cluster — boot, persistent, and service — into each /etc/hosts file on each node of the cluster. Do the same with the /usr/es/sbin/cluster/etc/rhosts file. Verify that the server hostnames match the appropriate IP addresses; the server's hostname should also match with the persistent IP address.
Step 3. Configure the boot IP addresses
Run the smitty chinet command, and set the boot IP addresses for each network adapter. Make sure that you are able to ping and connect freely from node to node on all respective networks. Also, double-check to make sure that the default route is properly configured. If it isn't, run smitty tcpip, go into the Minimum Configuration menu, enter the default route for the primary adapter, and press Enter.
Step 4. Make application start and stop scripts
Create two simple Korn shell scripts — one that starts an application and one that stops an application. Keep these scripts in identical directories on both nodes.
Step 5. Define the cluster
Run the command:
smitty cm_config_an_hacmp_cluster_menu_dmn
Then, define the cluster, including naming it appropriately.
Step 6. Define the nodes
Run the command:
smitty cm_config_hacmp_nodes_menu_dmn
Define every node within the cluster on both nodes.
Step 7. Define the networks
Run the command:
smitty cm_config_hacmp_networks_menu_dmn
This defines one network per Ethernet adapter. I prefer to use the Pre-defined option as opposed to the Discovered path, but that is up to your discretion. Check the subnet masks for consistency.
Step 8. Define the boot IP addresses
Run the command:
smitty cm_config_hacmp_communication_interfaces_devices_menu_dmn
This defines the boot IP addresses on the respective network adapters. This address should be the same IP addresses you used in step 3. Make sure you define these addresses within the proper respective PowerHA-defined network.
Step 9. Define the persistent IP addresses
Run the command:
smitty cm_config_hacmp_persistent_node_ip_label_addresses_menu_dmn
This defines the persistent IP addresses, again paying attention to pick the proper respective PowerHA-defined network.
Step 10. Define the service IP addresses
Run the command:
smitty cm_config_hacmp_service_ip_labels_addresses_menu_dmn
This defines the service IP addresses.
Step 11. Perform a discovery and reboot
By this point, the nodes should have the ability to communicate with each other and keep the information stored in the nodes' Object Data Managers (ODMs) in sync. Make the nodes within the cluster communicate with each other by running the command:
smitty cm_extended_config_menu_dmn
Select the Discover PowerHA-related Information from Configured Nodes option, and check for errors to fix. Generally, rebooting each node can clear up any minor problems, and this is a good point to test restarting each server anyway.
Step 12. Define the resource group
Run the command:
smitty cm_hacmp_extended_resource_group_config_menu_dmn
Define the resource group. Then, perform these steps:
- Select all participating nodes in the cluster.
- Set the Startup Policy to Online On First Available Node.
Set the Fallback Policy to Never Fallback.
This setting prevents the resources from going back to the original server when it is brought up, which is a wise thing to do.
Step 13. Create a shared volume group
Note: Run this command only on one node.
Run the smitty cl_vg command, and create a shared volume group. When you create a shared volume group, you only need to select one of the nodes, because the disk is shared.
Step 14. Create a heartbeat disk
First, run the smitty cl_convg command, and then select Create a Concurrent Volume Group with Data Path Devices. Choose one node and the target disk. Next, run the command:
smitty cm_config_hacmp_communication_interfaces_devices_menu_dmn
Repeat step 7, except this time, select the Discovered option and the target disk.
Step 15. Define an application server
Run the command:
smitty cm_cfg_app_extended
This defines an application server for an application that PowerHA will manage. Use the scripts you created in step 4.
Step 16. Configure the resource group
Note: Run this command on only one node.
Run the command:
smitty cm_hacmp_extended_resource_group_config_menu_dmn
Select the Change/Show Resources and Attributes for a Resource Group option. Then, perform these steps:
- Select the appropriate service IP addresses.
- Select the appropriate shared volume groups and heartbeat disk.
- Select the appropriate application servers.
Step 17. Perform a synchronization
Synchronize the cluster configuration. Run the command:
smitty cm_ver_and_sync
Set Automatically correct errors found during verification? to Interactive. Correct any problems along the way.
Step 18. Start the cluster
At this point, the cluster is ready to start. On one of the nodes, run the smitty clstart command, and pick that particular node. My preference is not to have the cluster start on reboot, because if there is a PowerHA-related problem on startup, it can be difficult to troubleshoot it. After the node comes up with the resources available, start the cluster on the other node.
Step 19. Perform a test failover
The best way I have found to test PowerHA's adaptability is to reboot the active node and let things fail over naturally while running the tail –f /tmp/hacmp.out command on the other node to watch as things go over. Or, run the command:
smitty cl_resgrp_move.node_site
Select the Move Resource Groups to Another Node option.
Step 20. Perform failure testing
If you really want to make sure your cluster is solid, perform testing by literally removing cables and seeing how the resources move back and forth. The more you test, the more reliable your cluster will be.
Conclusion
PowerHA is a robust and effective tool for keeping resources available on AIX servers. Although this article presented a simple introduction and how-to for setting up a two-node cluster, PowerHA is capable of doing much more, including application monitoring, integrating NAS resources, and putting logic into starting up resource groups. But if you are looking to hit the ground running, the best advice I have is to make a test cluster and try everything you can.