Article
Introduction to PowerHA
Power high availabilityArchive date: 2022-11-01
This content is no longer being updated or maintained. The content is provided “as is.” Given the rapid evolution of technology, some content, steps, or illustrations may have changed.Introduction
In today's increasing business demands, critical applications need to be available all the time, and the system needs to be fault tolerant. But these fault tolerant systems always come with a heavy cost. Hence, there is need of an application which provides these facilities and is also cost effective.
A high availability solution can ensure that the failure of any component of the solution does not cause the application and its data to be unavailable to the user community. This is achieved through the elimination, or masking, of both planned and unplanned downtime by eliminating single points of failure. Also, there is no specialized hardware required to make an application highly available. PowerHA does not perform some administrative tasks like backups, time synchronization, and any application specific configuration.
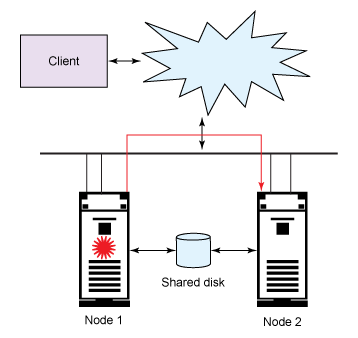
Figure 1 is an illustration of the failover capacity. When one server goes down, the other takes over.
Figure 1. Failover capacity
Overview of PowerHA
The terms PowerHA and HACMP are used interchangeably. As mentioned earlier, it eliminates single points of failure (SPOF). The following table shows possible SPOFs:
| Cluster object | Eliminated as SPOF by: |
|---|---|
| Node | Use multiple nodes |
| Power source | Using multiple circuits or uninterrupted power supplies |
| Network adapter | Using redundant network adapters |
| Network | Using multiple networks to connect nodes |
| TCP/IP subsystem | Using non-IP networks to connect adjoining nodes and clients |
| Disk adapter | Using redundant disk adapter or multi-path hardware |
| Disk | Using multiple disks with mirroring or raid |
| Application | Adding nodes for takeover; configuring application monitor |
| VIO server | Implementing dual VIO server |
| Site | Adding an additional site |
The main goal is to have 2 servers so that if one fails, the other takes over. PowerHA is a clustering technology that provides both failover protection by having redundancy and horizontal scalability through concurrent/parallel access.
PowerHA terminology
There are various terminologies used in PowerHA. They can be classified into topology components and resource components.
The topology components are basically the physical components. They include:
- Nodes: System p servers can be standalone partitions or vios clients
- Networks: IP networks and non-IP networks
- Communication interfaces: Token ring or Ethernet adapters
- Communication devices: RS232 or heartbeat over disk
The resources components are the logical entities that will be made highly available. They include:
- Application server: It involves the start/stop scripts of the application
- Service IP address: The end users are generally given an IP address to connect to the application. This IP address is mapped to a node where the application is actually running. Since the IP address needs to remain highly available, it is a part of the resource group.
- File system: Many applications require the file systems to mounted.
- Volume group: Volume groups are required to be made highly available with many applications.
All the resources together form an entity called a resource group. PowerHA handles this as a single unit. It keeps the resource groups highly available. Resource groups have policies associated with it. Those are:
- Startup policy: This tells which node the resource group should activate
- Fallover policy: When a failure happens, this determines the fallover target node
- Fallback policy: This tells whether or not the resource group will fallback.
Whenever a failure happens, it looks for these policies and works accordingly.
The subsystems of PowerHA
Figure 2. Subsystems of PowerHA
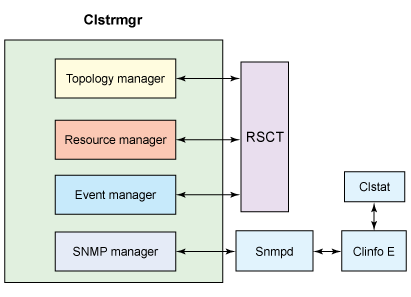
The illustration above shows how PowerHA comprises of a number of software components:
- The cluster manager (clstrmgr) is the core process that monitors cluster membership. The cluster manager includes a topology manager to manage the topology components, a resource manager to manage resource groups, an event manager with event scripts that works through the RMC facility, and RSCT to react to failures.
- The clinfo process provides an API for communicating between cluster manager and your application. Clinfo also provides remote monitoring capabilities and can run a script in response to a status change in the cluster.
- In PowerHA V5, clcomdES allows the cluster managers to communicate in a secure manner without using rsh and the /.rhost files.
Configuration of a 2 node cluster
Before starting off with the configurations, let's look at the networking and the storage considerations of PowerHA.
Networking
PowerHA uses networks to detect and diagnose failures, as well as providing clients with highly available access to applications.
Internode communication also happens through networks. PowerHA detects three kinds of failures directly. Those are the network, NIC and node failure. It detects and diagnosis through the use of RSCT daemon. RSCT detects the loss of heartbeat packets that are sent across all the networks and determines the exact loss (network, NIC or node failure).
Figure 2 shows that the heartbeat packets are transferred and received by all NICs, which helps in determining the failures.
Figure 3. Cluster representing heartbeat packets
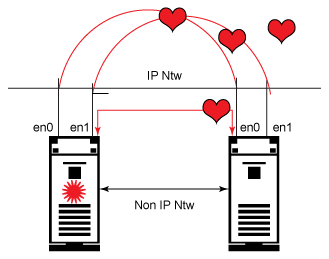
If the heartbeat packets are stopped, then both nodes assume that the other is down and each will try to bring the resource group online. This could result in massive data corruption.
To avoid this, PowerHA uses two kinds of networks:
- IP networks: Examples are Ethernet, Ether channel, etc.
- Non-IP networks: An example is RS232 (this is needed to make sure that even if the network goes down, PowerHA is capable of differentiating between network failure and node failure)
IP address take over (IPAT)
Most applications require that the IP address be highly available. To ensure this, we include this service IP into the resource group. The movement of this service IP from one NIC to another is called as IP address take over. There are two ways to use IPAT:
- IPAT via aliasing: PowerHA adds the service IP address to the NIC (accomplished using AIX IP aliasing feature).
- IPAT via replacement: PowerHA replaces the Interface IP address with the Service IP.
Storage
Storage can be broadly classified into two types:
- Private storage: Owned by only one node
- Shared storage: Owned by one or more nodes in the cluster
All applications' data resides in the shared storage. To avoid data inconsistency, shared storage protection can be done in the following ways:
- Reserve/release-based shared storage protection: Used with standard volume groups
- RSCT-based shared storage protection: Used with enhanced concurrent volume groups
HACMP 5.x supports the RSCT-based style of shared storage protection, which relies on AIXs RSCT component to coordinate the ownership of shared storage when using enhanced concurrent volume groups in non-concurrent mode.
Configuration
Before starting with the configuration, the cluster must be properly planned. The online planning worksheets (OLPW) can be used for the planning purpose. Here, it explains the configuration of a two node cluster. In the example provided, both nodes have 3 Ethernet adapters and 2 shared disks.
Step 1: Fileset installation
After installing AIX, the first step is to install the required filesets. The RSCT and BOS filesets can be found in the AIX base version CDs. The license for PowerHA needs to be purchased to install the HACMP filesets. Install the following filesets:
| RSCT filesets | BOS filesets | HACMP 5.5 filesets |
|---|---|---|
| rsct.compat.basic.hacmp rsct.compat.clients.hacmp rsct.basic.hacmp rsct.basic.rte rsct.opt.storagerm rsct.crypt.des rsct.crypt.3des rsct.crypt.aes256 | bos.data bos.adt.libm bos.adt.syscalls bos.clvm.enh bos.net.nfs.server | cluster.adt.es cluster.es.assist cluster.es.cspoc cluster.es.plugins cluster.assist.license cluster.doc.en_US.assist cluster.doc.en_US.es cluster.es.worksheets cluster.license cluster.man.en_US.assist cluster.man.en_US.es cluster.es.client cluster.es.server cluster.es.nfs cluster.es.cfs |
After installing the filesets, reboot the partition.
Step 2: Setting the path
Next, the path needs to be set. To do that, add the following to the /.profile file:
export PATH=$PATH:/usr/es/sbin/cluster:/usr/es/sbin/cluster/utilities
Step 3: Network configuration
To configure an IP address on the Ethernet adapters, do the following:
#smitty tcpip -> Minimum Configuration and Startup -> Choose Ethernet network interface
You will have three Ethernet adapters. Two with private IP address and one with public IP address. As shown in the image below, enter the relevant fields for en0 (which you will configure for a public IP address).
Image 1. Configuration of a public IP address

This will configure the IP address and start the TCP/IP services on it.
Similarly, you configure the private IP addresses on en1 and en2, as shown in Image 2.
Image 2. Configuration of a private IP address

Similarly, configure en2 with private IP 10.10.210.21 and start the TCP/IP services. Next, you need to add the IP addresses (of both node1, node2 and the service IP which db2live here) and the labels into /etc/hosts file. It should look like the following:
# Internet Address Hostname # Comments
127.0.0.1 loopback localhost # loopback (lo0) name/address
192.168.20.72 node1.in.ibm.com node1
192.168.20.201 node2.in.ibm.com node2
10.10.35.5 node2ha1
10.10.210.11 node2ha2
10.10.35.4 node1ha1
10.10.210.21 node1ha2
192.168.22.39 db2live
The idea is that you should include each of the three ports for each machine with relevant labels for name resolution.
Perform similar operations on node2. Configure en0 with the public IP and en1 and en2 with private IPs and edit the /etc/hosts file. To test that all is well, you can issue pings to the various IP addresses from each machine.
Step 4: Storage configuration
We need to have a shared storage to create heartbeat over FC disk. The disks need to be allocated from SAN. Once both the nodes are able to see the same disks (this can be identified using LUN number), heartbeat over disks will be configured.
This method does not use Ethernet to avoid a single point of failure from the Ethernet network/switches/protocols. The first step is to identify the available major number on all the nodes (as shown on Image 3 below).
Image 3. Identifying available major number
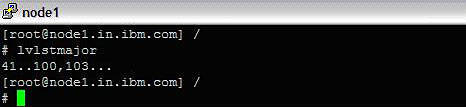
Pick a unique number. In this case, we picked 100.
On node1
Create a vg "hbvg" on the shared disk "hdisk1" with enhanced concurrent capability.
#smitty mkvgImage 4. Volume group creation
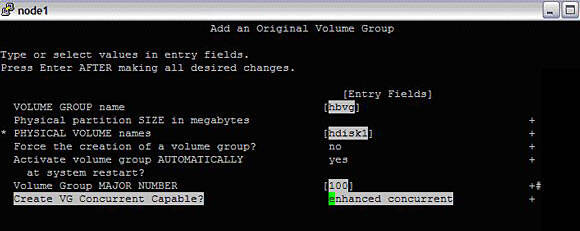
Once hbvg is created, the autovaryon flag needs to be disabled. To do that, run the following command:
#chvg -an hbvgNext, we create logical volumes in the volume group "hbvg". Enter an LV name such as hbloglv, select 1 for the number of logical partitions, select jfslog as the type, and set scheduling to sequential. Let the remaining options have the default value and press Enter.
#smitty mklvImage 5. Logical Volume creation
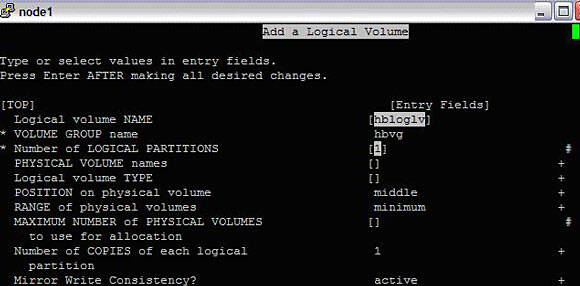
Once lv is created, initialize the logform with the following:
#logform /dev/hbloglvRepeat this process to create another LV of type jfs and named hblv (but otherwise identical).
Next, we create a filesystem. To do that, enter the following:
#smitty crfs ->Add a Journaled File System -> Add a Journaled File System on a Previously Defined Logical Volume -> Add a Standard Journaled File SystemHere enter the lv name "hblv", lv for log as " hbloglv" and the mount point /hb_fs
Image 6. Filesystem creation in a Logical Volume
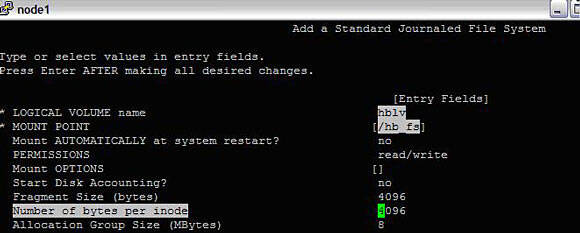
Once the Filesystem is created, try mounting the file system. Before moving to node2, unmount /hb_fs and varyoffvg hbvg.
On Node 2
Identify the shared disk using PVID. Import the volume group with same major number (we used 100) from the shared disk (hdisk1):
#importvg -V 100 -y hbvg hdisk1Varyon the volume group and disable auto start at mount.
#varyonvg hbvg #chvg -an hbvgNow, you should be able to mount the filesystem. Once done, unmount the filesystem and varyoffvg hbvg.
Verification of Heartbeat over FC:
Open 2 different sessions of both the nodes. On node1, run following command where hdisk1 is the shared disk.
#/usr/sbin/rsct/bin/dhb_read -p hdisk1 -rOn node2:
/usr/sbin/rsct/bin/dhb_read -p hdisk1 -tBasically, one node will heartbeat to the disk and the other will detect it. Both nodes should return to the command line after the reporting link operates normally.
Application specific configuration
If you are creating any application (for example DB2 server) highly available, specific configuration needs to be done. That is beyond the scope of this article.
HACMP related configuration
Network takeover on both nodes:
- Run
grep -i community /etc/snmpdv3.conf | grep publicand ensure that there is an uncommented line similar to COMMUNITY public public noAuthNoPriv 0.0.0.0 0.0.0.0. Next we need to add all the IP addresses of nodes, NIC's in the /etc/rhosts file.
# cat /usr/es/sbin/cluster/etc/rhosts 192.168.20.72 192.168.20.201 10.10.35.5 10.10.210.11 10.10.35.4 10.10.210.21 192.168.22.39
Configuring PowerHA cluster
On Node 1:
First, define a cluster:
#smitty hacmp --> Extended Configuration --> Extended Topology Configuration --> Configure an HACMP Cluster --> Add/Change/Show an HACMP ClusterImage 7. Defining a cluster
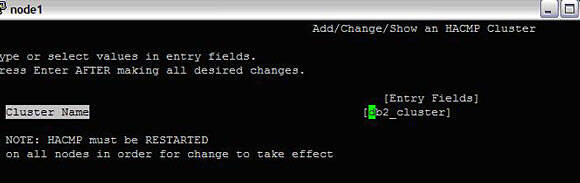
Press Enter; now, the cluster is defined.
Add nodes to the defined cluster:
#smitty hacmp --> Extended Configuration --> Extended Topology Configuration --> Configure HACMP Nodes --> Add a Node to the HACMP ClusterImage 8. Adding nodes to a cluster
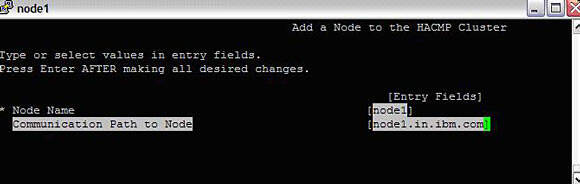
Similarly, add another node to the cluster. Now, we have defined a cluster and added nodes to it. Next, we will make the two nodes communicate with each other.
To add networks, we will add two kinds of networks, IP (Ethernet) and non-IP (diskhb).
#smitty hacmp --> Extended Configuration --> Extended Topology Configuration--> Configure HACMP Networks --> Add a Network to the HACMP ClusterSelect "ether" from the list.
Image 9. Adding networks to the cluster
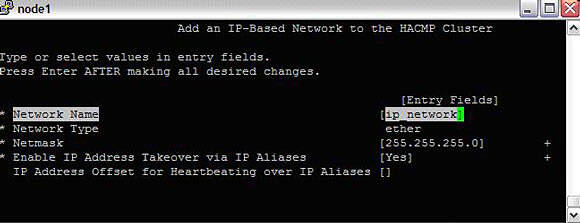
After this is added, return to "Add a network to the HACMP cluster" and also add the diskhb network.
The next step establishes what physical devices from each node are connected to each network.
#smitty hacmp --> Extended Configuration --> Extended Topology Configuration--> Configure HACMP Communication Interfaces/Devices --> Add Communication Interfaces/Devices -->Add Pre-defined Communication Interfaces and Devices--> Communication InterfacesPick the network that we added in the last step (IP_network) and enter configuration similar to this:
Image 10. Adding communication devices to the cluster
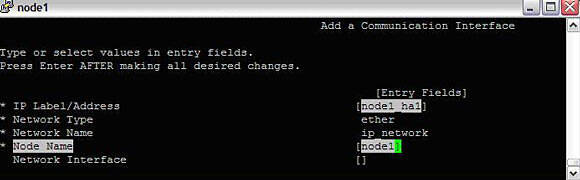
There should be a warning about an insufficient number of communication ports on particular networks. These last steps need to be repeated for the different adapters to be assigned to the various networks for HACMP purposes. The warnings can be ignored. By the time all adapters are assigned to networks, the warnings must be gone. In any case, repeat for all interfaces.
Note that for the disk communication (the disk heartbeat), the steps are slightly different.
#smitty hacmp --> Extended Configuration --> Extended Topology Configuration--> Configure HACMP Communication Interfaces/Devices --> Add Communication DevicesSelect shared_diskhb or the relevant name as appropriate and fill in the details as below:
Image 11. Adding communication interfaces to the cluster
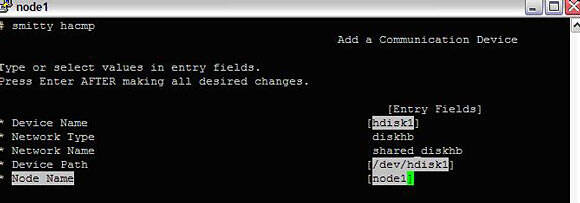
Each node in the cluster also needs to have a persistent node IP address. We associate each node with its persistent IP as follows:
#smitty hacmp --> Extended Configuration --> Extended Topology Configuration--> Configure HACMP Persistent Node IP Label/AddressesAdd all the details as below:
Image 12. Adding persistent IP address to the cluster
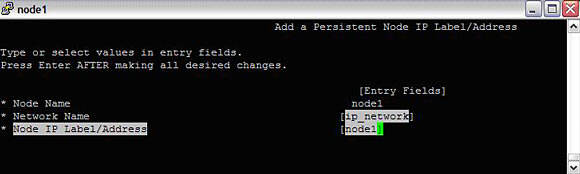
Checkpoint:
After adding everything, we should check if everything was added correctly.
#smitty hacmp --> Extended Configuration --> Extended Topology Configuration--> Show HACMP Topology -->Show Cluster TopologyIt will list all the networks, interfaces, devices. Verify that they are added correctly.
Adding resource group:
Now we have defined a cluster, added nodes to it, and also configured both IP as well as non-IP_network. The next step is to configure a resource group. As defined earlier, a resource group is a collection of resources. Application server is one such resource which needs to be kept highly available, for example a DB2 server.
Adding an application server to resource group:
#smitty hacmp --> Extended Configuration-->Extended Resource Configuration-->HACMP Extended Resources Configuration--> Configure HACMP Application Servers-->Add an Application ServerImage 13. Adding resources - Application server
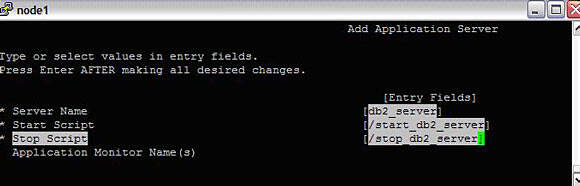
This specifies the server name, the start and the stop scripts needed to start/stop the application server. For applications such as DB2, WebSphere, SAP, Oracle, TSM, ECM, LDAP, IBM HTTP, the start/stop scripts come with the product. For other applications, administrators should write their own scripts to start/stop the application.
The next resource that we will add into the resource group is a service IP. It is through this IP only that the end users will connect to the application. Hence, service IP should be kept highly available.
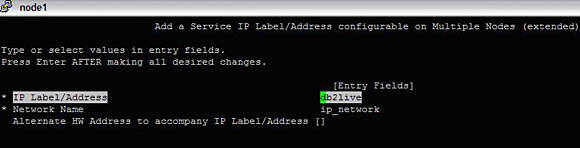
#smitty hacmp --> Extended Configuration-->Extended Resource Configuration-->HACMP Extended Resources Configuration-->Configure HACMP Service IP Labels/Addresses--> Add a Service IP Label/AddressChoose "Configurable on Multiple Nodes" and then "IP_network". Here we have db2live as the service IP.
Image 14. Adding resources - Service IP
Now the resources are added, we will create a resource group (RG), define RG policies, and add all these resources to it.
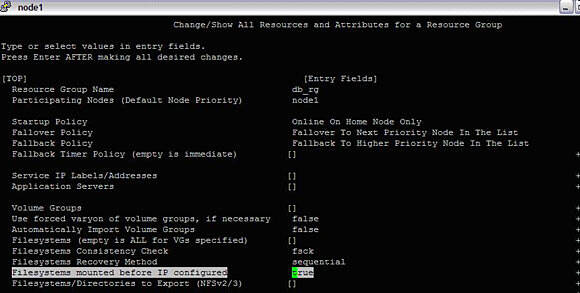
#smitty hacmp --> Extended Configuration-->HACMP Extended Resource Group Configuration--> Add a Resource GroupImage 15. Resource group creation
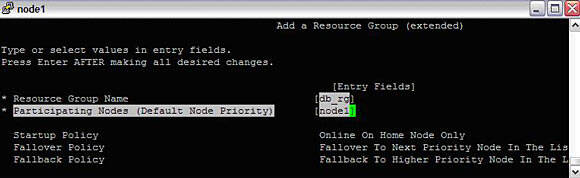
Once RG is created, we can change attributes of it using,
#smitty hacmp --> Extended Configuration-->HACMP Extended Resource Group Configuration-->Change/Show Resources and Attributes for a Resource GroupSelect db2_rg and configure as desired:
Image 16. Defining various attributes of the resource group
Verification and synchronization
Once everything is configured on the primary node (node1), we need to synchronize this with all other nodes in the cluster. To do that, do the following:
#smitty hacmp--> Extended Configuration--> Extended Verification and SynchronizationImage 17. Verification and synchronization of the cluster
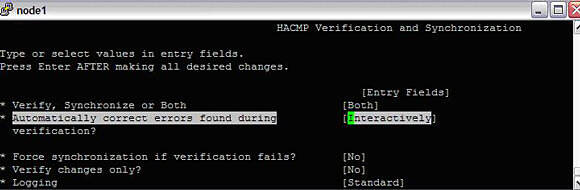
This will check the status and configuration of the local node first, and then it will propagate the configuration to the other nodes in the cluster, if they are reachable. There should be plenty of details on any errors and passes, too. Once this is done, your cluster is ready. You can test it by moving the RG manually. To do that, do the following:
#smitty hacmp--> System Management (C-SPOC)--> HACMP Resource Group and Application Management--> Move a Resource Group to Another Node / Site--> Move Resource Groups to Another NodeChoose "node2" and press Enter. You should see the stop scripts running on node1 and start scripts running on node2. After few seconds, the RG will be online on node2.