Article
Challenges and patterns for modernizing a monolithic application into microservices
Advice for your potentially difficult, but worthwhile, migration journeyWhat is a monolithic application? There are many definitions available, such as a legacy application or codebase that evolved organically, or an application that does not have clear domain and module boundaries. However, the best way to describe it is the application that grew over time, became unmanageable and difficult to understand, and has low cohesion and high coupling. Microservices architecture promises to solve the shortcomings of monolithic applications, so many enterprises are interested in migrating their applications to be microservices. This migration is a worthwhile journey, but not an easy one.
A microservices architecture mandates or promotes applications that consist of one or many independent services, where each service encapsulates a business capability. Each microservice exposes an API application, which is discoverable and can be used in a self-serve manner. In addition, each microservice has an independent lifecycle, which means that each one can be developed, deployed, scaled, and managed independently.
Challenges of breaking up a monolithic app into microservices
Most enterprises have a large application in place for their business use cases. Take the example of an e-commerce application used by an online retailer. The diagram in Figure 1 shows its monolithic architecture.
Figure 1: Monolithic e-commerce app
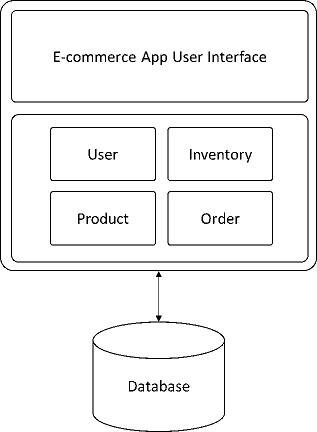
While a monolithic architecture seems like a good idea to quickly get the application started, it becomes a problem over time. As the business and user base grows, customers expect newer user experiences, and integration requirements increase, the monolithic approach becomes a bottleneck to growth. Typical issues with monolithic applications include huge time to market, a complex learning curve for new developers, unusually large dependencies, and longer deployment time.
Figure 2: Microservices architecture for e-commerce app
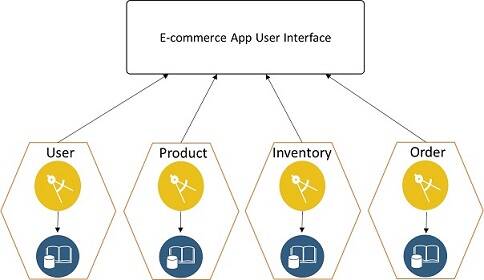
In contrast, Figure 2 shows how the same e-commerce application can be broken down into a microservices architecture. The idea seems simple but is sometimes difficult to perceive. The architecture team should consider the following aspects:
- Possible candidates that could represent a microservice.
- How to run the monolithic app in parallel while you develop the microservices.
- How to tackle the database, which is also monolithic.
- How to manage transactions that span across microservices.
The following sections discuss helpful patterns to address these aspects.
Service decomposition
Although breaking down a monolithic application can seem like an uphill task to start, with certain guidelines even this mammoth task is possible:
- Stop adding more things to the monolithic app. Fix what is broken and accept only small changes.
- Find out the so-called seams in your monolithic app. Identify components that are more loosely coupled than others and use them as a starting point.
- Identify low hanging fruits, such as the components for which business units want to add more advanced features.
Identify which service goes first
An ideal starting point is to identify the loosely coupled components in your monolithic app. They can be chosen as one of the first candidates. However, other component properties also need to be evaluated:
- The technical debt of the component should be lower to avoid taking those debts along with the migrated microservices.
- Test coverage of the component should be good so that it would be easy to test the components post migration.
- The components should be of high value to the business unit, so it sees the benefits of the migration, such as faster deployment cycles and fulfilled scalability requirements.
- Components should have clean separation from the database.
Strangling the journey
After you identify the ideal service candidate and your team starts to build it using a modern microservice architecture, they must identify a way for both microservice and monolithic components to co-exist. One of the ways to tackle this co-existence is by introducing an inter-process communication (IPC) adapter, which can act as the glue. Slowly and steadily, the microservice takes on the load and eliminates the monolithic component. This process is known as a strangler pattern and provides a balance between transformation and change management.
Figure 3: Strangling the journey
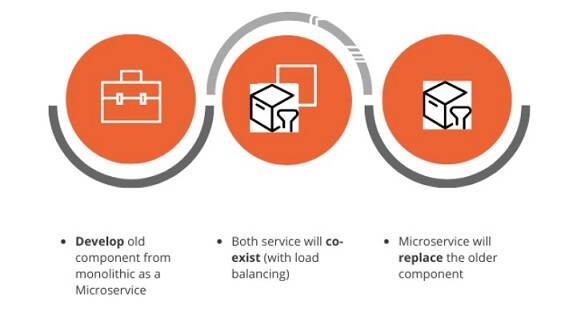
To move the whole monolithic app into the microservice architecture, the business unit has to rank candidate services for migration. While one service is picked up for analysis and transformation, the rest of the monolithic app continues to operate. This pattern continues until you transform all the moving parts of the monolithic app into individual microservices.
Here is an example to understand this approach. As illustrated in Figure 4, module Z is the candidate that you want to extract and modules X and Y are dependent upon it. You can create an IPC adapter in the monolithic application that X and Y use to talk to Z with a REST API. With this adapter, you can move all of the modules from the monolithic app to be an individual, self-sufficient microservice.
Figure 4: Strangler pattern example
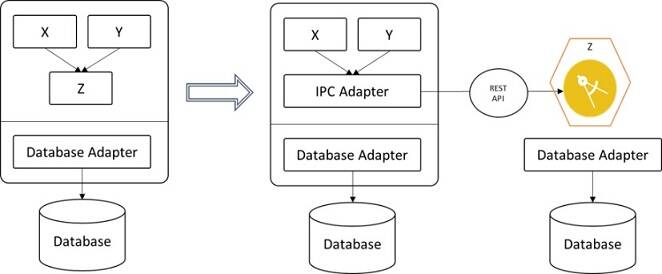
You can read more about the Strangler pattern in this article, "Apply the Strangler Fig Application pattern to microservices applications."
Analyzing the existing codebase
A key step in identifying the core components of any monolithic application is analyzing the codebase. It also helps you understand the cohesiveness between various modules and prepare a list of microservices that you want to build. There are various tools that you can use to perform the analysis, such as Altova MissionKit, Structure 101, or, if the underlying language is Java, you can use JavaParser and build your own analysis. The objectives of this analysis are:
- Identify the domain and subdomains of the application and eventually, the bounded context of individual modules.
- Understand the dependencies that you have within the bounded contexts.
There are various options.
Option 1: Discover monolithic APIs If your monolithic application is already exposing APIs, the existing API endpoints can be listed with code analysis. Conduct further analysis to group these API endpoints by their resources. This group of endpoints can potentially be developed as a microservice.
Option 2: Model-led approach Use the code analysis results to find models that correspond to a domain. You can further refine the models by superimposing database entity relationship (ER) diagrams and industry models, such as the Banking Industry Architecture Network (BIAN). These models can serve as domain models, while they define the bounded context for your microservice.
Remember, both the monolithic components and microservices continue to co-exist until all functionalities of the monolithic app are converted into microservices. Hence, you also need to refactor the monolithic app to remove any dependency in the bounded context, which can lead to a smoother transition.
Tackling a monolithic database
Typically, monolithic applications have their own monolithic databases. One of the principles of a microservices architecture is one database per microservice. So, when you modernize your monolithic application into microservices, you must split the monolithic database apart.
The first obvious step is to analyze the monolithic database mappings. As part of the service decomposition process, you already gathered some insights on the microservices to be created. Using the same approach, you should analyze database usage and map tables or other database objects to the new microservices. There are various tools available, such as SchemaCrawler, SchemaSpy, and ERBuilder, to perform such an analysis. This mapping helps you understand the coupling between database objects that spans across your potential microservices boundaries.
However, splitting a monolithic database is complex. Primarily because a monolithic database is a reflection of the monolithic app and there is not clear separation between database objects that are related to different functionalities. You also need to consider other issues, such as data synchronization, transactional integrity, joins, and latency.
The next section looks at various patterns that can help you respond to these issues while splitting your monolithic database.
Reference tables
The most common type of pattern that is seen within monolithic applications is a reference table. In this pattern, the function or module accesses a table that belongs to another function or module. The joins between a module's own table and another table are used to retrieve the required data. This is considered to be an anti-pattern in microservices architecture. Using the previous example of an e-commerce application, the Order module uses a reference to the Products table to retrieve product information. This example is illustrated in Figure 5.
Figure 5: Reference table in an e-commerce monolithic app
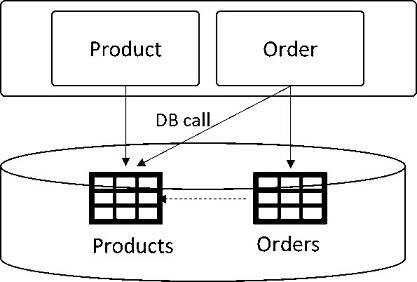
But in a microservices architecture, the Products table and Order module become separate microservices. Here are two options for you to consider to separate the database objects.
- Option 1: Data as an API When the core functionalities or modules are separated as microservices, the common way to share and expose data is with APIs. The referenced service exposes data as an API that is needed by the calling service. The joins in this case are in-memory. Figure 6 shows how this option is used by the Product and Order microservices of the e-commerce application.
Figure 6: Data as an API
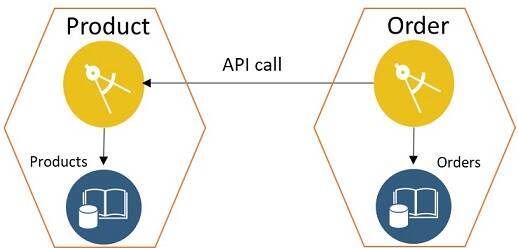
This option has obvious performance issues due to additional network and database calls. Also, in-memory data set joins add to the overhead. But this works very well in cases where data size is limited.
- Option 2: Projection of data The other way to share data between two separate microservices is to build a projection of the data in the dependent service. The data projection is read-only and can be rebuilt anytime. This pattern enables the service to be more cohesive. Figure 7 shows how this option can be used by the Product and Order microservices of the example e-commerce application.
Figure 7: Projection of data
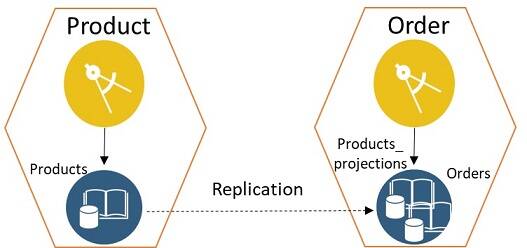
There are various techniques that can be used to build data projections such as materialized views, change data capture (CDC), and event notifications. One thing to note here is that the data in the projection is eventually consistent.
Shared reference, static data
Static data, such as country codes, i18n, and supported currencies, are very slow to change and typically, a user interface is not available to manage them. These types of data are accessed by different functionalities or modules of a monolithic application by using joins with their own entities. While you migrate to a microservices architecture, you must also handle this static data. The static data that is specific to a domain obviously moves to that service's database. For static data that has application-wide usage, the following options can be considered.
Option 1: Static data per database The static data that is used by different services or modules of the application can be duplicated to their respective databases while they are modeled as separate microservices. The downside of this approach is data consistency and data duplication. But it works very well if the frequency of data updates for this static data occurs less often.
Option 2: Data as an API Handling data as an API is the standard approach to model shared reference data as a domain and develop a separate microservice to manage it. This microservice has APIs to expose data, which can be consumed by the calling services. Since data is static in nature, the use of caching frameworks works well in this case.
Option 3: Static data as configuration The static data can be injected as a configuration to the microservices. This option is suitable in situations where static data does not have any entity significance. Modern microservices and cloud frameworks provide features to manage such configuration data via config servers, key-value store, and vaults, and these features can be included declaratively.
Shared mutable data
In monolithic applications, there is a common pattern that is known as shared mutable state. This pattern represents certain domain realities that are modeled in a database and accessed by different functionalities or modules of the application. This is mainly done for convenience. For example, in the e-commerce application, the Order, Payment, and Shipping functionalities use the same ShoppingStatus table to maintain the customer's order status throughout the shopping journey, as shown in Figure 8.
Figure 8: Shared mutable data
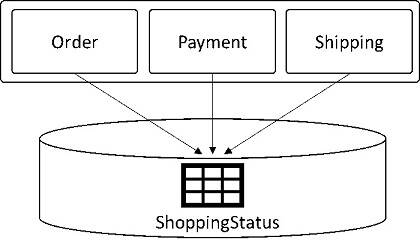
Such cases are difficult to find during a microservices architecture migration. But they should eventually be modeled as a separate microservice. Coming back to the e-commerce example, a separate ShoppingStatus microservice is developed to manage the ShoppingStatus database table. This microservice exposes APIs to manage a customer's shopping status. The Payment, Order, and Shipping microservices use APIs of the ShoppingStatus microservice, as shown in Figure 9.
Figure 9: Shared data as separate microservice

Shared table
The shared table pattern is very similar to the shared mutable state pattern and is the result of erroneous domain modeling. In this scenario, a database table is modeled with attributes that are needed by two or more functionalities or modules. Again, this is done mostly for convenience reasons. To explain this, Figure 10 shows a scenario where the Products table is modeled to cater to the Product and Inventory functionalities.
Figure 10: Shared table
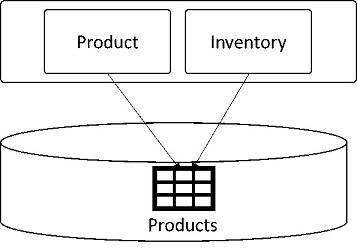
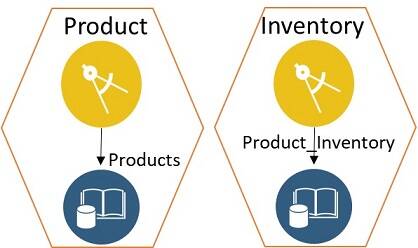
While moving to a microservices architecture, Product and Inventory are modeled as separate services. The Products table is split into individual entities that belong to the specific bounded context of the separate Product and Inventory microservices, as shown in Figure 11.
Figure 11: Shared table split per microservice
Tackling transaction boundaries
With a monolithic application that has a single database, you could guarantee the ACID (Atomicity, Consistency, Isolation, Durability) properties and ability to perform transactions by keeping locks on rows. Or even the flexibility of using transaction managers, which could do the magic of providing ACID properties on your database.
Figure 12: Monolithic to microservice transaction boundary
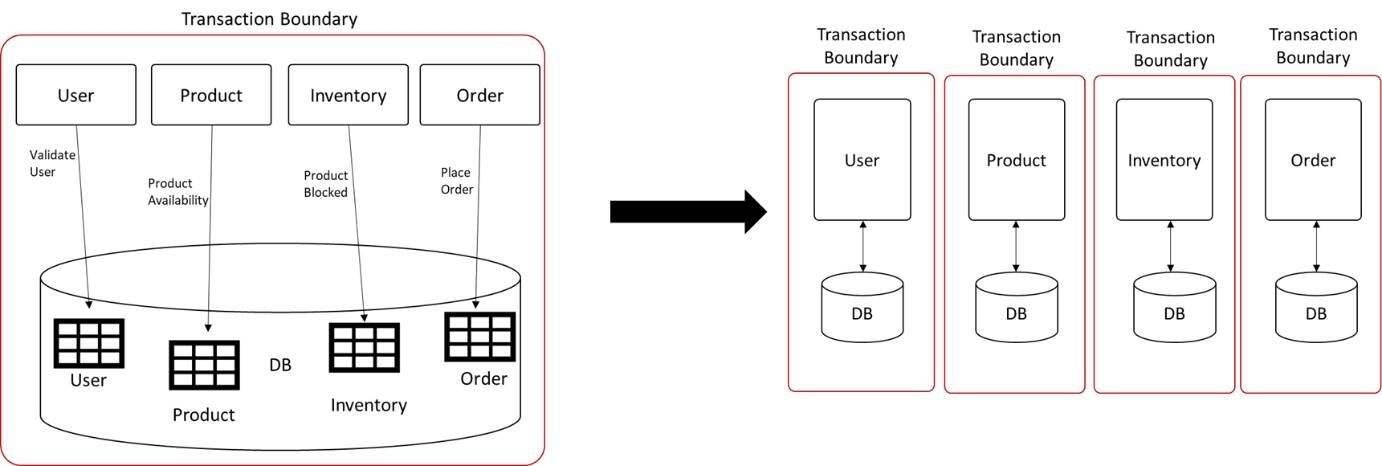
Things changed drastically when enterprises moved from service-oriented architecture to microservices architecture. They now must deal with database per service eventually leading to distributed transaction trouble. Following are the ideal ways to deal with distributed transactions.
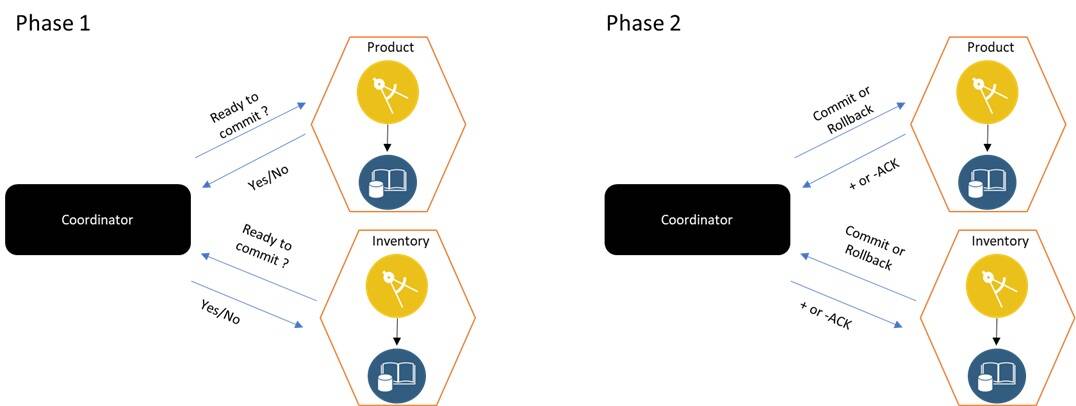
Two-phase commit (2PC)
In a two-phase commit, you have a controlling node that houses most of the logic, and a few participating nodes on which the actions are performed. It works in two phases:
- Prepare phase (Phase 1): The controlling node asks all of the participating nodes if they are ready to commit. The participating nodes respond with yes or no.
- Commit phase (Phase 2): If all of the nodes replied in the affirmative, then the controlling node asks them to commit. Even if one node replies in the negative, the controlling node asks them to roll back.
Figure 13: Two-phase commit
Even though 2PC can help provide transaction management in a distributed system, it also becomes the single point of failure as the onus of a transaction falls onto the coordinator. With the number of phases, the overall performance is also impacted. Because of the chattiness of the coordinator, the whole system is bound by the slowest resources since any ready node has to wait for confirmation from a slower node. Also, typical implementations of such a coordinator are synchronous in nature, which can future lead to reduced throughput.
Compensating transactions (Saga transactions)
A saga is a sequence of local transactions. Each service in a saga performs its own transaction and publishes an event. The other services listen to that event and perform the next local transaction. If one transaction fails for some reason, then the saga also executes compensating transactions to undo the impact of the preceding transactions.
Figure 14: Typical saga flow
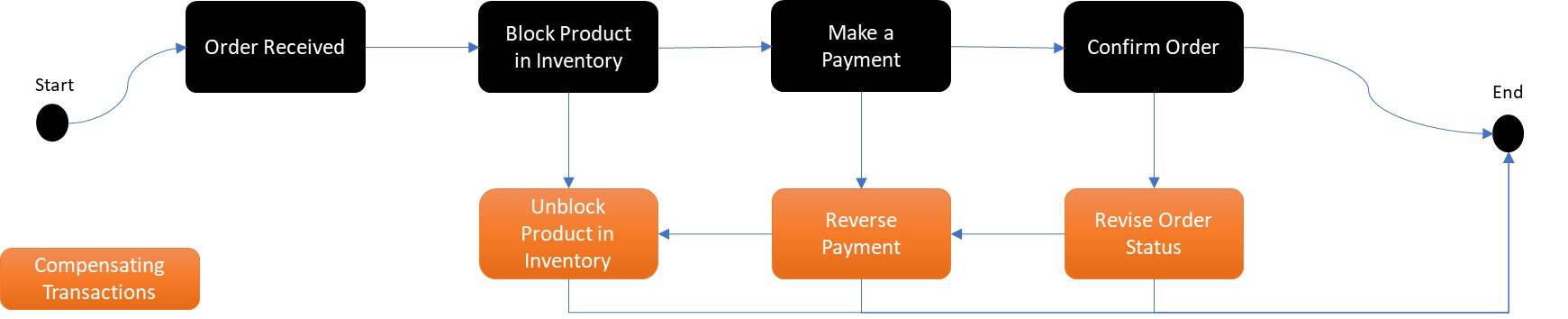
Though Saga pattern helps maintain data consistency across multiple services without tight coupling, it primarily does not ensure atomicity. Saga does introduce a certain level of complexity from a programming point and you must cater to the compensating transaction early in the design. Saga-managed flows are eventually consistent; hence, they might not fit all scenarios and should be chosen only if they are suitable. (Read more about the Saga pattern in this article, "Solving distributed transaction management problems in microservices architecture using Saga.")
Reporting across distributed microservices
An important aspect of almost all applications is reporting. Typically, two approaches are used for reporting functionalities:
In-app reporting Most stand-alone, monolithic applications use their own databases for reporting purposes. A monolithic application has a reporting module, which is responsible for catering to the reporting needs of the application. The reporting module accesses tables and other database objects that belong to other modules to build reporting functionalities.
Centralized reporting ETL (Extract, Transform, Load) tools, such as Informatica and Microsoft SSIS, are used to transform and push application data to a centralized data warehouse. Then, specialized reporting tools, such as Cognos, Microsoft SSRS, and Business Objects, are used to create and publish reports.
In a distributed microservices architecture, reporting across services is a challenge. Each microservice owns its own database and the database level relationships across microservices databases are broken. To build reporting functionalities in a microservices-based application, the data from different microservices databases needs to be brought together. The following sections explain implementation options.
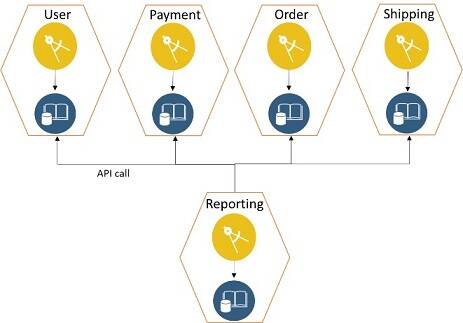
Aggregate via service calls
One of the simplest options that is aligned to microservices architecture is to aggregate by using service calls. Individual microservices expose data as APIs, which can be consumed by the reporting engine. Simple reporting, such as daily reports, can be easily implemented by using this option. The downside of this option is that microservices must have the additional responsibility to build and expose APIs that respond with large data sets. This can lead to performance issues. Figure 15 shows a graphical representation of this option.
Figure 15: Aggregate via service calls
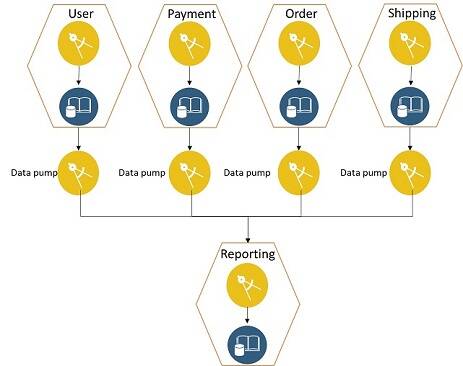
Data pumps
A data pump is a pattern by which data that changes in one microservice is captured and sent to the reporting database. A data pump is very similar to ETL, but its scope is much smaller. A data pump has built-in transformation logic to convert a microservices data format into a reporting data format. Each microservice whose data has to be sent to a reporting database needs to implement its own data pump. The downside of this option is that data in the reporting database is eventually consistent. Also, there are more components to manage with this option. Figure 16 shows a graphical representation of this option.
Figure 16: Data pump
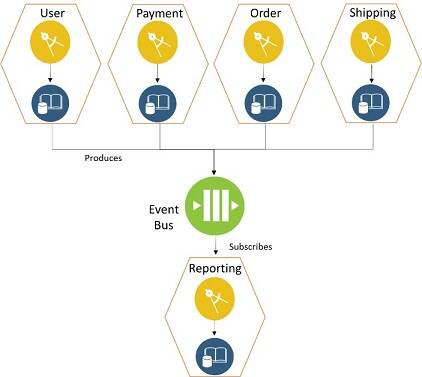
Event-carried state
An event-carried state option is very suitable for microservices applications that follow event-driven architecture (EDA). In EDA, the data state can be published as events, which many consumers can subscribe to and one of them can be reporting. With techniques like event stream and event sourcing, the reporting system can build a data state of entities and transactions in an optimized reporting database. This option avoids database coupling or schema mapping. (Near) real-time reporting is possible with this option. Figure 17 shows a graphical representation of the event-carried state option.
Figure 17: Event-carried state
Summary
It is very important for all stakeholders to understand that modernizing a monolithic application into a microservices architecture is an epic journey and might take many iterations. It is necessary for architects and developers to closely evaluate various aspects of the monolith and come up with a migration approach for each of them. The techniques that are mentioned in this article can help architects and developers decide which capability to decouple and how to migrate your apps incrementally.
Learn more about modernizing your application by exploring the IBM Mono2Micro tool to automate application refactoring and accelerate your application modernization journey by quickly refactoring monolithic applications.