About cookies on this site Our websites require some cookies to function properly (required). In addition, other cookies may be used with your consent to analyze site usage, improve the user experience and for advertising. For more information, please review your options. By visiting our website, you agree to our processing of information as described in IBM’sprivacy statement. To provide a smooth navigation, your cookie preferences will be shared across the IBM web domains listed here.
Article
Anatomy of a cloud storage infrastructure
Models, features, and internals
On this page
At the rate data is growing today, it's not surprising that cloud storage is also growing in popularity. The fastest-growing data is archive data, which is ideal for cloud storage given a number of factors, including cost, frequency of access, protection, and availability. But not all cloud storage is the same. One provider may focus primarily on cost, while another focuses on availability or performance. No one architecture has a singular focus, but the degrees to which an architecture implements a given characteristic defines its market and appropriate use models.
It's difficult to talk about architectures without the perspective of utility. By this I mean the measure of an architecture from a variety of characteristics, including cost, performance, remote access, and so on. Therefore, I first define a set of criteria by which cloud storage models are measured, and then explore some of the interesting implementations within cloud storage architectures.
First, let's discuss a general cloud storage architecture to set the context for the later exploration of unique architectural features.
General architecture
Cloud storage architectures are primarily about delivery of storage on demand in a highly scalable and multi-tenant way. Generically (see Figure 1), cloud storage architectures consist of a front end that exports an API to access the storage. In traditional storage systems, this API is the SCSI protocol; but in the cloud, these protocols are evolving. There, you can find Web service front ends, file-based front ends, and even more traditional front ends (such as Internet SCSI, or iSCSI). Behind the front end is a layer of middleware that I call the storage logic. This layer implements a variety of features, such as replication and data reduction, over the traditional data-placement algorithms (with consideration for geographic placement). Finally, the back end implements the physical storage for data. This may be an internal protocol that implements specific features or a traditional back end to the physical disks.
Figure 1. Generic cloud storage architecture
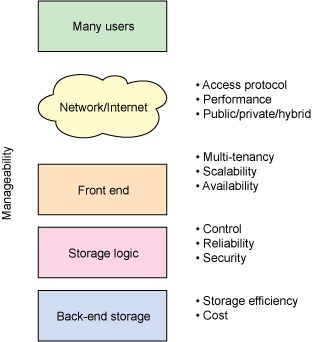
From Figure 1, you can see some of the characteristics for current cloud storage architectures. Note that no characteristics are exclusive in the particular layer but serve as a guide for specific topics that this article addresses. These characteristics are defined in Table 1.
Table 1. Cloud storage characteristics
| Characteristic | Description |
|---|---|
| Manageability | The ability to manage a system with minimal resources |
| Access method | Protocol through which cloud storage is exposed |
| Performance | Performance as measured by bandwidth and latency |
| Multi-tenancy | Support for multiple users (or tenants) |
| Scalability | Ability to scale to meet higher demands or load in a graceful manner |
| Data availability | Measure of a system's uptime |
| Control | Ability to control a system — in particular, to configure for cost, performance, or other characteristics |
| Storage efficiency | Measure of how efficiently the raw storage is used |
| Cost | Measure of the cost of the storage (commonly in dollars per gigabyte) |
Manageability
One key focus of cloud storage is cost. If a client can buy and manage storage locally compared to leasing it in the cloud, the cloud storage market disappears. But cost can be divided into two high-level categories: the cost of the physical storage ecosystem itself and the cost of managing it. The management cost is hidden but represents a long-term component of the overall cost. For this reason, cloud storage must be self-managing to a large extent. The ability to introduce new storage where the system automatically self-configures to accommodate it and the ability to find and self-heal in the presence of errors are critical. Concepts such as autonomic computing will have a key role in cloud storage architectures in the future.
Access method
One of the most striking differences between cloud storage and traditional storage is the means by which it's accessed (see Figure 2). Most providers implement multiple access methods, but Web service APIs are common. Many of the APIs are implemented based on REST principles, which imply an object-based scheme developed on top of HTTP (using HTTP as a transport). REST APIs are stateless and therefore simple and efficient to provide. Many cloud storage providers implement REST APIs, including Amazon Simple Storage Service (Amazon S3), Windows Azure, and Mezeo Cloud Storage Platform.
One problem with Web service APIs is that they require integration with an application to take advantage of the cloud storage. Therefore, common access methods are also used with cloud storage to provide immediate integration. For example, file-based protocols such as NFS/Common Internet File System (CIFS) or FTP are used, as are block-based protocols such as iSCSI. Cloud storage providers such as Six Degrees, Zetta, and Cleversafe provide these access methods.
Although the protocols mentioned above are the most common, other protocols are suitable for cloud storage. One of the most interesting is Web-based Distributed Authoring and Versioning (WebDAV). WebDAV is also based on HTTP and enables the Web as a readable and writable resource. Providers of WebDAV include Zetta and Cleversafe in addition to others.
Figure 2. Cloud storage access methods
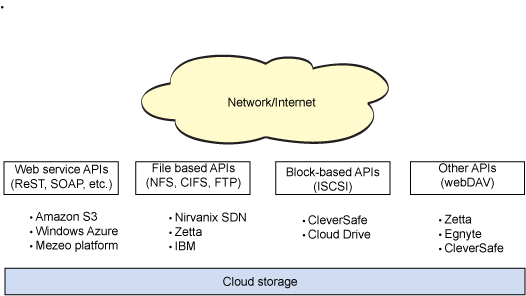
You can also find solutions that support multi-protocol access. For example, IBM® Smart Business Storage Cloud enables both file-based (NFS and CIFS) and SAN-based protocols from the same storage-virtualization infrastructure.
Performance
There are many aspects to performance, but the ability to move data between a user and a remote cloud storage provider represents the largest challenge to cloud storage. The problem, which is also the workhorse of the Internet, is TCP. TCP controls the flow of data based on packet acknowledgements from the peer endpoint. Packet loss, or late arrival, enables congestion control, which further limits performance to avoid more global networking issues. TCP is ideal for moving small amounts of data through the global Internet but is less suitable for larger data movement, with increasing round-trip time (RTT).
Amazon, through Aspera Software, solves this problem by removing TCP from the equation. A new protocol called the Fast and Secure Protocol (FASP™) was developed to accelerate bulk data movement in the face of large RTT and severe packet loss. The key is the use of the UDP, which is the parter transport protocol to TCP. UDP permits the host to manage congestion, pushing this aspect into the application layer protocol of FASP (see Figure 3).
Figure 3. The Fast and Secure Protocol from Aspera Software
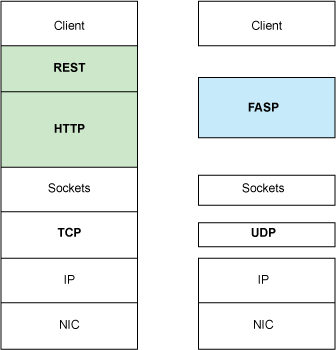
Using standard (non-accelerated) NICs, FASP efficiently uses the bandwidth available to the application and removes the fundamental bottlenecks of conventional bulk data-transfer schemes. The Related topics section provides some interesting statistics on FASP performance over traditional WAN, intercontinental transfers, and lossy satellite links.
Multi-tenancy
One key characteristic of cloud storage architectures is called multi-tenancy. This simply means that the storage is used by many users (or multiple "tenants"). Multi-tenancy applies to many layers of the cloud storage stack, from the application layer, where the storage namespace is separated among users, to the storage layer, where physical storage can be separated for particular users or classes of users. Multi-tenancy even applies to the networking infrastructure that connects users to storage to permit quality of service and carving bandwidth to a particular user.
Scalability
You can look at scalability in a number of ways, but it is the on-demand view of cloud storage that makes it most appealing. The ability to scale storage needs (both up and down) means improved cost for the user and increased complexity for the cloud storage provider.
Scalability must be provided not only for the storage itself (functionality scaling) but also the bandwidth to the storage (load scaling). Another key feature of cloud storage is geographic distribution of data (geographic scalability), allowing the data to be nearest the users over a set of cloud storage data centers (via migration). For read-only data, replication and distribution are also possible (as is done using content delivery networks). This is shown in Figure 4.
Figure 4. Scalability of cloud storage
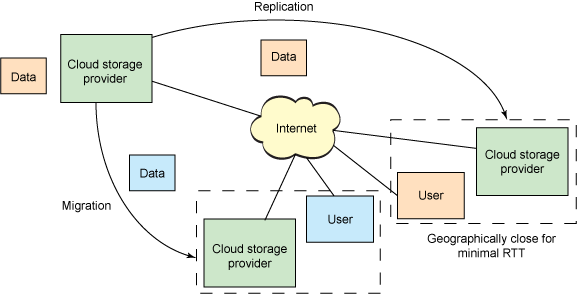
Internally, a cloud storage infrastructure must be able to scale. Servers and storage must be capable of resizing without impact to users. As discussed in the Manageability section, autonomic computing is a requirement for cloud storage architectures.
Availability
Once a cloud storage provider has a user's data, it must be able to provide that data back to the user upon request. Given network outages, user errors, and other circumstances, this can be difficult to provide in a reliable and deterministic way.
There are some interesting and novel schemes to address availability, such as information dispersal. Cleversafe, a company that provides private cloud storage (discussed later), uses the Information Dispersal Algorithm (IDA) to enable greater availability of data in the face of physical failures and network outages. IDA, which was first created for telecommunication systems by Michael Rabin, is an algorithm that allows data to be sliced with Reed-Solomon codes for purposes of data reconstruction in the face of missing data. Further, IDA allows you to configure the number of data slices, such that a given data object could be carved into four slices with one tolerated failure or 20 slices with eight tolerated failures. Similar to RAID, IDA permits the reconstruction of data from a subset of the original data, with some amount of overhead for error codes (dependent on the number of tolerated failures). This is shown in Figure 5.
Figure 5. Cleversafe's approach to extreme data availability
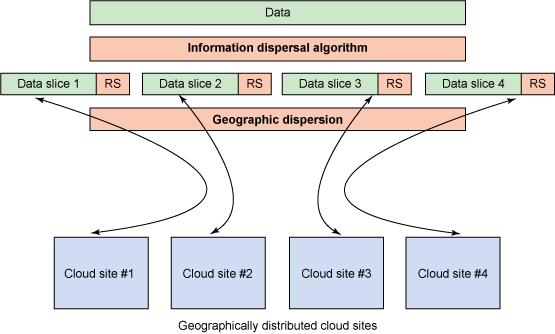
With the ability to slice data along with cauchy Reed-Solomon correction codes, the slices can then be distributed to geographically disparate sites for storage. For a number of slices (p) and a number of tolerated failures (m), the resulting overhead is p/(p-m). So, in the case of Figure 5, the overhead to the storage system for p = 4 and m = 1 is 33%.
The downside of IDA is that it is processing intensive without hardware acceleration. Replication is another useful technique and is implemented by a variety of cloud storage providers. Although replication introduces a large amount of overhead (100%), it's simple and efficient to provide.
Control
A customer's ability to control and manage how his or her data is stored and the costs associated with it is important. Numerous cloud storage providers implement controls that give users greater control over their costs.
Amazon implements Reduced Redundancy Storage (RRS) to provide users with a means of minimizing overall storage costs. Data is replicated within the Amazon S3 infrastructure, but with RRS, the data is replicated fewer times with the possibility for data loss. This is ideal for data that can be recreated or that has copies that exist elsewhere.
Efficiency
Storage efficiency is an important characteristic of cloud storage infrastructures, particularly with their focus on overall cost. The next section speaks to cost specifically, but this characteristic speaks more to the efficient use of the available resources over their cost.
To make a storage system more efficient, more data must be stored. A common solution is data reduction, whereby the source data is reduced to require less physical space. Two means to achieve this include compression—the reduction of data through encoding the data using a different representation—and de-duplication—the removal of any identical copies of data that may exist. Although both methods are useful, compression involves processing (re-encoding the data into and out of the infrastructure), where de-duplication involves calculating signatures of data to search for duplicates.
Cost
One of the most notable characteristics of cloud storage is the ability to reduce cost through its use. This includes the cost of purchasing storage, the cost of powering it, the cost of repairing it (when drives fail), as well as the cost of managing the storage. When viewing cloud storage from this perspective (including SLAs and increasing storage efficiency), cloud storage can be beneficial in certain use models.
An interesting peak inside a cloud storage solution is provided by a company called Backblaze (see Related topics for details). Backblaze set out to build inexpensive storage for a cloud storage offering. A Backblaze POD (shelf of storage) packs 67TB in a 4U enclosure for under US$8,000. This package consists of a 4U enclosure, a motherboard, 4GB of DRAM, four SATA controllers, 45 1.5TB SATA hard disks, and two power supplies. On the motherboard, Backblaze runs Linux® (with JFS as the file system) and GbE NICs as the front end using HTTPS and Apache Tomcat. Backblaze's software includes de-duplication, encryption, and RAID6 for data protection. Backblaze's description of their POD (which shows you in detail how to build your own) shows you the extent to which companies can cut the cost of storage, making cloud storage a viable and cost-efficient option.
Cloud storage models
Thus far, I've talked primarily about cloud storage providers, but there are models for cloud storage that allow users to maintain control over their data. Cloud storage has evolved into three categories, one of which permits the merging of two categories for a cost-efficient and secure option.
Much of this article has discussed public cloud storage providers, which present storage infrastructure as a leasable commodity (both in terms of long-term or short-term storage and the networking bandwidth used within the infrastructure). Private clouds use the concepts of public cloud storage but in a form that can be securely embedded within a user's firewall. Finally, hybrid cloud storage permits the two models to merge, allowing policies to define which data must be maintained privately and which can be secured within public clouds (see Figure 6).
Figure 6. Cloud storage models
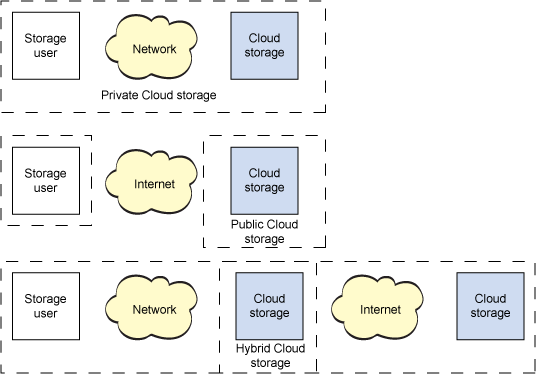
The cloud models are shown graphically in Figure 6. Examples of public cloud storage providers include Amazon (which offer storage as a service). Examples of private cloud storage providers include IBM, Parascale, and Cleversafe (which build software and/or hardware for internal clouds). Finally, hybrid cloud providers include Egnyte, among others.
Going farther
Cloud storage is an interesting evolution in storage models that redefines the ways that we construct, access, and manage storage within an enterprise. Although cloud storage is predominantly a consumer technology today, it is quickly evolving toward enterprise quality. Hybrid models of clouds will enable enterprises to maintain their confidential data within a local data center, while relegating less confidential data to the cloud for cost savings and geographic protection. Check out Related topics for links to information on cloud storage providers and unique technologies.
