Article
Event stream projections for performant and agile applications
Using event streams to increase the agility, scalability, and resilience of accessing back-end dataApplication developers are increasingly being asked to open up new channels or new audiences or to discover new more innovative ways for existing customers to engage with our services. Today’s applications are typically directly engaging with our customers as individuals, across multiple channels simultaneously.
Developers must focus more on the customer experience:
- The responsiveness of the user interface
- Reacting to changes that are occurring through other channels
- The freshness of data no matter what source it comes from
- The degree to which they can personalize the experience
- The need to be always on -- everywhere -- regardless of time, channel, and location.
To deliver these modern applications, application developers need to be able to act quickly, and autonomously, to satisfy the needs of a fast-moving market. Especially when it comes to accessing the enterprise's data.
Their core requirements for modern applications include:
Productivity: Rapid access to new data sets. Obtain access to new elements of data from back end systems with minimal friction.
Robustness: Low latency, highly available responses. Retrieve data with minimal latency and maximum reliability
Data synergy: Application-specific data model. Access data in a form that matches their usage
Scalability: Elastically scalable performance. Scale up the volume of requests by orders of magnitude instantaneously
Data currency. Data should be as closely synchronized with the system of record as possible.
In this article, we discuss techniques to bring the data closer to the consuming applications as local projections. While the concepts we present are not new, the use of event streaming technology to propagate the data is better suited to modern cloud-native applications. Furthermore, we will discuss how the event stream projects pattern provides developers with further opportunities such as a real-time notification, immutable log, time travel, event processing, and retrospective analytics, and it also improves diagnostics and testing.
The techniques we describe in this article are conceptually similar to the concepts of event sourcing and CQRS, which have been niche patterns in the application space for a while but are becoming more commonplace. What we are proposing is using similar techniques, but at the enterprise scale. There are challenges and subtleties to be aware of when scaling these patterns up to the enterprise as proposed in this article. We will discuss these issues and recommend common practices.
The challenge of directly accessing data within existing systems
It is tempting to think that all we need to do to enable a user interface is to gain access to backend systems is to find a way to expose the data directly via a modern RESTful API. This approach works from a basic functional point of view, and it might be relatively straightforward once you find a mechanism for transforming between the back-end protocols or data format and the exposed API. This approach was popularized back in the early 2000s, and it has been iterated on many times as more sophisticated tooling and standards have made it progressively easier to do.
However, these direct synchronous calls that provide an API wrapper around the back-end system have a number of challenges. These issues become increasingly apparent as higher intensity workloads come along, as is typical through digital transformation:
- Latency: Since the APIs make calls directly through to the back-end systems, latency is often unacceptably high for user-facing applications. Even if caches are introduced to help with this issue, latency can become unpredictably variable.
- Availability: Since the back-end system must be accessed directly, any outage is reflected immediately to the front end. As companies become increasingly dependent on their online presence, outages, no matter how small, can quickly become front page news.
- Inefficient usage: When the API does not return data in the exact format required, or when applications need to react to changes in the data results, it's common to see inefficient usage patterns such as chatty aggregations, large data sets returned when only one piece of data is required, or polling to check for changes. All of these actions increase back-end load, which means that the data is harder for the consumer to use.
- Increasing load far beyond designed capacity: As more applications are added, the load on back-end systems will increase beyond any original design considerations, which will destabilize the very systems that need to remain rock solid.
- Increased cost: This direct access pattern introduces costs relating to the back-end system that might not be obvious in the initial design phases. How much do you pay for the extra compute on your back-end system for example? Will you have to improve its reliability or availability? Will you need to increase the operational hours of the back end in line with the consumers requirements?
Event stream projections for data distribution
Projections are local copies of the data from the back-end system. These local copies are populated and maintained by reading from a stream of events coming from the back-end data store. These events are produced by the back-end system every time one of their data records changes.
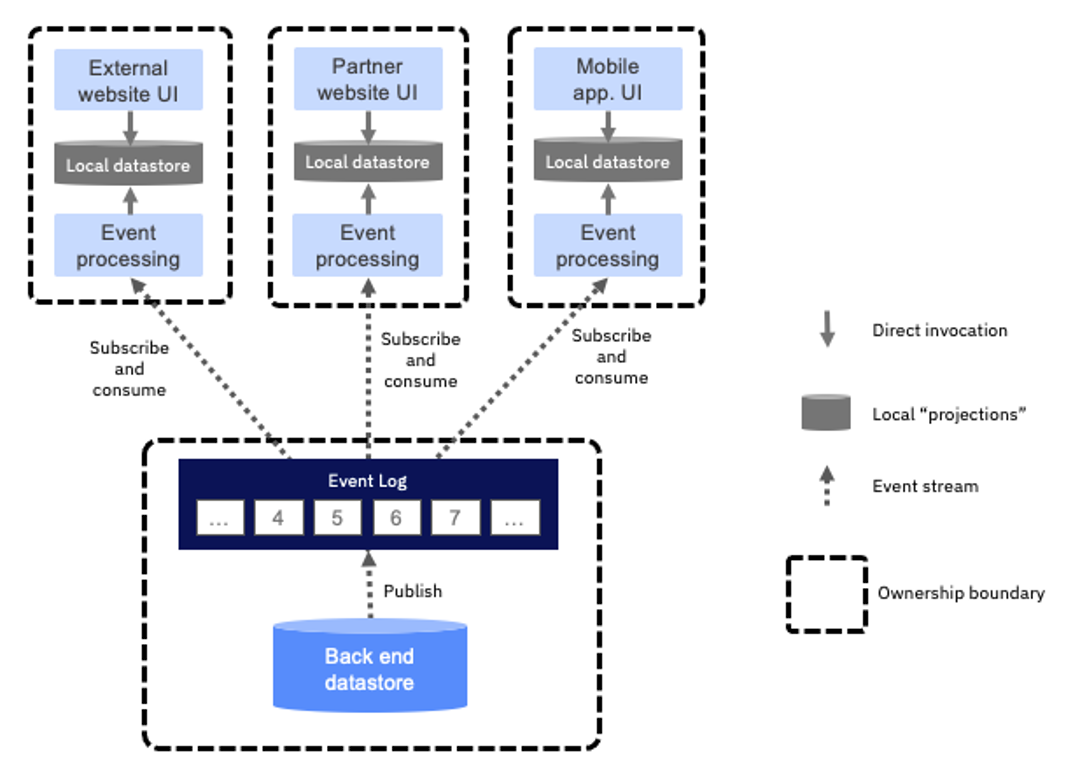
Put simplistically, event stream projections can be described as follows:
- Back-end systems provide a stream of events that represent all the changes happening to their data using change data capture or other techniques.
- Those events are published to an event log (such as Kafka) in order to provide a topic-based event stream for applications to listen to.
- These event streams can then be consumed by new applications, which then build their own local data store with the data optimized into the form they need it.
- These new applications’ user interfaces (UIs) can then query their local data store rather than putting pressure on the main data store.
Apache Kafka is one of the most common event streaming technologies in use today. While this article will not go into implementation detail, it may help to take a quick look at which features of Kafka we might use to implement the event stream projections pattern:
- Extracting events from the back-end data store could be achieved using a Kafka source connector. Equally, the back-end system might already have a mechanism that is capable of calling the Kafka API when data changes occur.
- The receiving application could write code to directly consume Kafka events via its APIs and push them into its local data store. This implementation would provide the most flexibility, but would be the most complex to construct. Alternatives would include using Kafka Streams APIs to process the events and KTables to represent data as local in memory table. Kafka sink connectors could also be used to push data in to a local data store.
The scope of the event sourcing and CQRS patterns is generally within a single application context. With event stream projections, we expand the pattern to a broader enterprise-wide scope.
Clearly there are subtleties when working at this enterprise scope, which need to be considered:
- Does the back end have a mechanism for capturing data changes?
- How is the event stream initialized with the starting state of the back-end data?
- How do we avoid becoming coupled to the back-end data model?
- How much of the source data should we place in the events?
- Are there any data relationship subtleties that we need to design for?
- How important is sequencing of the events?
These and other considerations must be carefully considered to ensure the pattern can scale successfully.
We have described the simplest possible implementation, and the purpose of this article is just to introduce the core concepts. You can consider many interesting extensions to this pattern, such as:
- Composite projections: Creating composite projections from a combination of multiple related event stream topics
- Complex event processing: Performing complex event processing on the stream while ingesting it to gain additional insights.
How are event stream projections different from other existing approaches?
The idea of having local copies of the data from a back end system to improve latency and availability are hardly new. It is the fundamental premise techniques such as caching, data replication, data warehousing and aspects of big data. Let’s briefly explore some of those to see how event stream projections differs.
Caching
The most obvious example of a local copy of data is a cache. Caching is a broad topic. A cache can exist at many (even multiple) different layers in the architecture, and can be populated and refreshed through a wide variety of techniques. Most readers are likely to be familiar with one or more forms of cache so we will not define them here.
Our projection is undoubtedly a form of cache. However, there is one key differentiating factor. The presence of the event stream history enables the data model of the projection to be defined, and indeed re-defined at will, by the consuming application. A new projection can always be re-constructed from the event stream.
Point-to-point data replication
Replication technologies have existed for almost as long as databases. These technologies enable the creation and synchronization of an exact replica in another location. Exact replicas are more likely to be a solution for improving regional latency issues or to enable disaster recovery.
The replication process is typically created and owned by a specialist team rather than by the receiving application. If a different data model is required, that team must do significant up-front modeling requiring negotiations with this separate team, which reduces overall productivity. In contrast, event stream projections are implemented and maintained by the application team in their language or runtime. They can choose (and amend) the target data model and pick whatever type of data store best suits their needs.
Data replication techniques often have an element of batch processing (for example, extract transform load) to enable efficiency with the large datasets being replicated. This can result in the data in the replica becoming significantly out of date while waiting for the next batch run to complete. Event stream projections, in contrast, are near real time, updating the local data store shortly after changes occur at the back end. In an optimized case, the discrepancy could be sub-second.
Replicas tend to breed chains of replicas. It might be hard to update the original replication due to access restrictions, so it often turns out to be easier to create a further replica from the one you already have. Sometimes it’s expedience or sometimes it’s to keep load away from the back-end system, but often it’s because the people involved are not even aware where the data originates. These replication chains can dramatically increase the propagation times for data, and the overall system becomes brittle as failures in the early integrations cause cascading failures further along the chain which are harder to preempt, diagnose and rectify. In contrast, the event streams that are created for projections are designed for reuse, and the technologies involved (such as Kafka) are optimized for large numbers of consumers, so when new projections are required, it makes more sense to go back to the original reusable event stream than to copy from an application-owned replica.
Data warehouses, data lakes, and big data
An extension of data replication takes us to the more formal secondary storage techniques, such as data warehouses, data lakes, and other big data alternatives. In these storage options, the data is siphoned off, typically for the purpose of large-scale analytics and reporting. They require significant infrastructure, resource and planning. There is no question that these techniques remain essential, and indeed may be the only way to resolve some use cases. However, event stream projections enable a much more lightweight and application-owned starting point to explore consumer data requirements. Furthermore, if we start by implementing event stream projections, we can later expand the use of the event stream to populate more formal secondary big data stores as the requirements mature and warrant the extra work.
Event sourcing and CQRS
Some may spot strong similarities between what we are describing as event stream projections and application patterns such as event sourcing and CQRS. The event stream projections pattern is absolutely built on the same principles; an event log acting as an alternative source of truth, and consumers building their own projections from that log.
However, we have deliberately avoided using those terms so far because there are some important differences in what we are describing with this pattern:
- Source of truth: A purist's "event sourced" pattern might well treat the event log as the primary data store itself. In our pattern, we have an existing data store, such as a legacy system that we likely cannot change or remove and that will continue to be the source of truth.
- Scope: Both event sourcing and CQRS make use of Domain Driven Design concepts to ensure that the event source is modeled and scoped correctly. A key principle is that the scope of an event-sourced system should only be within a bounded context. We propose that event stream projects might well be used across bounded contexts. Where this is the case, it is critical to introduce indirection with a transformation layer (anti-corruption layer), and clearly separate events that are internal to the context from the domain events that may travel between them.
- Command pattern: The C in CQRS refers to the Command pattern. Changes to data should ideally be done via asynchronous commands which further reduces the contention on the back-end system if multiple parties are attempting to update data concurrently. We are not making this command aspect a mandatory part of our pattern, but it is a perfectly appropriate additional feature.
Benefits of event stream projections
Let’s look back at our original requirements and see how event stream projections addresses them.
- Productivity: Rapid access to new datasets. If the data is successfully exposed as events by the back-end teams, all the data is there in the event streams; the application team just needs to decide what they want to store. They own the local data store, and they can create new ones or amend existing ones without affecting anyone else. Furthermore, access to the event stream is self-service. There is no provisioning or implementation lag while you wait for another team to provide access to a data store or build an integration – you can just do it yourself. Indeed, when performing this pattern at an enterprise scale, application ownership of the projection is critical to agility.
- Robustness: Low latency, highly available responses. The application team can place their data store wherever they want (regionally, and from a network perspective), and store the data in the most efficient form for the type of queries they will want to do. Performance and availability are in their hands.
- Data Synergy: Application specific data model. Since the application team are populating their own local data store, they can ensure it matches the data model of their application and change it whenever they want.
- Scalability: Elastically scalable performance. The choice of data store implementation is in the hands of the application development team rather than being dependent on the back-end system's scalability. The team can choose a data store topology suited to their scalability needs, and update that topology and rebuild the data store from the event stream if required.
- Data Currency: Near real time data. The projections are constantly being updated, and might well only be a fraction of a second out of date in comparison to the back-end system. This is current enough for many application use cases and of course significantly better than the lags introduced by batch-based updates.
Central to all these benefits of event stream projections is the clear separation of ownership promoted between providers and consumers, which is provided by the use of an event stream. This separation reinforces the point that the pattern is operating at an enterprise scale, with the provider and consumer each in different parts of the organization. The provider’s only responsibility is to make events available in a stream. The consumer then takes on the transformation, scalability, availability, resilience, and data currency. In the past, we might not have wanted to push these responsibilities to consumers, and preferred to provide a one-size-fits-all, centralized capability, catering to the high watermark of all requirements. With the increasing diversity of needs from consumer applications, and the increased simplicity of provisioning and scaling their own infrastructure, consuming applications now prefer the increased autonomy rather than being tied to the release cycle of a centralized infrastructure.
Potential challenges with event stream projections
We’ve been keen to articulate the benefits of this pattern, but it is only fair and balanced to consider some of the potential challenges too. Here are some common adoption considerations.
- Data consistency. Is “eventual consistency” good enough for your particular application’s requirements. How will the application using the data cope with the fact that it will always have data that is potentially (slightly) out of date.
- Datastore rebuild timeframe. If the event stream really is going to be treated as the source of truth for the application, then if the application for some reason needs to rebuild the local data store, it will need to read all relevant records in the stream. This could be the entire stream, or at least a significant time window within it. Is the time this will take acceptable for the applications non-functional requirements? Do you need mitigate these issues by reducing the window, or by initiating the datastore rebuild prior to cut over, or through features such as log compaction in Kafka?
- Idempotence. Do duplicates matter to the data model in the local data store. Streaming technologies, due to their need for high performance, are often not transactional in the way you might be used to with traditional ACID-style databases and queuing technology. Duplicate events can occur, and consumers must be designed to handle this or can result in data integrity issues.
Capitalizing on the event history
We've focused primarily so far on how event sourcing enables us to bring a copy of the data close to the front-end application and its user interface, and the performance and availability benefits of that.
However, the above are only the benefits directly associated with data access. There are many more things that event streams bring to the table. Event streams implementations such as Kafka, have an event history, such that consumers of events can not only receive new events but also access past events. This brings us a number of new opportunities:
- Responsiveness. The ability to react to events as they occur.
- Immutable log. In most implementations (including Kafka), this event history is immutable, providing an implicit audit trail. There are many opportunities for use of this log from a security and audit point of view.
- Time travel. Through the event history, we can wind back or forward through time. For example, we could re-run a report as it would have looked last month,
- Event processing. By looking at a set of events over a time period we can often find new insights. We could look for periodic patterns in someone’s buying behavior or spot patterns of fraudulent activity.
- Retrospective analytics. We can re-run analysis of the data bring us new insights from old data, and continuously refine our thinking.
- Replay-based testing. We can perform a simulation of past data to ensure that it exhibits the expected behavior.
- Diagnostics. We can inspect, and even simulate, conditions that led to an error.
Adopting event stream projections
The decision to use an event stream projections approach should be based on one or more clear business needs. Event stream projections should not be the default for data access in every case.
- If you just need low volume create, read, update, and delete (CRUD) operations to a simple local data store, and the history of changes isn’t important to you, you don’t need event stream projections.
- If you need to scale an existing legacy system to 1000s of consumers concurrently accessing the data 24/7 whilst retaining low latency responses with different categories of consumer each having different requirements on their view of the data, and if you need to implement an audit trail, and you might welcome the ability to re-process past events, then you almost certainly ought to be looking at event stream projections.
Start simple
Don’t be tempted to over reach in the early stages.
- Ideally, the first project will have a minimal number of consumers – perhaps only one.
- Introduce just enough infrastructure to get going. Kafka as an example, is designed to scale up naturally in a variety of different ways.
- Separate the producer and consumer roles. The producing system owns change capture to the event stream, and making the events available for subscription. The consumer owns subscribing to the event stream, building their local datastore, and making that available to their application. Without this delineation, the pattern cannot scale to larger numbers of consumers.
- Allow time to get used to the event stream paradigm. Many things are counterintuitive.
- If this first project has surfaced a valuable source of events, the next consumer of events will likely be self-selecting, as the need for that data will be expanding.
Recognize the enterprise scale objectives
- Decentralized ownership: If a key value proposition for you is for the consuming applications to be more agile and autonomous, ensure they can build their projections completely independently of the Kafka implementation. You'll want minimal dependencies on other infrastructure.
- Operational consistency: You need to ensure that the streams infrastructure can be provisioned and maintained in an operationally consistent way in increasingly hybrid and multi-cloud landscapes. Furthermore, you need to be able to explore blended options for how the infrastructure is managed. In some instances, applications will want to self-manage; in others, they will want a fully managed service, and they will want to be able to change their mind over time.
- Event governance: Since the events will be exposed to multiple potential consumer audiences, we need to consider how we will govern access to the event streams, enable discovery of them, provide for data privacy measures, and more. Simply making a Kafka endpoint available would not achieve this. We would expect to see a similar approach to event management as we typically see over API management today.
- Beyond Kafka: Note that Kafka alone does not enable this pattern, as the pattern requires additional capabilities around event capture, transformation, composition, connectivity to data stores, API management, and more. All these capabilities need to be meaningfully integrated with the event streams, and any licensing should be flexible enough to enable the proportions of each to change over time.
Conclusion
Event stream projections are an enterprise scale extension of known application patterns. They provide a powerful alternative for accessing data compared to both direct access and batch replication. Projections provide potential benefits in many areas including productivity and robustness and the presence of an event history opens up new possibilities for innovation.
Success is dependent on more than just the simple introduction of a technology such as Kafka. Implementing this pattern at enterprise scale needs careful design and a recognition of the enterprise scale considerations.