Article
Where did my storage go?
Five kinds of temporary storage used by IBM DB2 for i SQL Query EngineThe storage story
If you've had the experience of preparing and serving a fine dinner, you know that the number of items used in the kitchen is often several times larger than the number of dishes delivered to the table. Preparing something as simple as a tossed salad may require the use of multiple bowls, colanders, and cutting boards before the final creation is ready to be served. Though each container may be used only for a short amount of time in preparation, putting a meal together would be difficult without them.
Like a chef at a five-star restaurant, the SQL Query Engine (SQE) seeks to serve you quickly with the very best results. And like that chef, SQE often needs extra working space. It obtains this by allocating temporary storage both to optimize and to run queries.
Most of the time, you won't need to think about or be aware of the state of temporary storage on your system. IBM i storage management and its finely tuned algorithms take care of keeping your workloads running smoothly. Occasionally, though, you may see a poorly written query or a bad plan that leads to excessive temporary storage usage. SQE will prevent a query from exhausting the system's storage, but the excessive storage usage of one or a handful of queries can still have an adverse impact on other IBM i workloads. Sometimes, the increased storage usage points to a bad data model or a poorly written query. You (or your database engineer) must be able to detect a situation like this, as well as clean it up and prevent it from reoccurring. Doing this requires you to understand why the temporary storage is needed and what normal looks like for a healthy database workload on your system. There are a number of IBM i tools that can assist you, but before you can start using those tools effectively, you need to have a foundational understanding of the SQE storage story.
In this article, we'll lay that groundwork by exploring the five kinds of temporary storage that SQE uses. On IBM i, the authoritative source for temporary storage information is the QSYS2.SYSTMPSTG view. Within this view, system-wide temporary storage is identified by the presence of a value in the GLOBAL_BUCKET_NAME column. The most important bucket names for SQE begin with "*DATABASE". Note that the job-specific buckets that are returned by SYSTMPSTG do not account for the temporary storage used by SQE. SQE storage is only shown in the global buckets.
Figure 1. Querying SYSTMPSTG
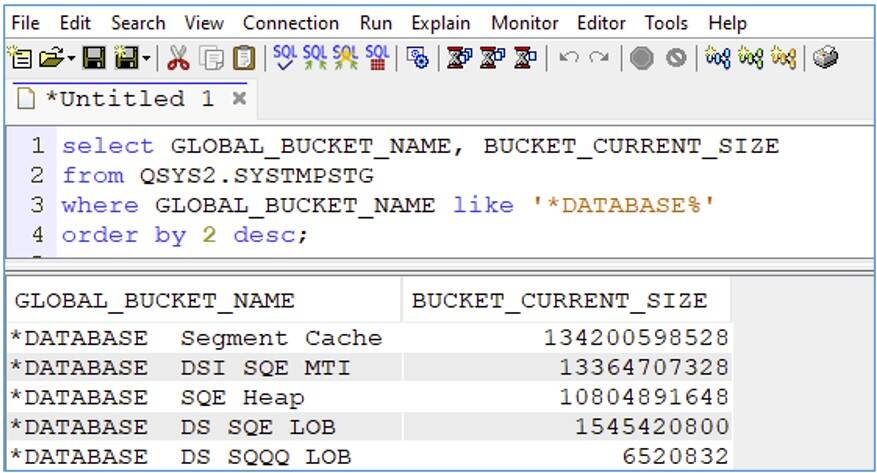
All five *DATABASE buckets (shown in Figure 1) can be relatively large on a system with high SQL activity, but they play an important role in enabling the query engine to deliver results quickly. All buckets will also tend to reach a (relatively) steady state for a given workload. However, it might take time to reach this steady state. And remember, these allocations are being made from temporary storage, so they disappear at initial program load (IPL). Consequently, it might take hours or days after an IPL for the storage usage to level off. It is important to realize that this is normal. Becoming familiar with what normal looks like for your system and database workload is a key piece of information for detecting and diagnosing a potential problem.
Temporary storage is always allocated from the system disk pool—also known as the system auxiliary storage pool (ASP). This holds true for SQE temporary storage even if the permanent objects (tables and indexes) holding your data are in user ASPs or in independent auxiliary storage pools (IASPs). This means that a database workload running with sufficient free space in an IASP might still struggle if the space in the system ASP is constrained. This becomes even more important if you have multiple workloads across multiple IASPs. An efficiently running database requires adequate storage in the system pool to accommodate the temporary storage needs of all the ASPs and their workloads.
Of the five SQE buckets, the most significant are "*DATABASE SQE Heap", "*DATABASE Segment Cache", and "*DATABASE DSI SQE MTI". These are usually the largest buckets, and we will devote the most attention to them. The other two buckets, "*DATABASE DS SQE LOB" and "*DATABASE DS SQQQ LOB", are discussed briefly at the end of this article.
*DATABASE SQE Heap
The first bucket we will look at is "*DATABASE SQE Heap". The heap is storage that the query engine's optimizer uses as a temporary scratch area while it is processing and optimizing the query. Internal data structures necessary for optimization are continually allocated and de-allocated from the heap. Most SQE heap storage is only used for a short time and is returned to the system when the optimization is completed. The size of the "*DATABASE SQE Heap" will generally correlate to the number and complexity of queries actively being optimized.
*DATABASE Segment Cache
Storage for data that needs to persist beyond the optimization phase of a query is generally allocated from a different bucket: "*DATABASE Segment Cache." Let’s look at the largest users of this “segment” storage.
When it comes time to run SQL queries, the query engine might need some amount of storage (allocated in segments) to temporarily hold your data while it is processed. This data is contained in query runtime objects—structures like lists, buffers, and hash tables. These runtime objects implement functions and features such as sorting, aggregation, and buffering for symmetric multiprocessing (SMP).
Segment storage is also used to implement the SQE plan cache. (In earlier releases, heap was used for parts of the plan cache, but current versions of IBM i rely on segment storage.) The plan cache is where plans are saved, allowing the same query to run multiple times without going through the optimization process on each execution. It is described in more detail in IBM Documentation. As a repository for optimized access plans, the plan cache must retain enough information to run an access plan the next time a cached query is run. The amount of storage allocated for the cached plans is limited by the plan cache size. This size is usually managed by the query engine. This size can also be explicitly set by a user with appropriate authority. However, doing so is rarely necessary.
At the optimizer's discretion, the temporary runtime objects allocated for a query may also be stored in the plan cache once a query has completed. This allows a subsequent run of the query to skip some of the work of re-populating these temporary objects (if the underlying data source hasn't changed.) As a general rule, as the plan cache grows larger—within the constraints of the system's configuration and the optimizer's internal management—there will also be more cached temporary objects.
When the runtime objects are no longer needed, the associated segments might not be immediately returned to the system. Instead, a limited amount of this storage is placed into the Segment Cache proper, where it becomes available for other queries to use. This is done to avoid some of the expense of allocating and de-allocating storage from the system. This cached storage is also included in the value reported for "*DATABASE Segment Cache."
In summary, the "*DATABASE Segment Cache" generally reflects both the number of active queries on the system and the number of cached plans and temporary runtime objects in the plan cache.
*DATABASE DSI SQE MTI
Maintained temporary indexes (MTIs) are internally generated indexes available to assist the query engine both with optimizing and with running queries. Structurally and functionally, these indexes are identical to permanent radix indexes created by a user, but they are managed entirely by the query engine. Like user indexes, each MTI is associated with a specific table, but unlike user indexes, all the data resides in temporary storage. The storage used for MTIs is tagged as "*DATABASE DSI SQE MTI" in the SYSTMPSTG view. The lifecycle of an MTI and its corresponding memory allocations might vary depending on its purpose, its usage, and other factors. For more information, see IBM Documentations and the related article Manage your MTIs.
The LOB buckets
As you may have surmised from the names, the last two buckets are specific to the use of database large objects (LOBs): character large objects (CLOBs) and binary large objects (BLOBs). This also includes the use of XML expressions, which are internally implemented with LOB allocations. The "*DATABASE DS SQQQ LOB" bucket temporarily holds large object data while a query is being processed. After the query is closed, the storage is freed. The "*DATABASE DS SQE LOB" bucket is more closely related to the Segment Cache bucket, because it provides storage for large objects referenced by query runtime objects. Consequently, in situations in which query runtime objects are retained along with cached plans, any associated LOB storage will also remain allocated. Of course, a system with little or no LOB data will likely see small allocations for these two buckets.
Bon appetit!
Putting all these pieces together, we can see that the bucket labeled "*DATABASE SQE Heap" is primarily for storage currently in use by the optimizer. The bucket labeled "*DATABASE Segment Cache" includes storage for cached plans and temporary query objects, data currently used by the running queries, and storage cached for quick reuse. "*DATABASE DSI SQE MTI" is for maintained temporary indexes that the optimizer chose to build. The LOB buckets facilitate the efficient usage of large objects. Each of these buckets is essential to the work that SQE performs to answer your queries quickly.
Now that we've finished our brief tour of the SQE “kitchen”, I hope you have a clearer understanding of what the chef is doing back there and why he's making such a racket with all those pans. There really is a method to his madness, and the end result is quick and efficient query execution.
Related topics
Once you understand the basics of SQE temporary storage usage, you can learn how to set limits on the amount of storage that your queries use.
If you need assistance with understanding query optimization, or with further details about IBM DB2 for i, you can contact my colleague Kent Milligan with IBM Technology Expert Labs. You can reach him at kmill@us.ibm.com.