Article
Using the RTVDSKINF command to avoid disk storage disasters on IBM i
How a standard control language command can relieve anxiety over storage limitsArchive date: 2021-03-30
This content is no longer being updated or maintained. The content is provided “as is.” Given the rapid evolution of technology, some content, steps, or illustrations may have changed.Profile of a not-so-rare library problem
Like many tales of woe, this story begins innocently enough. I received the go-ahead to perform a disaster recovery audit on my client's IBM i system and was looking at their current tape backup scheme. I ran the Display Backup List (DSPBCKUPL) command, which is surely one of the most useful and underrated commands in the operating system, and printed its list of libraries. This command is a good way to determine the time when a library was last completely saved and whether any objects within that library have changed since then. I noticed that one library, SXDATA, had not been saved since July 2009!
My client's backup routine calls for all the user libraries to be saved each night using the Save Library (SAVLIB) command. This library should not have been skipped, and my client and I could not find any omit statements in the backup program that would have excluded it. To everyone's horror, we realized that this library contained important data and maintained invoice records going back many years. Without getting more melodramatic, we were extremely relieved that IBM i is so reliable because this library did not exist on any of the backup tapes. Any computer room disaster that required a full recovery of the system would have sunk the business as this library would have been lost for good.
Reviewing the history logs and job logs of the backup did not produce a smoking gun. We only saw this cryptic message:
CPF3770 Diagnostic No objects saved or restored for library SXDATAThis was not as simple as a few damaged objects being omitted from the backup. The entire library was being passed over. To make things worse, efforts to display the contents of the library proved fruitless. Commands such as DSPLIB SXDATA seemed to go into a loop, and we ran out of patience waiting for the response at the 40-minute mark. We knew that the data existed because programs accessing the files were working. We just could not work with the library in total. Attempts to save the library by itself, with the save-while-active feature, resulted in the same diagnostic message. We were also dismayed that the error message was not more conspicuous. Message text with a little urgency, such as Hey, you just skipped a COMPLETE library!, would have been welcome.
Fortunately, when we knew which library was in trouble, we were able to diagnose the problem. We had unknowingly brushed up against a size limitation within the IBM i operating system. There is a nebulous limit of the number of objects in a library, and when you get near it, unpredictable results will occur. This limit, quoting from the IBM i Information Center, is approximately 360,000 objects. The result of approaching that limit was the inability to save the library and the failure to display the list of the library's contents. With some help from the programming team, we were able to weed out enough objects to solve the problem and avoid a close encounter with Murphy's Law.
The importance of knowing your limits
The problem I just described opened my eyes to an issue that is likely to be lurking on many IBM i systems. Systems are getting larger, and more data is being created and maintained online. In the 1980s and early 1990s, few IBM AS/400® systems had more than one terabyte (TB) of disk space. Now it is common to have that much disk storage on the smallest IBM POWER7® processor-based system. In addition, there are systems that have been in productive use for decades, and the data is piling up. It follows then that you need to be more mindful about the file and database limits to avoid problems that may range from incomplete backups to impaired performance to unpredictable results.
IBM documents these limits for the currently supported releases (V5R4, V6R1, and V7.1) in their respective Information Centers. See Related topics for links, but Figure 1shows the major limits.
Figure 1. Key file system limits for IBM i 7.1

Note that this table comes from two different sections of the Information Center. The file system limits are from the Availability chapter, while the database file sizes are from the Programming section.
Difficulty getting alerts when files approach their limits
The system generates warning messages when it reaches the threshold of total disk space used—typically when the disks are 90% full. However, there do not seem to be any similar warnings when an individual library or a data file approaches its limit. Therefore, it is up to the system administrators to track the growth of the libraries and the data files. By knowing that trouble is brewing, you can take measures to reduce the number of objects before a real problem occurs. Fortunately, there are tools within the operating system to help.
Using the RTVDSKINF command to collect disk usage data
You can avoid the anxiety of incomplete backups by keeping track of the objects stored on IBM i and watching as they grow and approach the IBM i limits. Table 1 lists the key measurements to watch.
Table 1. Key measurements to watch on IBM i
| Measurement | Recommendation |
|---|---|
| Total disk usage | Keep below 70% for best performance. For good capacity management, information technology (IT) departments should always keep track of this measurement to anticipate when a disk upgrade or data archiving is needed. |
| Total size of each library | See which libraries are using the most space or growing the fastest. |
| Total number of objects | See which libraries have the most objects. Note milestones such as 150,000, 200,000 and 250,000 objects to avoid the problem described at the beginning of this article. |
There is no command that can display the total size of a library, although the Display Library (DSPLIB) command provides a total if you choose the print option. That said, IBM has long provided an excellent tool to gather information about all the libraries in one fell swoop: the RTVDSKINF command.
You must submit RTVDSKINF as a batch job, but it serves a vital function for system management. It collects data on all the objects on the IBM i (with an emphasis on the library objects) and puts it in the QAEZDISK file in the QUSRSYS library. You can display the information in a report using the Print Disk Information (PRTDSKINF) command. The report provides a summary of the amount of space that is used by the various types of objects ( Figure 2).
Figure 2. PRTDSKINF report — system summary

In this example, you can see that 71.35% of the disk space is used by the user libraries (libraries that not used for IBM software products). User directories, part of the integrated file system (IFS), use 4.69%. The value of 20.13% for unused space leads to the conclusion that the total disk space was 79.87% full at the time the PRTDSKINF command ran.
Depending on the values you use in the PRTDSKINF command, it presents a list of all the libraries along with their total size ( Figure 3).
Figure 3. Library section of the disk report from the PRTDSKINF RPTTYPE(LIB) command
Creating a file that holds the data from each RTVDSKINF process: An SQL example
Having this data in a report is nice, but ideally you want to keep this information in a file and add data from each subsequent running of the RTVDSKINF command. Then you can mine this data to show the growth of objects in each library and the total disk space used over time.
This is a challenge because RTVDSKINF overwrites the QAEZDISK file each time it runs. Therefore, you need to establish a new file that holds the data from each RTVDSKINF process along with a date field. You can do this with a high-level language program, but even a simple Query/400 program works.
Structured Query Language (SQL) statements can extract and summarize data from the QAEZDISK file after the RTVDSKINF job ends. Listing 1 shows a statement that creates the table (called EDLIB/EDDISKDATA) that holds this data based on the QAEZDISK file format.
Listing 1. Sample SQL CREATE statement to set up table for holding data
CREATE TABLE EDLIB/EDDISKDATA (LIBRARY_NAME ,
OBJECT_COUNT , TOTAL_OBJECT_SIZE , DATE) AS
(SELECT diobli, count(diobnm), sum(diobsz), current date
FROM qusrsys/qaezdisk WHERE diobli <> ' '
GROUP BY diobli ORDER BY diobli)
WITH NO DATAListing 2 shows the statement that gathers the data from the last RTVDSKINF job and inserts it into the new file.
The input fields are:
diobli(library name)diobnm(name of object)diobsz(size of objects)current date(insert the current date)
Listing 2. Sample SQL to select and periodically add data to table
INSERT INTO edlib/eddiskdata
SELECT diobli, count(diobnm), sum(diobsz), current date
FROM
qusrsys/qaezdisk
WHERE DIOBLI <> ' '
GROUP BY diobli ORDER BY diobliFigure 4 contains a sample of the data resulting from these procedures.
Figure 4. Sample output of the EDDISKDATA file

Creating a file that holds the data from each RTVDSKINF process—Query/400 example
The following is an example of a Query/400 definition that launches after the RTVDSKINF batch job completes. It gathers data records from the collection and adds them to a file so that the data accumulates.
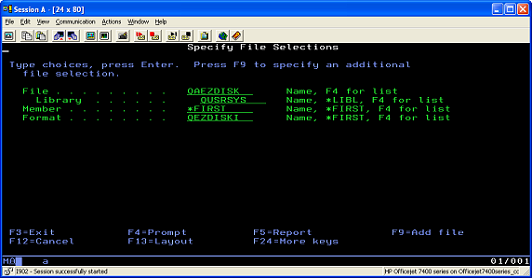
- Select QAEZDISK in the QUSRSYS library as the source file ( Figure 5).
Figure 5. Selecting QAEZDISK as the source file
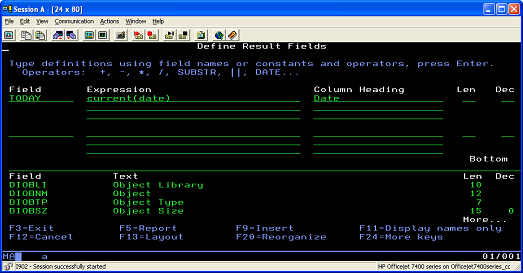
- Create a new field, called TODAY, that contains the current date and add it to each record ( Figure 6).
Figure 6. Creating a new field that contains the current date
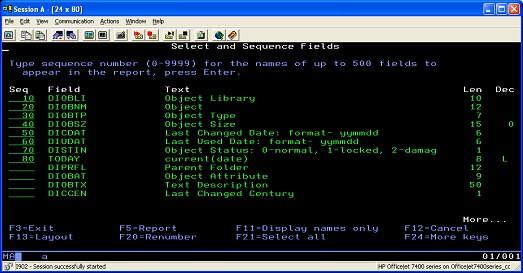
- Select the following fields to use in the new file ( Figure 7):
Object Library
Object
Object Type
Object Size
Last Changed Date
Last Used Date
Object Status
current(date)
Figure 7. Selecting the fields to use in the new file
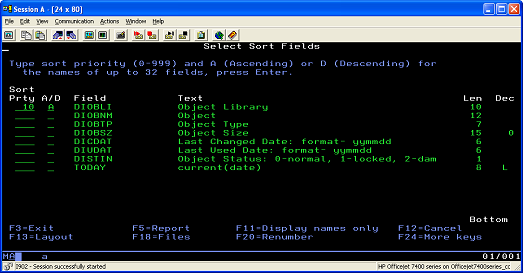
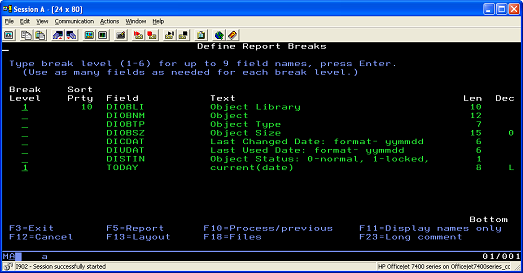
- Specify that the new file sorts by library name ( Figure 8).
Figure 8. Sorting the file by the library name
- Specify the following summary functions for the report ( Figure 9):
Count of objects (to get the total number in the library)
Total of object size (to get the total size of the library)
Figure 9. Specifying summary functions for the report
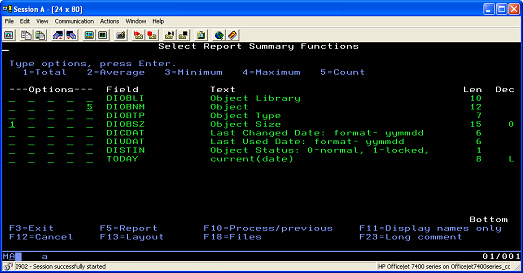
- Define the report breaks for the Object Library and current(date) fields ( Figure 10).
Figure 10. Defining report breaks
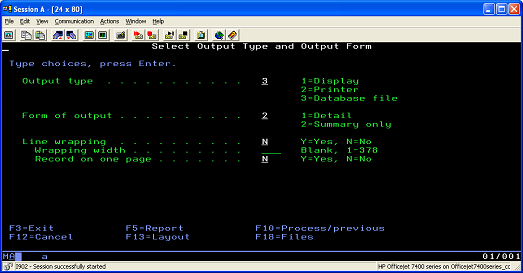
- Specify that the output records will be placed in a database file with
Summary onlyas the output form ( Figure 11). This means that you will capture only the following fields: Object Library Object (total count only) Object Size (total only) current (date)Figure 11. Specifying the output records that will be in a database file
- Add the latest data records to the existing file member ( Figure 12). This means that you will accumulate data from each
RTVDSKINFjob. In this example, the file that contains the data is EDLIB/EDDISKDATA.Figure 12. Adding the data records to the current file

You can make the query more elegant by selecting specific library records and by formatting the date in a yymmdd format so that it is easier to sort.
After you run this query (or comparable program), you can download the updated file into a spreadsheet for analysis ( Figure 13).
Figure 13. Spreadsheet of the library data for each week — filtering is allowed

Using the Microsoft® Office Excel pivot tables, you can put this data into a chart showing the change in the library size over time ( Figure 14).
Figure 14. Chart showing the change of specific library sizes from week to week

Another view of the same data table shows the total number of objects in each library ( Figure 15).
Figure 15. Libraries containing the most number of objects over time

Now that you maintain this data in a single file, you can use more elaborate routines to look for specific criteria. For example, you can scan the file for libraries whose total number of objects exceed 200,000 or for libraries that grow in size by more than 10% from week to week. You can have a warning email or operator message sent if these conditions occur so that IT support is not caught off-guard when the size limits are reached.
Monitoring files using the SYSPARTITIONSTAT view
While the RTVDSKINF command is useful, it does not capture information about the current number of records or members in a physical file. As shown earlier, these are attributes that also have limits within IBM i. You can use an approach similar to the one for library sizes to maintain physical file members. In this case, you can run an SQL SELECT statement against the QSYS2/SYSPARTITIONSTAT view to get real-time information about the members in a physical file. See Listing 3 for an example.
Listing 3. SQL statement extracting data from the QSYS2/SYSPARTITIONSTAT view
SELECT table_schema, table_name,
number_rows, data_size, table_partition FROM syspartitionstat WHERE table_schema =
'QGPL'IBM introduced the SYSPARTITIONSTAT view with the V5R4 release of IBM i. This view makes it simple to retrieve the number of records for a member without having to first run a Display File Description (DSPFD) command to copy the member information to an output file.
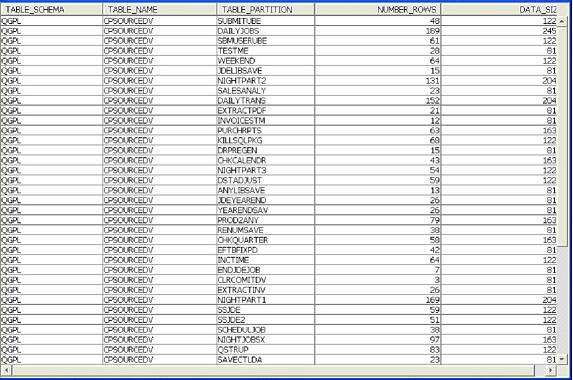
The result of this SQL query ( Figure 16) includes data records containing :
- TABLE_SCHEMA (analogous to the library name)
- TABLE_NAME (analogous to the physical file name)
- TABLE_PARTITION (analogous to member name)
- NUMBER_ROWS (analogous to the number of records)
DATA_SIZE (the size of the table partition)
Figure 16. Results of the SQL statement against the SYSPARTITIONSTAT view
You can use all of these in a query to monitor the number of records and members that accumulate over time.
Conclusion
It is clear that you cannot easily dismiss the file and database limits that IBM has documented. Fortunately, there are tools available to provide information about how files and libraries are growing. Even if your system is far from the size limits, these tools provide an excellent way to manage the storage capacity.