Article
Monitoring Apache Kafka applications
Best practices for monitoring, debugging, and analyzing Kafka systems and Kafka appsDevelopers have many different ways to run an Apache Kafka cluster. You can use the open-source distribution of Apache Kafka, the Strimzi project (which is a Cloud Native Computing Foundation sandbox project), or a proprietary version such as Confluent that includes support. Also, you can choose to use a fully managed Kafka cluster like IBM Event Streams on IBM Cloud.
However you choose to run Kafka, monitoring is a fundamental operation when running Kafka or Kafka applications not just to debug problems that have already happened but also to identify abnormal patterns of behavior and prevent issues ahead of time. There is a misconception that if you are using a fully managed service, monitoring Kafka metrics is not necessarily important. This is just not true; even running in a fully managed Kafka cluster, you must ensure that you instrument and maintain your Kafka applications correctly.
Developers have numerous metrics available to them when using Kafka, but the sheer number can be overwhelming, which makes it quite challenging to know where to start and how to properly use them. This article will introduce you to some of the key Kafka client metrics that you should collect and overall monitoring best practices.
Monitoring system
Kafka brokers and clients emit metrics that show point-in-time data for various statistics. JMX is the most used mechanism to export these metrics.
You can use tools such as Prometheus to scrape data and Grafana to plot graphs for visualizing the data. Some of these metrics can also be used to warn you about abnormal behaviors and trigger alerts for critical issues.
The following figure is an example monitoring system at a high level:
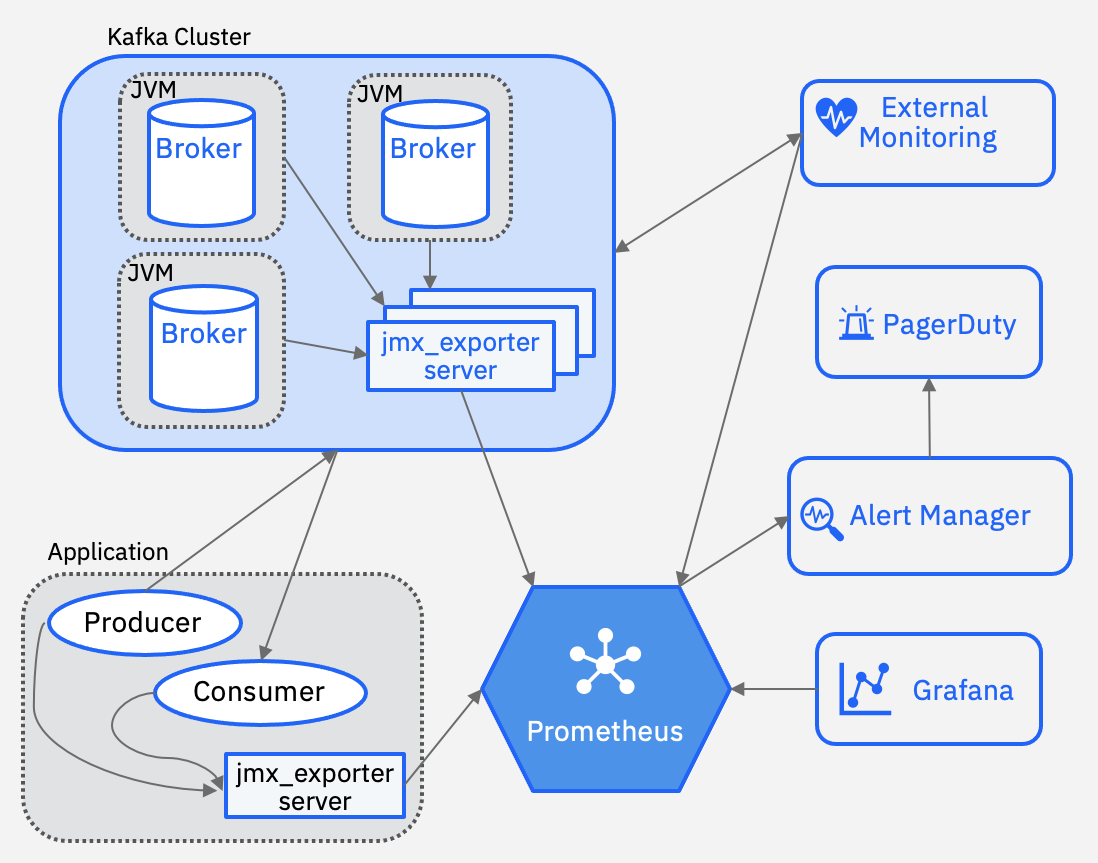
Best practices for monitoring Kafka systems and Kafka applications
When setting up monitoring, consider these best practices:
Start with a small set of metrics. It can get very overwhelming if you try to use all the possible metrics, which will lead to information overload and make it difficult for the operations team to understand them. Therefore, it's good to start with just a small set of metrics and give yourself time to learn and understand the trends to the data that the metrics produce.
Alert on carefully selected data. As I mentioned previously, you can use the metrics to warn you of issues that might lead to potentials problems and trigger alerts when things go wrong. However, when alerting on these metrics, take care to avoid unnecessary noise. Also, make sure that the alerts are well understood and have clear actions documented for debugging and resolving the issue being reported. So, when you introduce a new alert, use it to only issue a warning rather an alert. Then, you can observe how much noise it is producing, whether it needs further tuning, and learn how to debug and solve the problem it’s reporting. Once the operations team is confident with how to deal with it, it can be upgraded to an alert.
Iteratively improve your monitoring. After an incident, go back and analyze what the shape of data your existing metrics showed, whether there are any other metrics that could have helped you better understand the issue, or whether any of your existing metrics could have been used to warn you ahead of time. As you learn more from the trends produced by the metrics and identify gaps in your monitoring from incidents that happened, you can keep refining the metrics that you collect and tuning the alerts as needed.
Watch out for no metrics. This practice may seem obvious, but it is something you can definitely miss. Make sure that you are monitoring the "liveness" of your monitoring tools.
Kafka client metrics
You can use this list of client metrics as a starting point, but the metrics that you need to collect might be slightly different depending on your use case.
The following metrics are some of the most common metrics monitored for Kafka client applications which you could use as a set of metrics to start with. However, the set of metrics chosen to be monitored and what they mean can be very different depending on the use case so you will likely want to monitor more metrics than what is listed below. With most client metrics, you would need to monitor them over time and understand the trends in order to identify what’s normal and what’s not normal.
Producer metrics
| JMX attribute (MBEAN name) | Description |
|---|---|
record-send-rate (kafka.producer:type=producer-metrics) |
The average number of messages sent per second. This is a good metric to monitor, especially if performance is critical for your use case. However, a single message can be any size so it does not tell you how many bytes in total are being sent per second. Instead, you can monitor the network on your host to get a full picture of how much data is being sent. |
record-error-rate (kafka.producer:type=producer-metrics) |
The rate of errors encountered when sending messages to brokers per second. If you have configured your producer to retry the send to ensure message delivery, a small rate of errors might not be a problem for you. However, if there is an increasing rate of errors, it could lead to a message loss. |
request-rate (kafka.producer:type=producer-metrics) |
The average number of requests sent to the brokers per second, which includes all type of requests that producers can send. Producers send requests not just for the messages but also for other operational data such as metadata. Again, you want to monitor the peaks and troughs over time to find the baseline to warn or alert against. |
response-rate (kafka.producer:type=producer-metrics) |
The average number of responses received from brokers. This metric also depends on the acknowledgement level; for example, if it’s configured to all, the broker waits for messages to be written to all replicas before sending a response back to the producer. If you see an unexpected drop in the rate, it could mean there is a bottleneck or connection issue between the broker and the producer. |
request-latency-avg (kafka.producer:type=producer-metrics) |
The average time taken between the producer sending a request to a broker and receiving a response back in milliseconds. Again, it can be any type of request that the producer can send but the latency for the message request can depend on some of the producer configurations such as linger.ms, batch.size, and ack. The producer waits for enough messages to accumulate so that it can send them as a batch in a single request. It waits until either the messages accumulated reaches the value specified in batch.size or it reached maximum wait time specified by linger.ms. These two configurations have significant impact on your producer throughput as well as the latency. Again, acceptable latency is dependent on the use case and baseline determined overtime. |
io-ratio and io-wait-ratio (kafka.producer:type=producer-metrics) (kafka.consumer:type:consumer-metrics) |
The fraction of time that the I/O thread spends doing I/O or waiting for the network. This metric is useful to monitor for both producer and consumer. If io-ratio is low or io-wait-ratio is high, this indicates a bottleneck somewhere in your application or the network. |
Consumer metrics
| JMX attribute (MBEAN name) | Description |
|---|---|
records-consumed-rate and bytes-consumed-rate (kafka.consumer:type=consumer-fetch-manager-metrics) |
The rate of consumed messages and bytes per second. If you see an unexpected drop in the rate, it can indicate an issue with consumers or with talking to the broker. Monitoring the consumed messages alongside the network throughput can be useful to watch the trends over time. |
records-lag and records-lag-max (kafka.consumer:type=consumer-fetch-manager-metrics) |
These metrics show how far your consumers are falling behind from the latest messages produced to the topic. First of all, you need to understand what is an acceptable lag for your application. If a consumer group keeps having lags, it might mean there is a process in your application that is taking too long or the consumer group needs be scaled to allow more throughput. |
records-lead-min (kafka.consumer:type=consumer-fetch-manager-metrics) |
This metric is the gap between the consumer offset and the lead offset of the log. Kafka removes the oldest messages when the specified retention period or size is reached. Therefore, if this value gets too close to zero, it's an indication that the consumer might not consume the messages in time before they get removed. |
rebalance-rate-per-hour and rebalance-latency-avg (kafka.consumer:type=consumer-coordinator-metrics) |
Consumer rebalancing used to be a "stop the world" operation, which meant that your consumer would not be able to consume during this operation. This is no longer the case after the Kafka 3.0 release. However, if consumer rebalancing is happening too frequently, you need to understand what could be triggering it and if the trigger aligns with your application behavior. For example, if your consumer intentionally disconnects and reconnects to the broker or if new partitions are added to your topic, then you would expect to see the rebalance events. If the rebalance events do not align with what your application is doing, then it is usually an indication of the consumer disconnecting from the broker unexpectedly. |
Application metrics
It’s also useful to instrument your application to emit metrics that can help you identify issues that might be causing your event flow to be slow, stuck, or not working. For example, you can monitor the following metrics:
- Where and how much time being spent in your application
- Number of active consumers in a consumer group
- Idle and blocking threads
- End-to-end latency
System metrics
It’s vital to monitor not just the metrics of your Kafka client but also the underlying infrastructure of your Kafka applications as the underlying infrastructure has a huge impact on your application performance. These metrics can help you identify any issues with resource utilization.
- Network traffic. Monitoring your producer and consumer network can help you identify if there is a bottleneck, unexpected latency, or throughput throttling due to insufficient bandwidth. Also, if you see an unexpected drop in traffic, it can be an indication of a failing producer or consumer.
- CPU and memory. For any application, it is vital to monitor the CPU usage and memory because it can lead to unexpected behavior or failure if a system is running at the edge of its limits.
- Disk capacity and latency. Full disks will prevent data from flowing, and latency will cause delays, so it's important to create a warning if applications are running close to the resource limit and take actions early.
Summary
Monitoring Kafka metrics can get you ahead of problem before they happen. Two key best practices for monitoring Kafka apps are:
- Start with a small set of key metrics.
- Alert on carefully selected and well understood metrics.
In addition to monitoring your Kafka app with the Kafka metrics I described in this article, you also need to monitor the system metrics, which also affect the performance of your application.