Tutorial
Fun with OperatorHub
Working with OpenShift operators to deploy a database on Red Hat OpenShift on IBM CloudArchive date: 2025-11-02
This content is no longer being updated or maintained. The content is provided “as is.” Given the rapid evolution of technology, some content, steps, or illustrations may have changed.Operators provide a mechanism to run more complex workloads in your OpenShift Kubernetes cluster. In this tutorial, you learn to set up an instance of the popular PostgreSQL database through a community database operator that manages instances of databases inside the cluster.
Operators introduce a new native object into Kubernetes. One way to think about the operator is as a factory to instantiate pods for in-cluster services. You can write operators to upgrade and back up your application and to recover from some kinds of errors. In addition, depending on their sophistication and capability, they can stand in for an operations team with built-in knowledge of specific business logic.
OpenShift comes with many resources, such as nodes, deployments, and pods that you can manipulat in the UI and through oc or kubectl command-line interfaces. Operators can create new custom objects to Kubernetes with their own function-specific logic. Operators use a controller which reconciles state in a resource specific way. OpenShift 4 introduced the OperatorHub, a catalog of applications that can be installed by the administrator and added to individual projects by developers. While templates allow you to deploy applications, they generally don't install custom resources to Kubernetes, and more importantly, are run once and aren't able to respond to changes in the environment to manage the service.
This tutorial walks through the process of deploying a community operator into an existing OpenShift project so you can create instances of the PostgreSQL database.
The examples in this tutorial use Red Hat® OpenShift® on IBM Cloud™.
Prerequisites
This tutorial is for software developers familiar with Kubernetes or OpenShift who want to learn about operators and OperatorHub in OpenShift 4.
Before you begin this tutorial, complete the following steps:
- Log in, or create an account on IBM Cloud
- Provision an OpenShift 4.3 cluster on on IBM Cloud
- Create a project
Estimated time
This tutorial takes about 30 minutes, not including the time to provision an OpenShift cluster.
Understand OperatorHub and OLM
The operators listed in OperatorHub, both official Red Hat and "community" operators (not officially supported), are managed by the Operator Lifecycle Management (OLM) service, itself a Kubernetes operator. Visit the Red Hat Marketplace to access operators that are certified to run on Red Hat OpenShift.
OLM provides the subscription object to list installed operators. This allows you to interrogate installed objects.
After the operator is installed by following the steps in this tutorial, you can use the oc get sub command to list the operators installed through the operator catalog:
$ oc get subs
NAME PACKAGE SOURCE CHANNEL
postgresql-operator-dev4devs-com postgresql-operator-dev4devs-com community-operators alpha
Step 1. Find the community operator
Begin by switching to the administrator mode in OpenShift and browse to the OperatorHub. In the navigation, expand Operators and select OperatorHub:
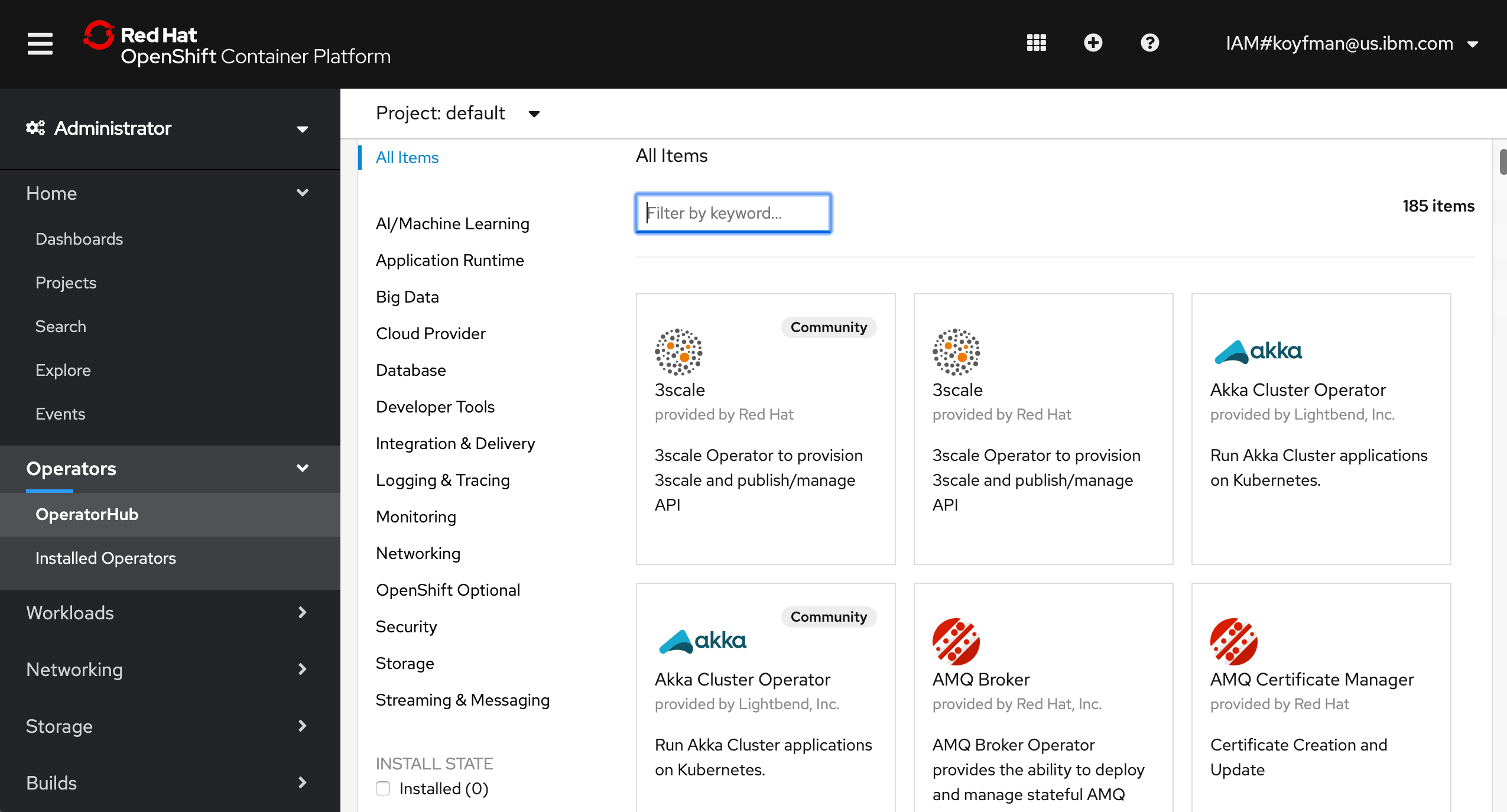
Then search for PostgreSQL in the OperatorHub and click the Install button to install the Dev4Devs community PostgreSQL operator:
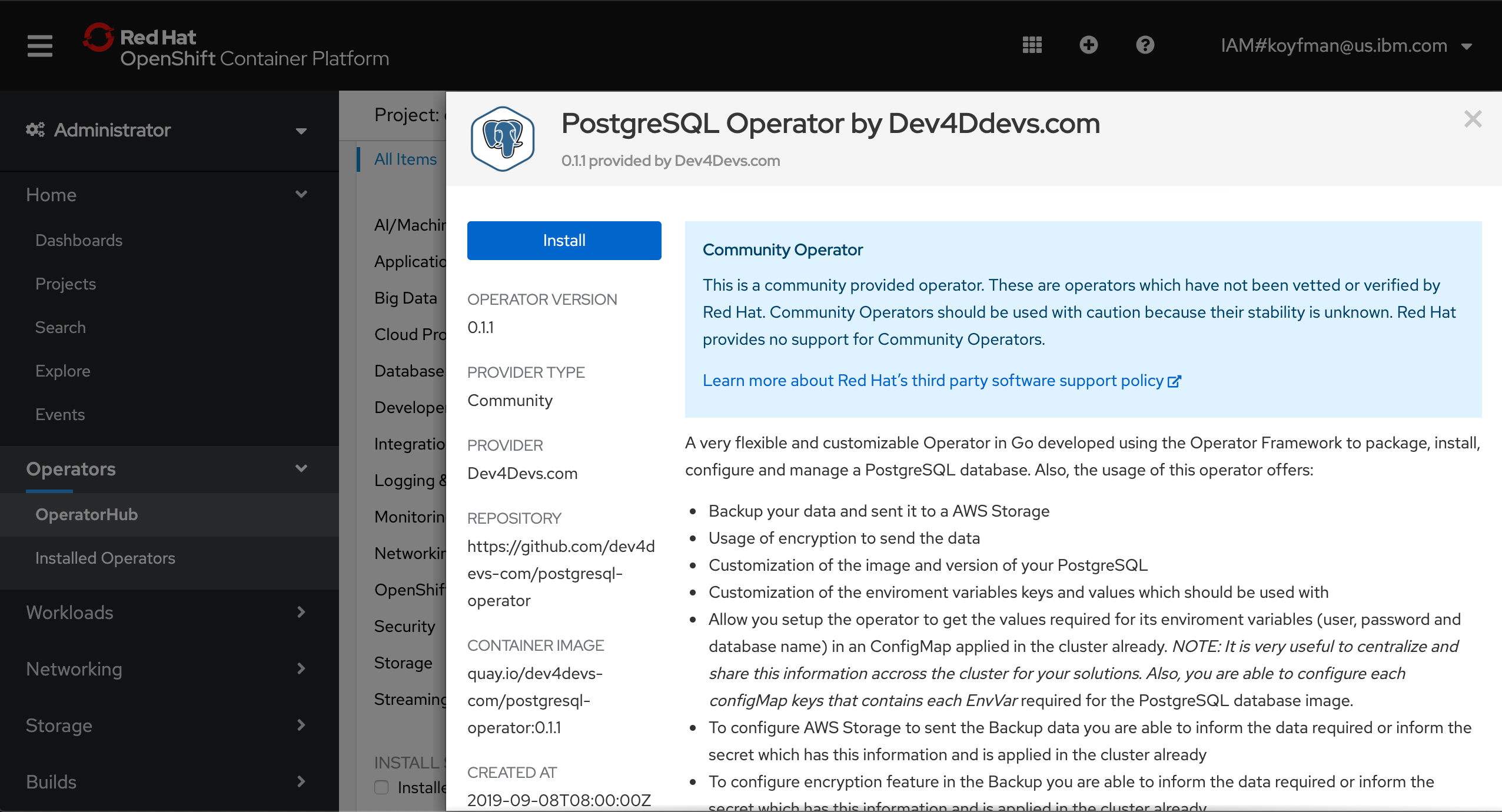
Step 2. Subscribe to an operator
Now you need to select one your existing namespaces where you want to install the operator. This is the namespace where you can create instances of the database:
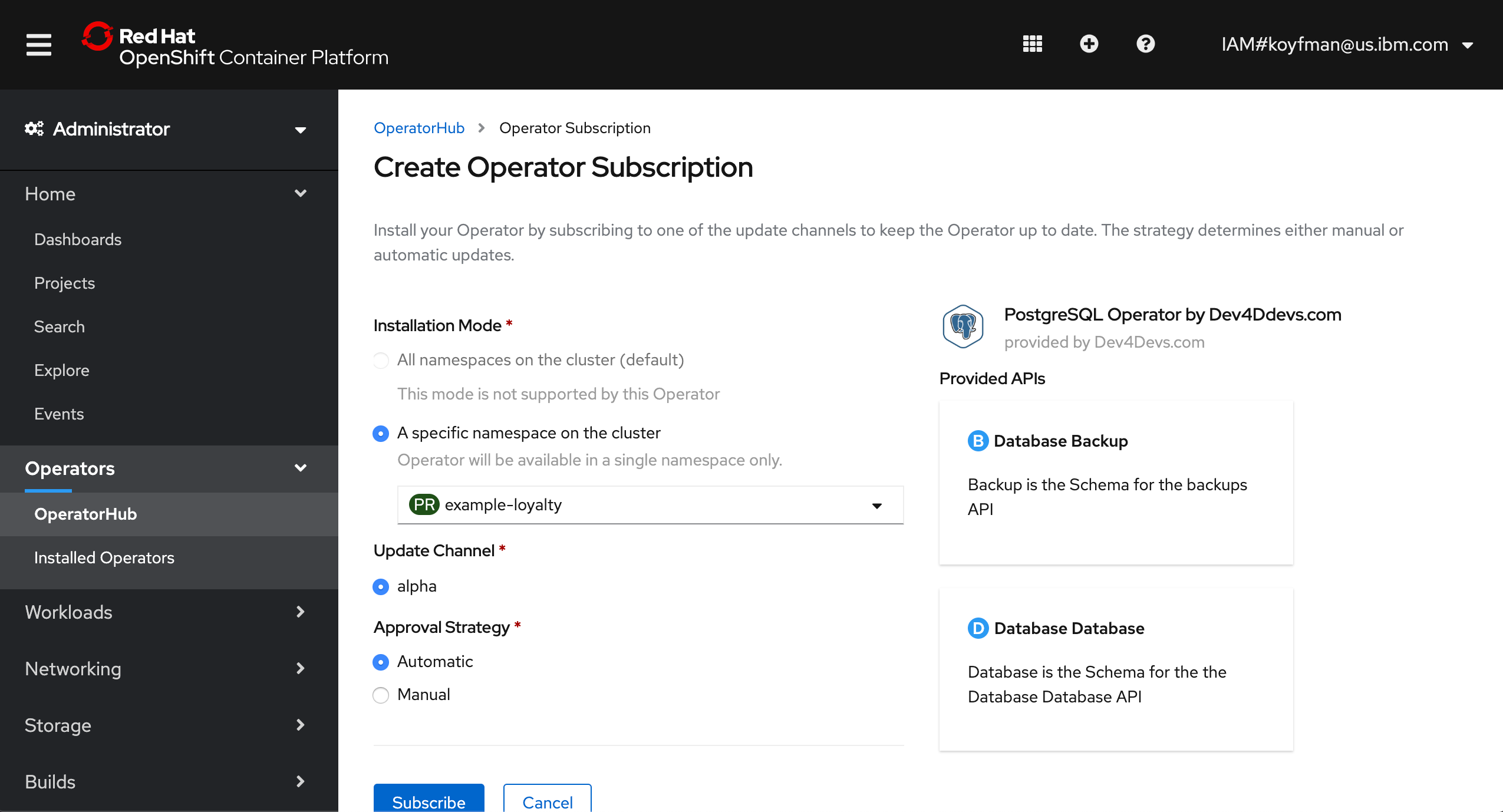
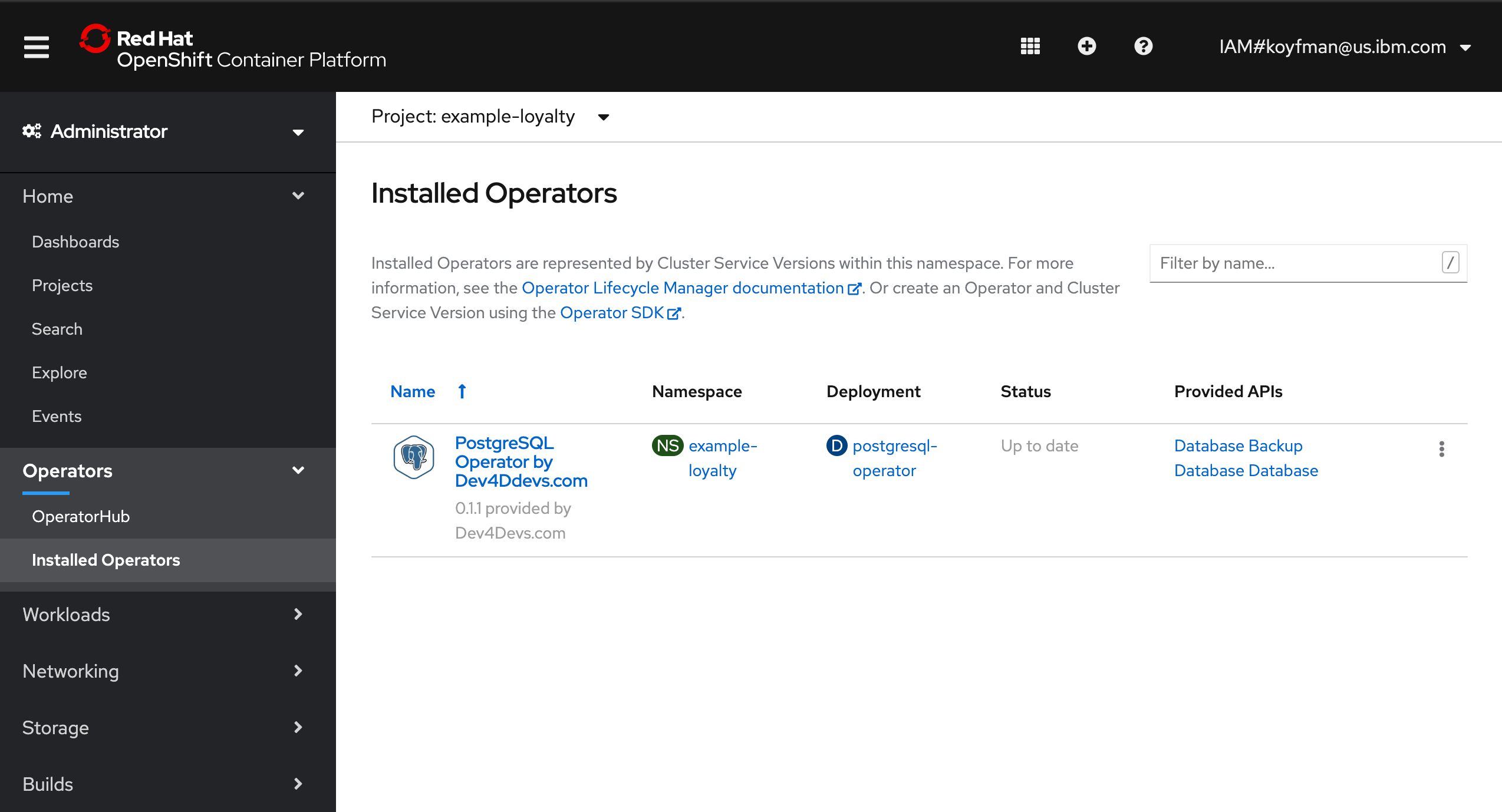
After you have installed an operator by subscribing to one of the channels to keep it up-to-date, you can view installed operators. In the navigation, under Operators select Installed Operators. Now you see the PostgreSQL operator:
Step 3. Switch to the Developer view and create the database
Change your view from Administrator to Developer and select Topology to view your deployed operator.
Click on +Add link in the left hand panel and then select the Database tile, as shown in the following screen capture:
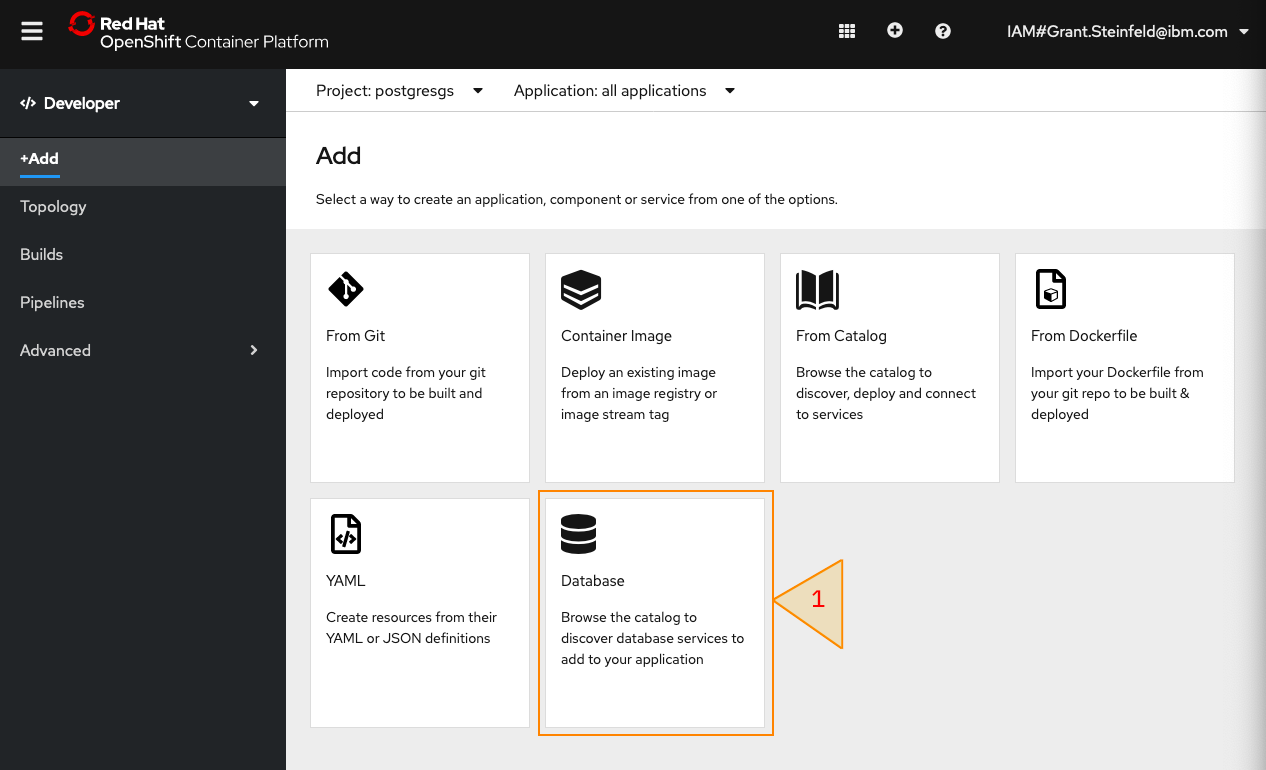
Next, in the developer catalog, select the Postgres Database Database tile for your operator:
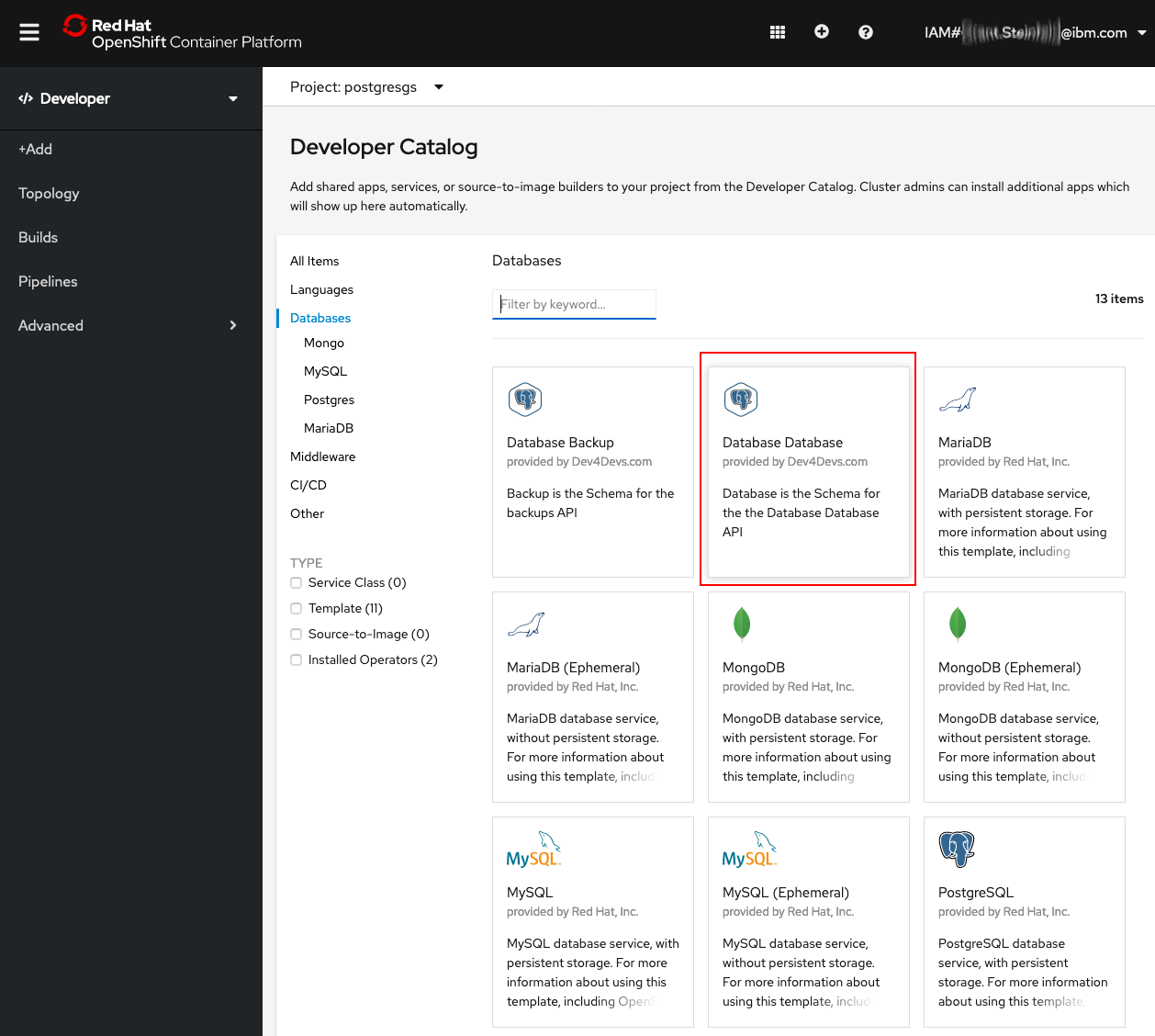
Here you can select the size of the volume assigned to the database, as well as resource limits for the database.
You can also specify the database name and namespace: for example, call the name creditdb and call the namespace
example-bank, as shown in the following screen capture:
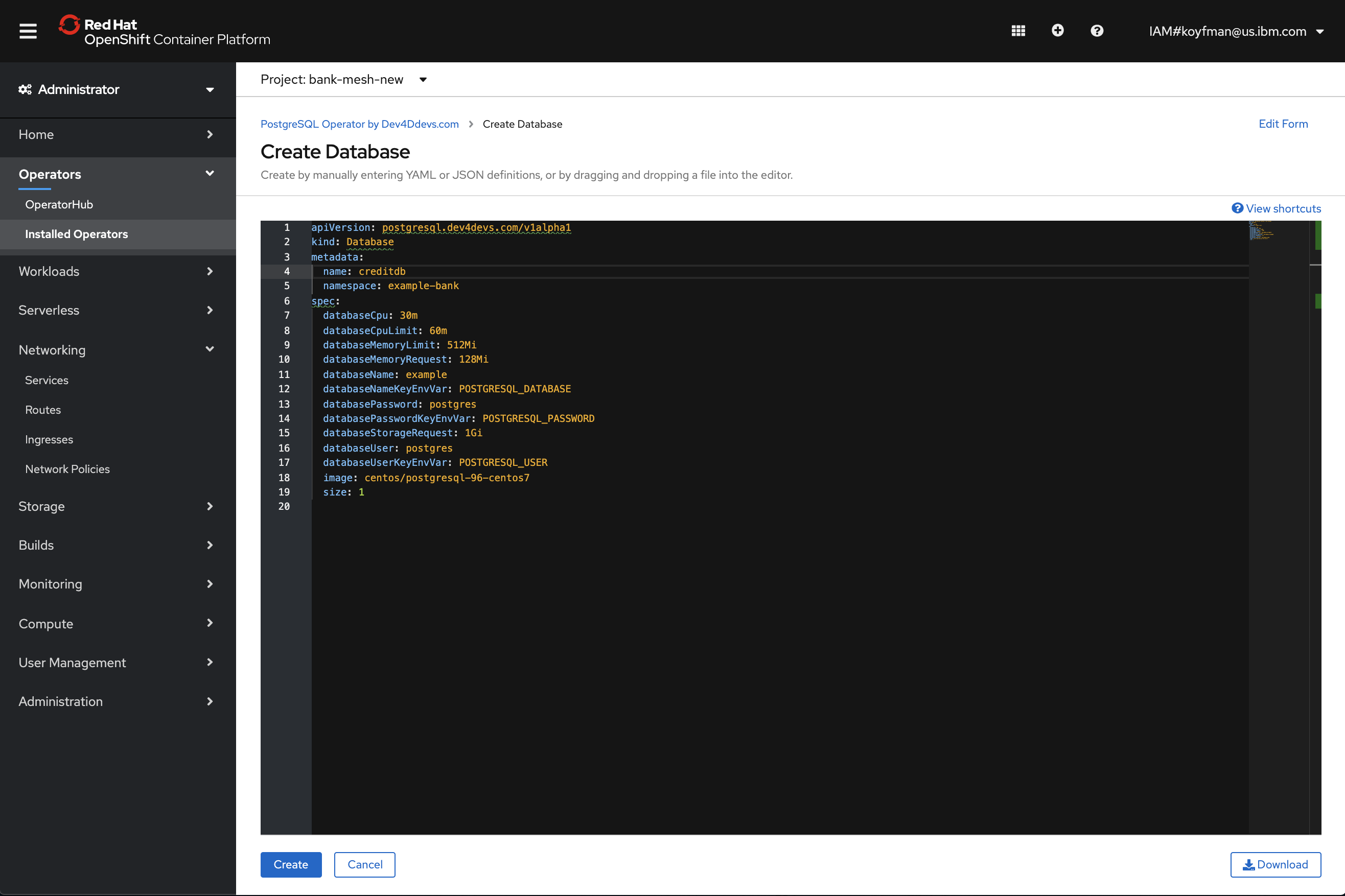
Here is the new database that was created through the operator:
$ oc get pods
NAME READY STATUS RESTARTS AGE
creditdb-8565d6bfd9-dm88t 1/1 Running 1 6d4h
postgresql-operator-576dc87c4-vtr6j 1/1 Running 0 6d21h
The databases CRD is now a Kubernetes native object that you can query through oc or, equivelantly, kubectl, as shown in the following example:
$ oc get databases
NAME AGE
creditdb 6d6h
$ kubectl get databases
NAME AGE
creditdb 6d6h
Not only does the operator instantiate the database instance -- it also creates a PersistentVolumeClaim for database storage.
Step 4. Connect to the database
Expose the service with oc expose to allow access from outside the cluster through an external IP. Note that OpenShift routes only support HTTP/HTTPS traffic, so you can't use them to connect to the PostgreSQL instance:
$ oc expose deploy creditdb --port=5432 --target-port=5432 --type=LoadBalancer --name my-pg-svc
service/my-pg-svc exposed
$ oc get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-pg-svc LoadBalancer 172.21.48.131 169.aaa.bbb.ccc 5432:32469/TCP 12s
Now you can access the database from outside the cluster using the external IP previously described.
After the database is in production, you can delete the LoadBalancer. Deleting the LoadBalancer eliminates external access to the database and only allows services to connect to the database through an internal cluster IP or service.
Summary
The OpenShift OperatorHub provides an "app store" kind of experience for finding and installing services into your OpenShift cluster. The OLM service and its command-line interface help you manage and keep your operators updated.
You can go to OperatorHub in your OpenShift 4.3 cluster to discover other services available to install in your cluster, or see operatorhub.io for a larger list of operators that you can install manually.
Next steps
Use the open source code and instructions in the following content to understand the steps we followed to build the secure Example Bank cloud application with OpenShift 4.3: