Tutorial
Predict future product demand using SPSS Modeler
Create a predictive machine learning model to help you determine your optimal inventory levelArchive date: 2025-05-21
This content is no longer being updated or maintained. The content is provided “as is.” Given the rapid evolution of technology, some content, steps, or illustrations may have changed.As mentioned in the Develop an intelligent inventory and procurement strategy using AI article, the goal of this use case is to build an intelligent inventory and distribution strategy using artificial intelligence (AI). In this part of the solution, you'll work on predicting future demand of products to help you determine your optimal inventory level using IBM® SPSS Modeler for IBM Watson® Studio on IBM Cloud®. SPSS Modeler is a data mining and analytics software that is used to build predictive models. Using SPSS Modeler for Watson Studio enables data scientists and data analysts to work in a collaborative, cloud-based environment and quickly share their models and results with their stakeholders.
Learning objectives
After completing this tutorial, you'll understand:
- How to upload data to Watson Studio
- How to create an SPSS Modeler flow
- How to use the SPSS tool to profile and analyze data
- How to modify, filter, and prepare data for AI model creation
- How to train a machine learning model with SPSS and evaluate the results
Prerequisites
The following prerequisites are required to follow the tutorial:
Estimated time
It should take you approximately 30 minutes to complete this tutorial.
Steps
Create Watson Studio service on IBM Cloud
The first step in this tutorial is to set up your IBM Cloud Watson Studio service instance. To set up your free Watson Studio instance:
Log in to IBM Cloud, and click Proceed to show that you have read your data rights.
Click IBM Cloud in the upper-left corner to ensure that you are on the home page.
Within your IBM Cloud account, click the search bar to search for IBM Cloud services and offerings. Enter
Watson Studio, and then click Watson Studio under Catalog Results.This takes you to the Watson Studio service page. Here, you can name the service. For example, you can name it Watson-Studio-trial. You can also choose which data center to create your instance in. The demo shows the one for this use case as being created in Dallas.
Choose the Lite service, which is free. This has limited compute but it is enough to understand the main functions of the service.
After you're satisfied with your service name, location, and plan, click Create. This creates your Watson Studio instance.
Create a project in Watson Studio and upload the data
To launch your Watson Studio service, click IBM Cloud in the upper-left to return to the home page. Under Resource summary, click on Services. You should see your services as well as your service name. This might take a a few minutes to update.
Click your service name, and you are taken to your Watson Studio instance page. Click Get Started. This opens the Watson Studio (that is, IBM Cloud Pak for Data as a Service) tooling. Click Projects.

Click Create a Project or New project, then click Create an empty project.
Name your project, for example, SPSS Modeler demo.
Associate an IBM Cloud Object Storage instance so that you can store the data set. Under Select Storage service, click Add. This takes you to the IBM Cloud Object Storage service page.
Leave the service as the Lite tier, then click Create. You are prompted to name the service and choose the resource group.
Select a name, then click Confirm for the resource group.
Refresh the project page. You should see your newly created IBM Cloud Object Store instance under Storage.
Click Create, and you've created your first Watson Studio project.
Run the following command to clone the project repo. You'll need to use files from this repo in subsequent steps.
git clone https://github.com/IBM/optimize-procurement-and-inventory-with-aiAfter you have created your Watson Studio Project, click Add to project.
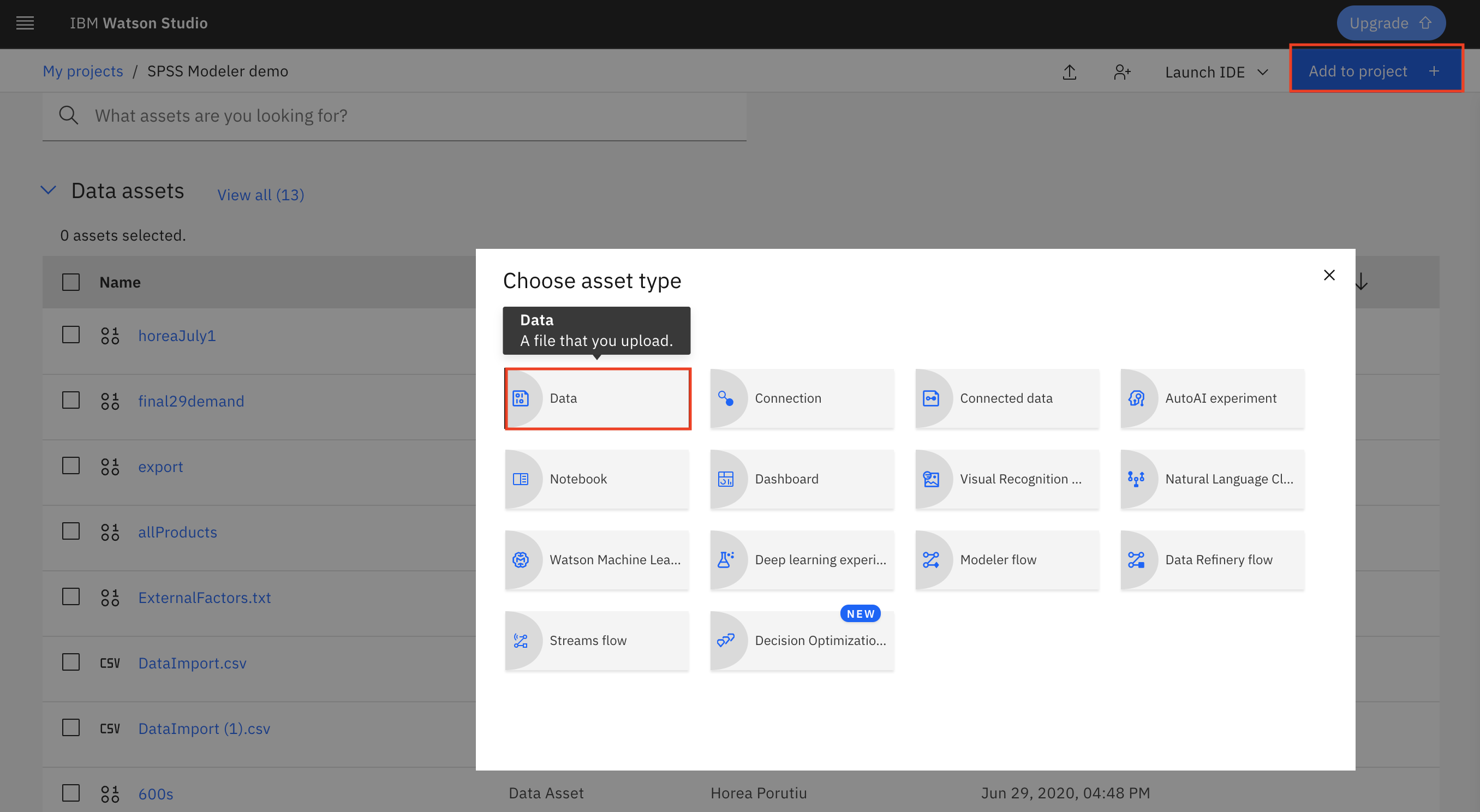
Select Data.
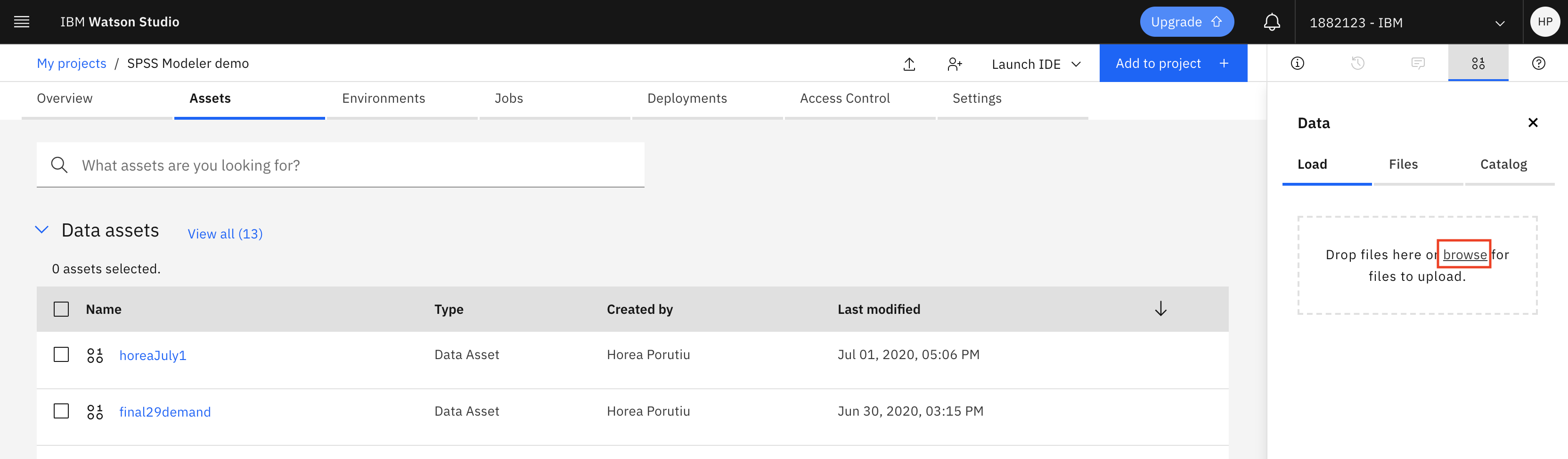
Click browse, navigate to where you cloned the repository, and select TM1 Import.csv from the optimize-procurement-and-inventory-with-ai/tutorials/spss-tutorial/data directory.
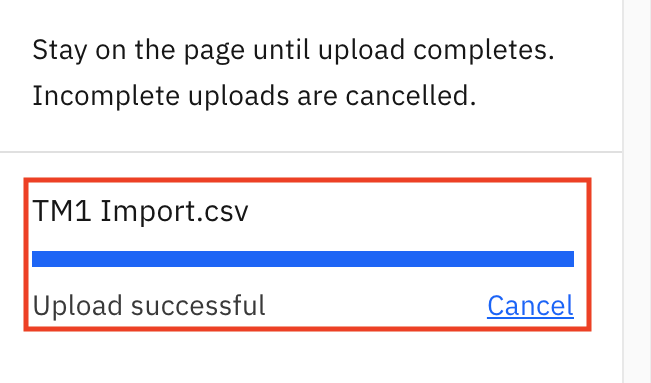
After the upload completes, you should see Upload successful, as shown in the following image.
Add a Modeler Flow to your Watson Studio Project
Click your newly created project.
Click Add to project on the upper-right.

Select Modeler flow.
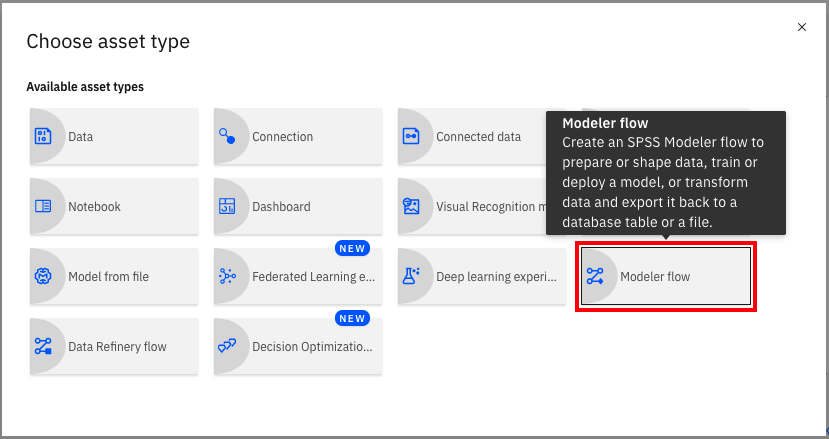
Select From File, browse to where you cloned this repository, and open the Demand Forecast.str file from the optimize-procurement-and-inventory-with-ai/tutorials/spss-tutorial directory, then click Create.
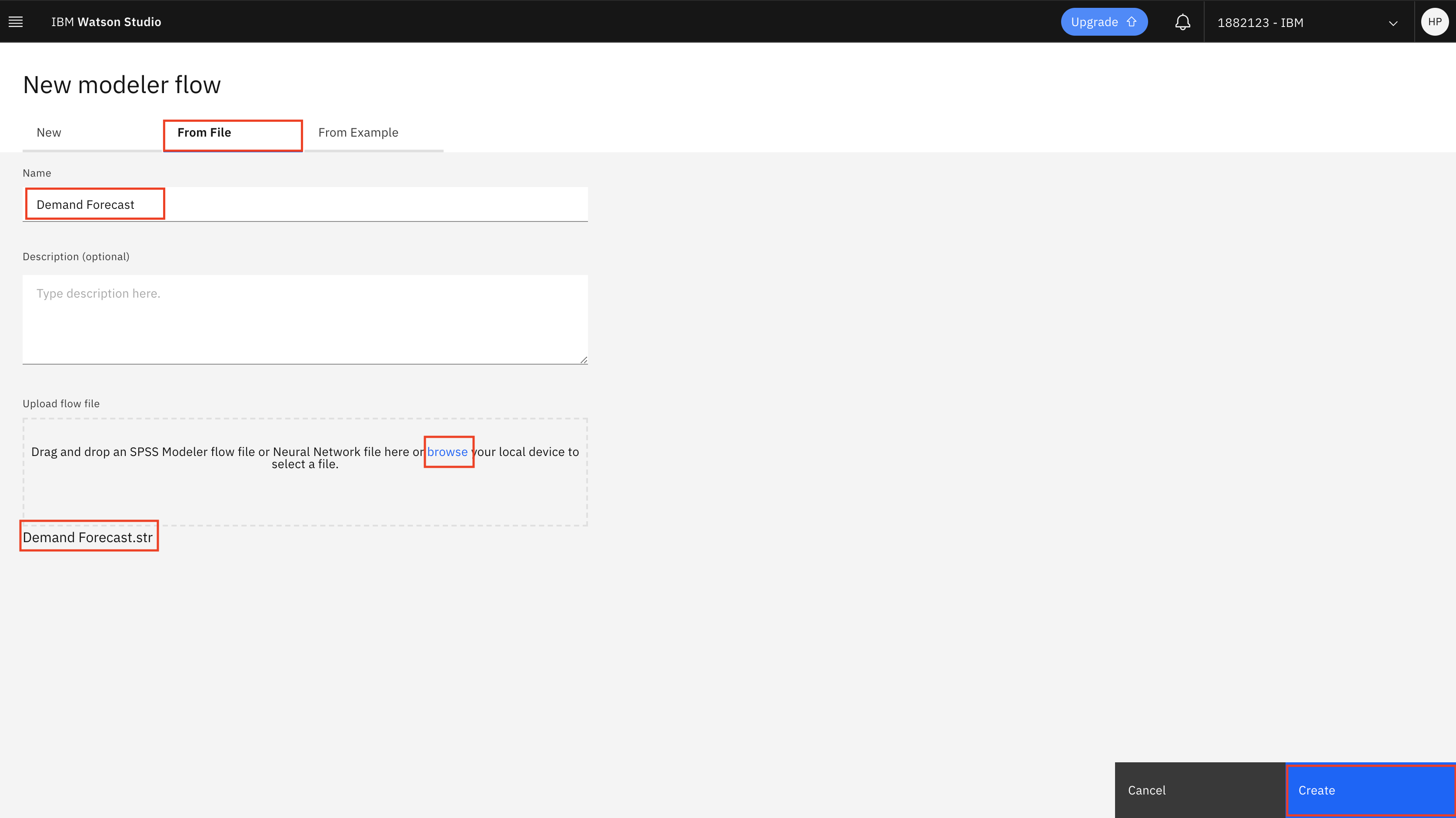
Import the data
You should see your flow, as shown in the following figure.

On the left side of the flow, under Data Import, hover over the
TM1 Importnode. You should see a three-dot icon appear. Click it.
Click Open.
This opens the right-hand side panel with the TM1 Import node details. Click Change data asset.

From the left side, click Data assets, then click TM1 Import.csv. Click Select.

Click Save on the right-hand side panel.
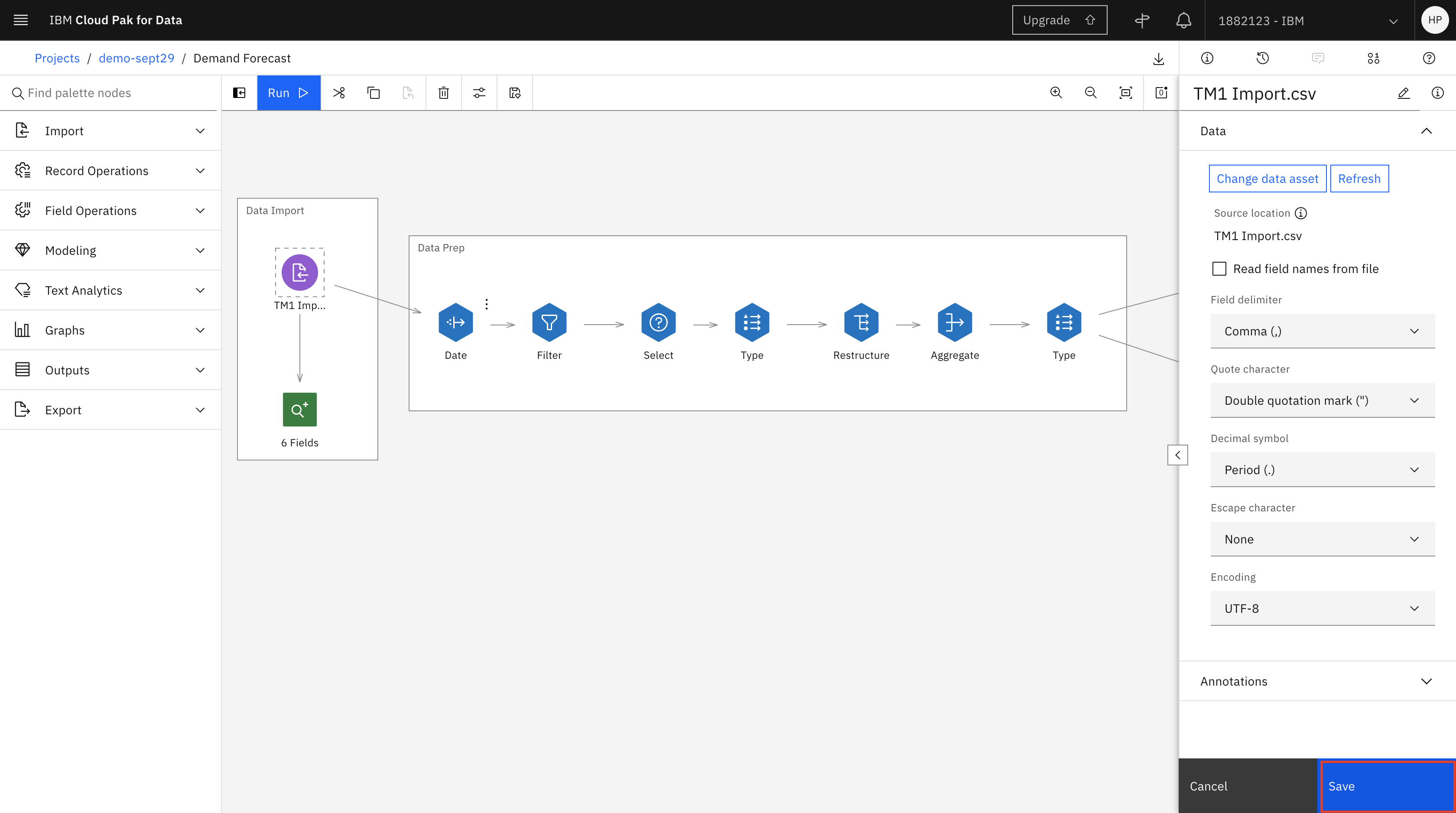
After the flow is updated, you are ready to explore the data.
Explore the data
Before you do any analysis and predictions on the data, it's a good idea to explore the data set.
From the Data Import section, hover over the green 6 Fields node, and click the three-dot symbol to the right of the node. Then, click Run.
After the node runs, click the clock icon. In the Outputs section, there should be a Data Audit of [6 fields] section. Click the eye icon to open it.
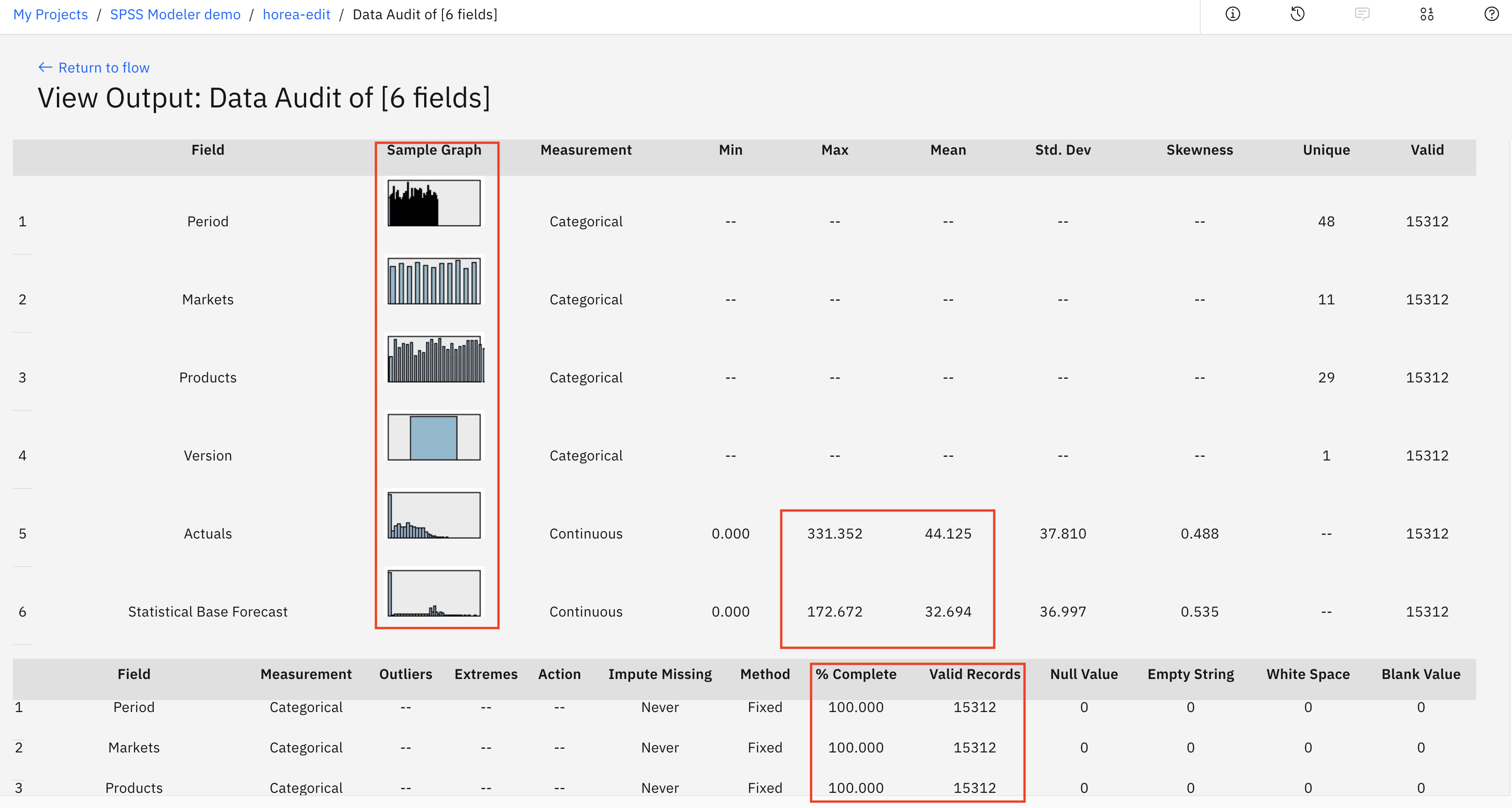
Here, you can get a visual representation of your data set and see some sample graphs of your columns. You can see some statistical measures such as max, mean, standard deviation, and how many fields are valid. You see that the max for our Actuals field (which is the demand for our product) is 331, but the mean is much lower, at 44. Finally, you can see how many valid records there are for each column.
After you finish exploring the data set, you can return to the flow by clicking the X icon in the upper-right corner.
Data preparation
Next, we focus on the data prep nodes. These are the nodes that modify the data set to predict just the values you want. A great way to understand what each node is doing is to Preview the node. To preview a node, such as the TM1 Import node:
Hover over the node, and click the three-dot symbol.

Click Preview.
This is a quick and easy way to see what the data looks like at the current node in the flow. The following image shows what you should see after you've previewed the node.
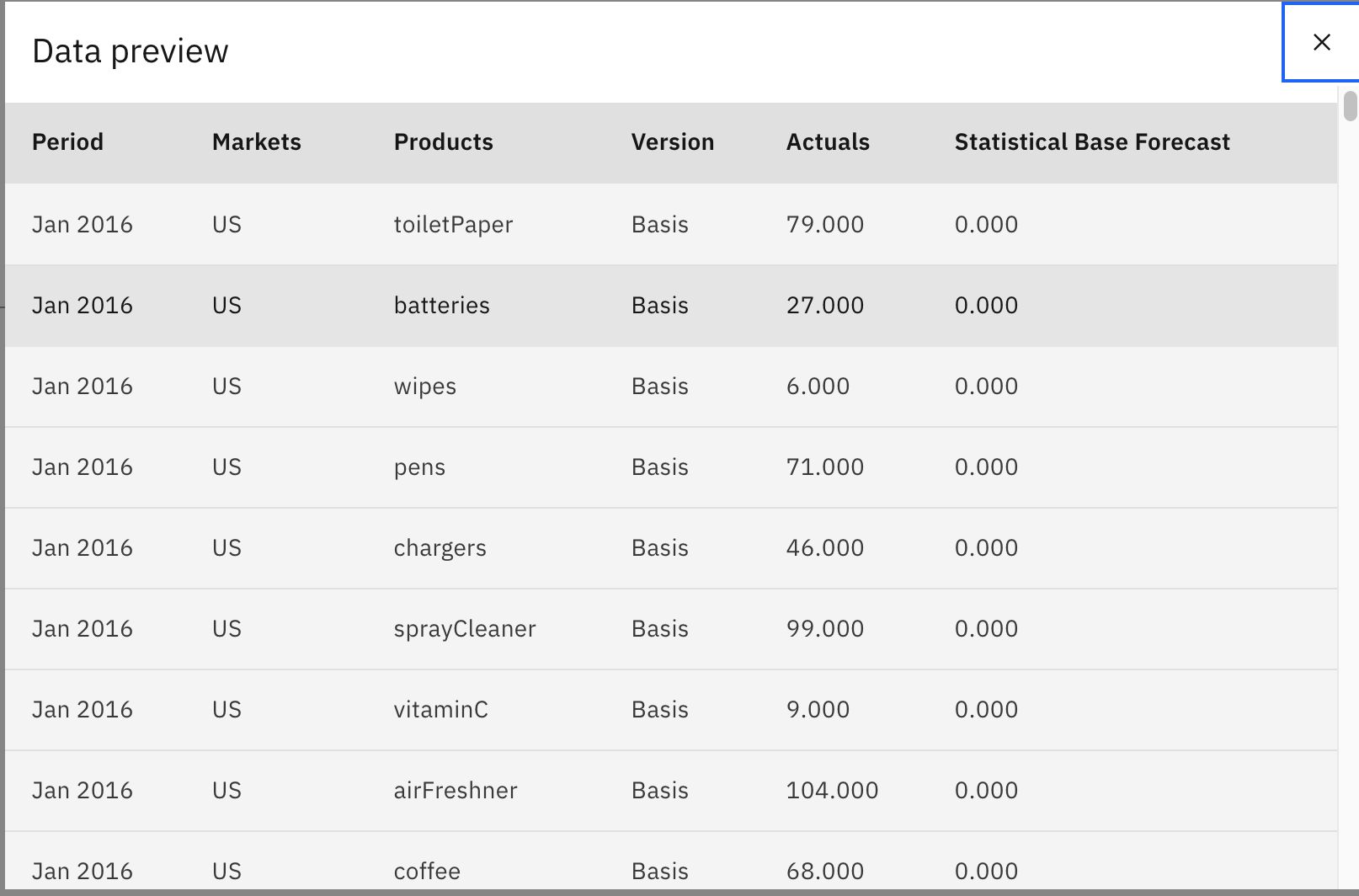
Hover over the Date node, click the three-dot symbol, then click Preview.
After you preview the node, you should see that the Date node adds another column to the data set, Date, and derives that value from the Period column.
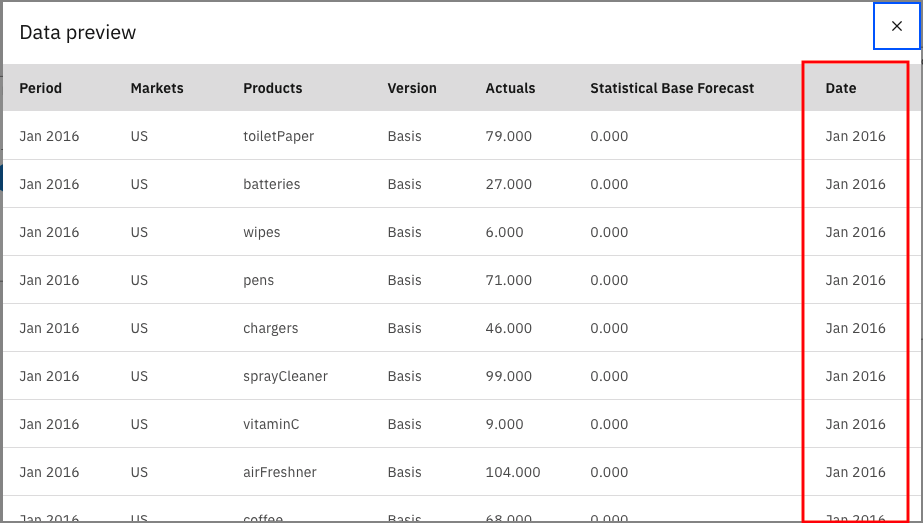
The Filter node removes the Statistical Base Forecast column and leaves the other columns as is.
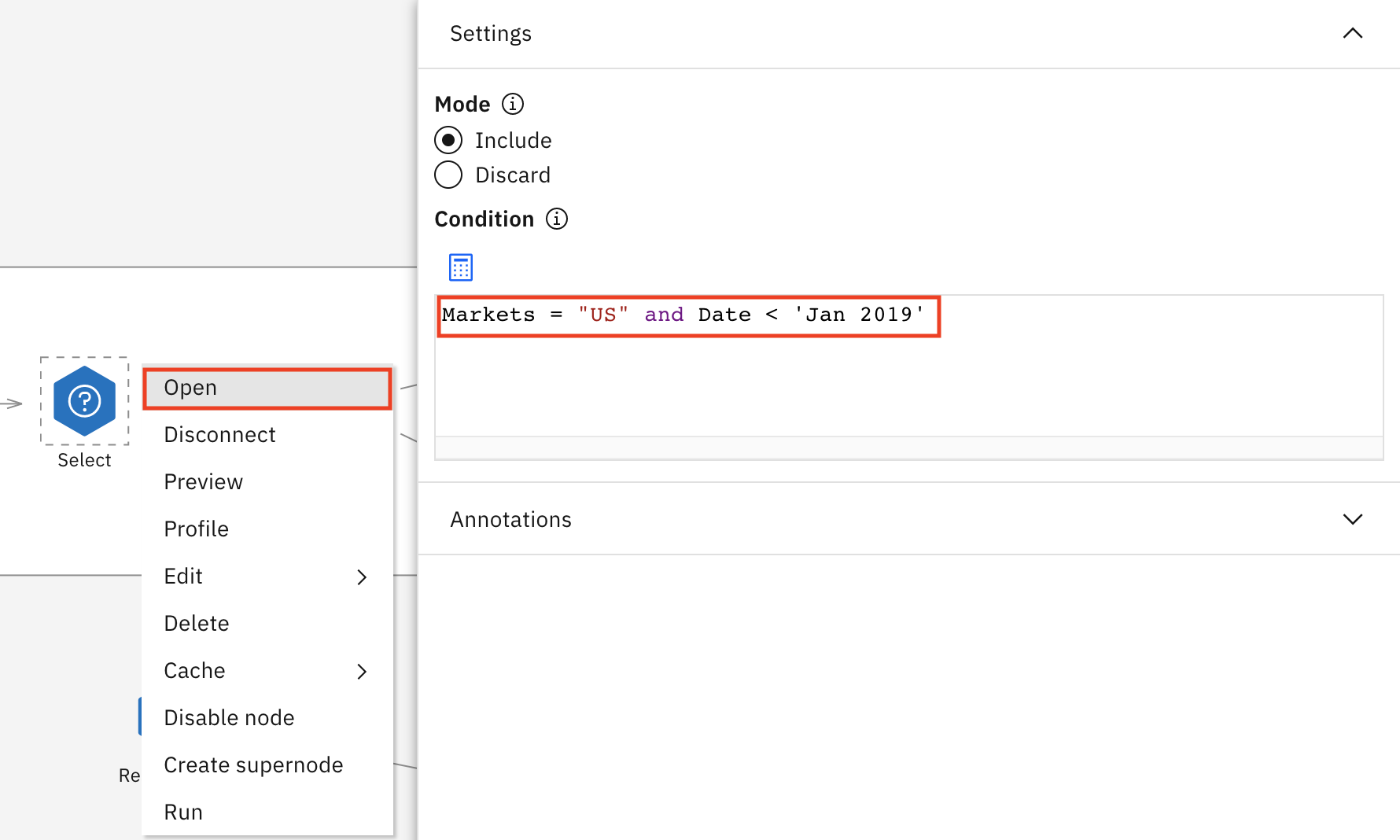
The Select node is very important. It's going to take a subset of the data, and it uses an expression to do this. You can see in the expression that I have only taken the US markets and the Date when it is before Jan 2019. This enables me to make more specific predictions, but only for the US market because that is where the retail store manager that we want to focus on is located. If you preview this node, you see that the Markets column does not feature any value other than US.
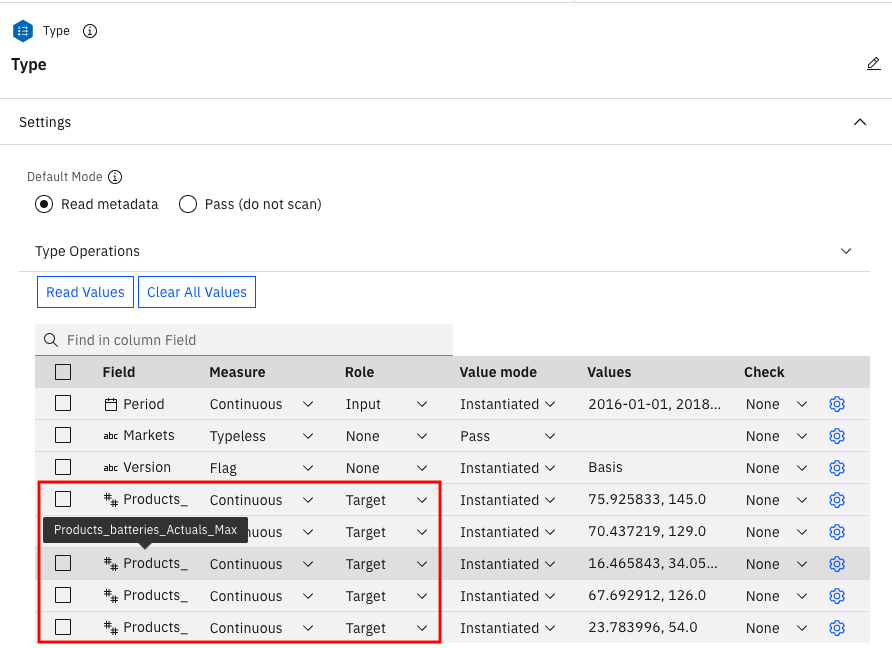
The last of the data prep nodes is the Type node. This lets you make specific operations on the fields within the data set. In this node, you split the Products column into individual values so that you can later predict demand for each of the products within that column.
Next, the restructure node creates new columns for the data set. It takes the values from the Products column and adds the Actuals demand value for that product in a separate column so that demand for a specific product is easily distinguishable.
If you hover over the Restructure node, click the three-dot symbol, and then click Preview, you can see the new columns that are added to the data set.
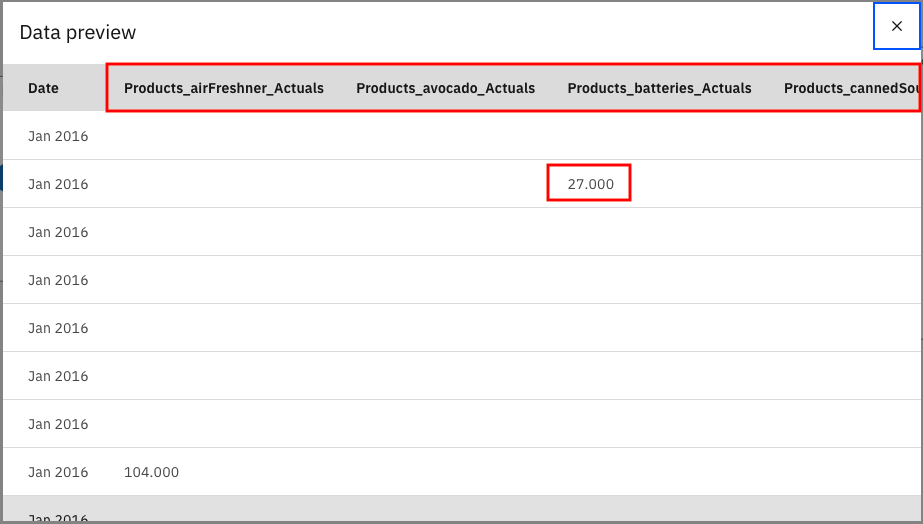
You can also Open the node, which shows you how multiple fields were generated from merging the Products and Actuals columns.
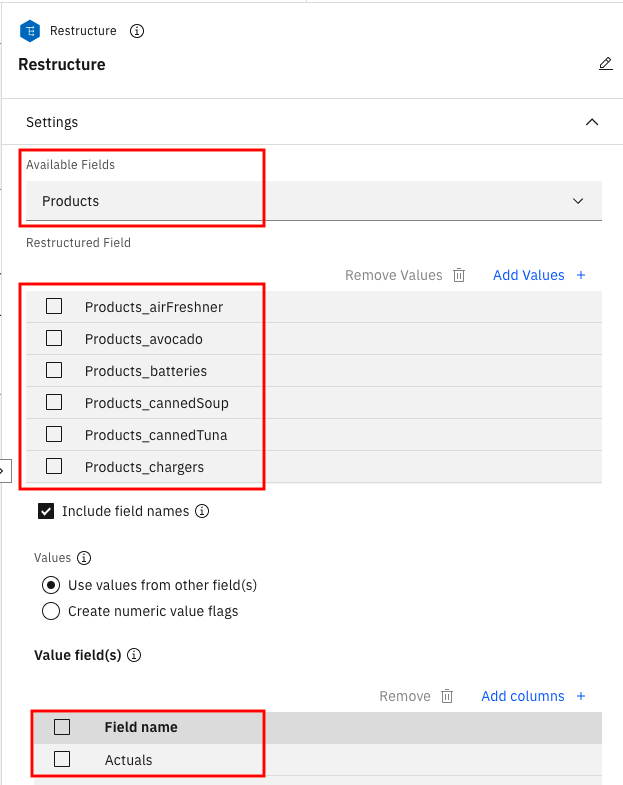
To see how we are taking the largest value from the fields such as Products_mask_Actuals that we created previously, hover over the Aggregate node, click the three-dot-symbol, and then click Open. This is to ensure that we have enough product in inventory to satisfy the maximum demand.
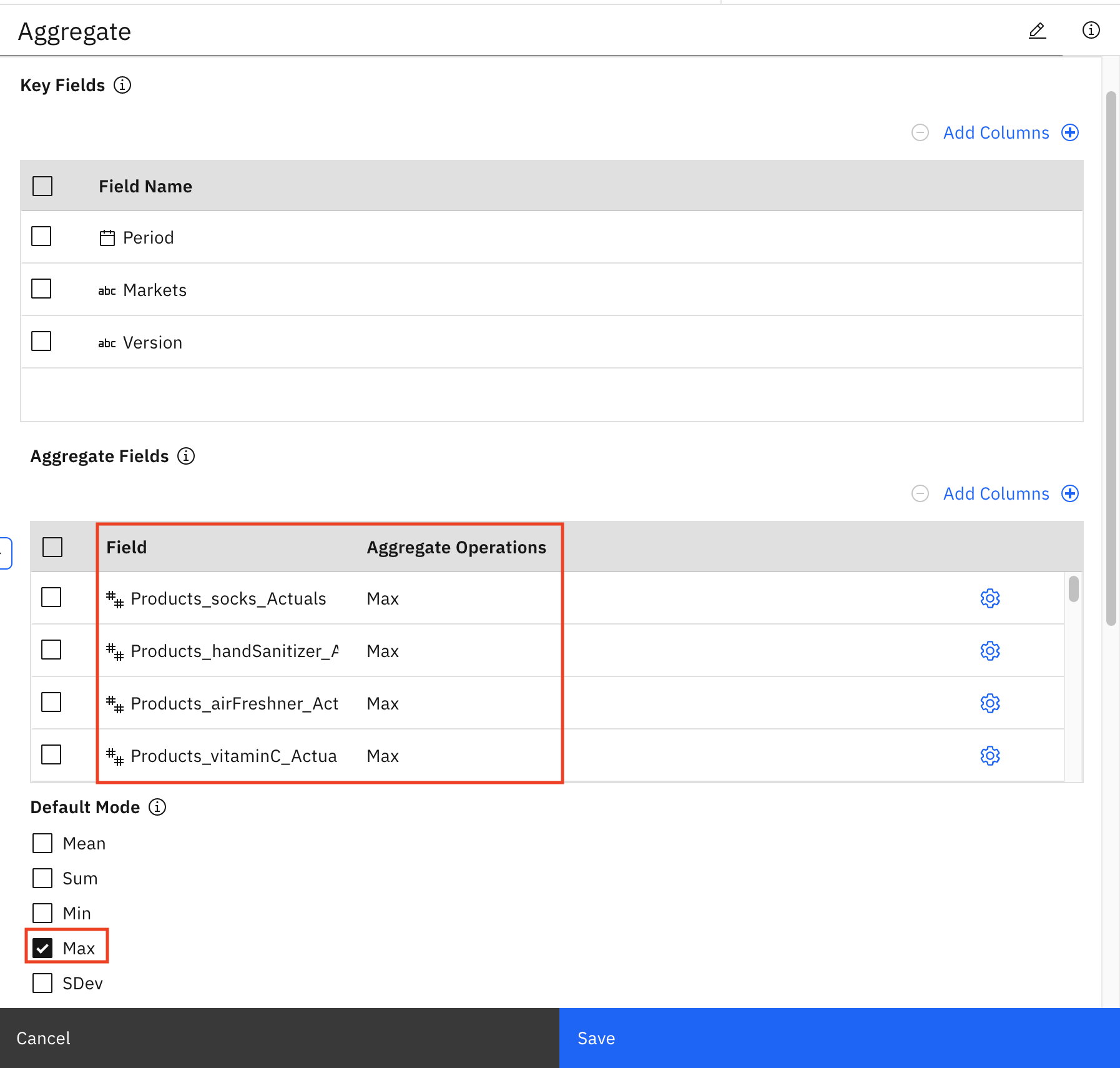
Similarly, hover over the Aggregate node, click the three-dot symbol, and then click Preview to see the new columns with the _Max suffix added to them.
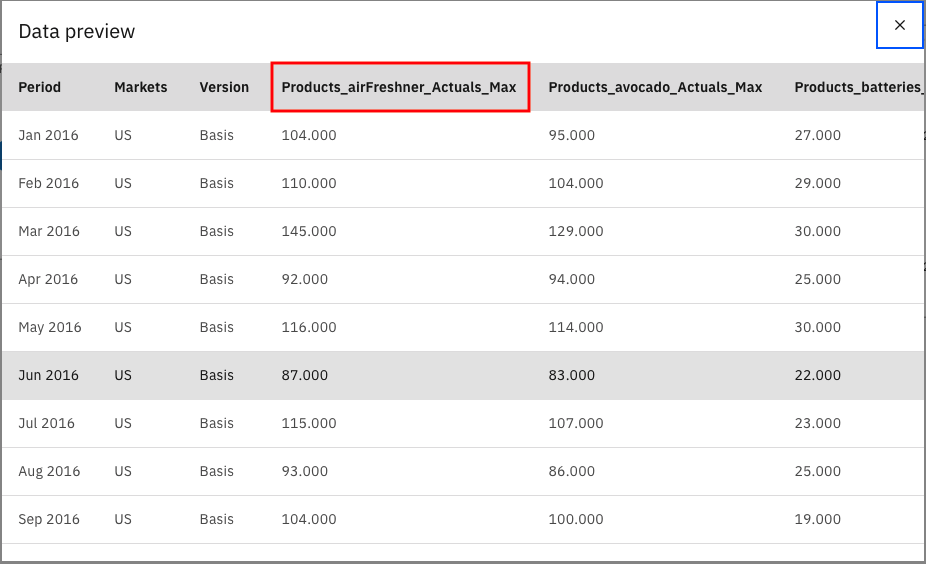
Hover over the Type, and then click Open. You see that we've designated the new fields that we created in the previous steps as the target variables because we want to predict the max demand for each of the products within the Products column within the US market.
Train the machine learning model
Hover over the 29 fields icon, then click Run. This runs the time-forecasting model with the data that we prepared in the previous steps.
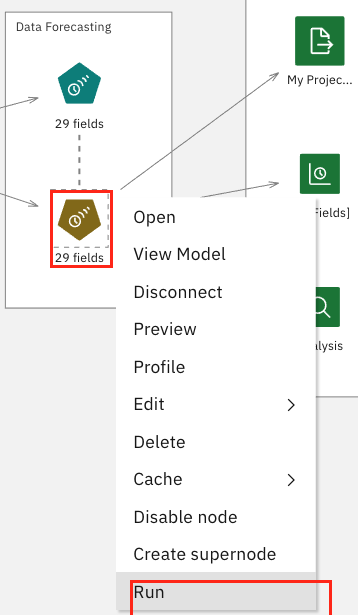
After the model finishes running, you see that the Outputs tab has been updated.
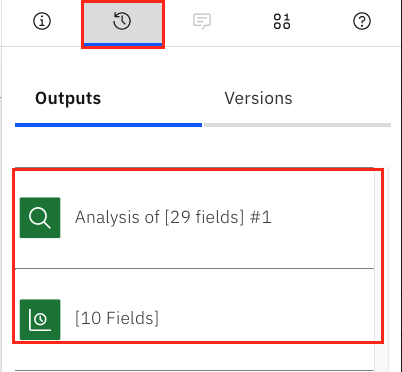
Evaluate the results
Click the eye icon next to Analysis of [29 fields] in the Outputs tab. Here, you can see an assessment of the mean error, maximum error, and other values that compare the $TS-Products_Actuals_Max. That is, the maximum demand forecasted by the model for a particular product versus Products_Actuals_Max, which is the max that has been recorded for the training period (2016-2018).

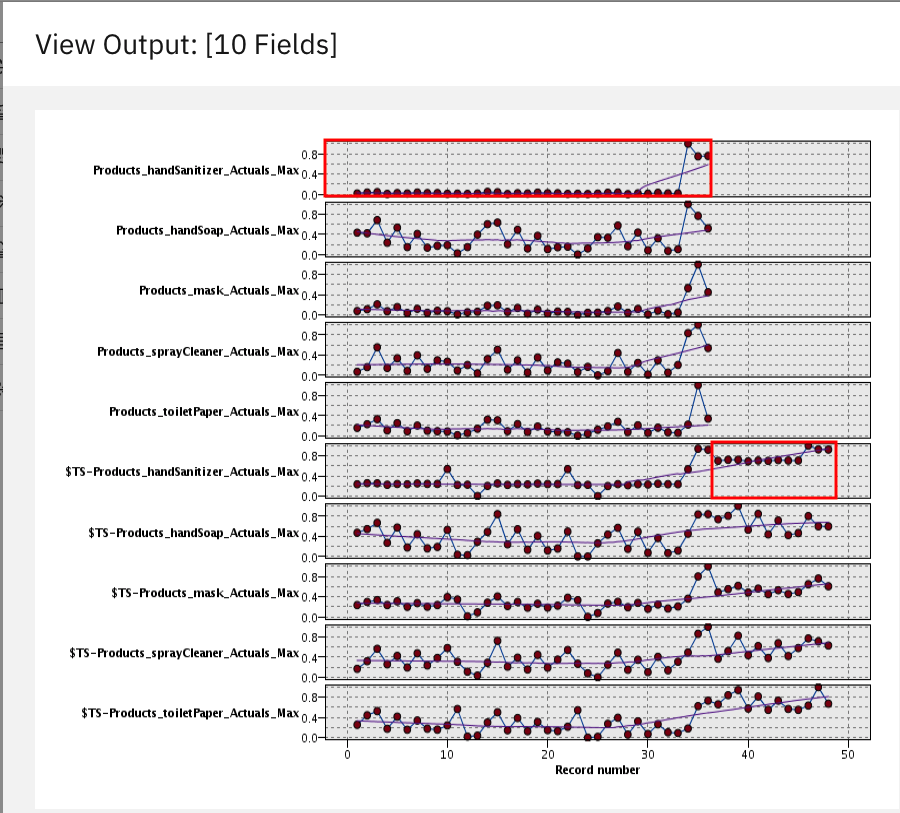
Click the eye icon next to [10 fields] in the Outputs tab. Here, you see a visual representation of a few of the interesting products that have shown to have spiked in demand over the past three months of training data. In October, November, and December of 2018, these particular products -- masks, hand sanitizer, and spray cleaner -- all spiked in demand, much higher than previously recorded, such that the forecasted values for 2019, the year we are predicting, are all much higher due to these three months of training data. You can see this by comparing the forecasted $TS-Products_Actuals_Max charts versus the Products_Actuals_Max charts.
Summary
This tutorial demonstrates a small example of creating a predictive machine learning model on IBM SPSS Modeler on Watson Studio. The tutorial covers importing the data into the project and the modeler flow and preparing the data for modeling. The tutorial then goes over running a time series algorithm for the data and training a prediction model. The last step of the tutorial is how to visualize and evaluate the results of the trained model.