Learning Path
Develop production-ready, Apache Kafka apps
High availability (HR) and disaster recovery (DR) are complex topics and are specific to your business and its needs and values. In this article, I will be looking at these topics when building your system:
- The 'availability spectrum'
- Managing risk - Expectations and considerations for availability
- What IBM Event Streams on Cloud provides and how to enhance your Event Streams disaster recovery capabilities
IBM Event Streams (https://www.ibm.com/cloud/event-streams) is a managed Kafka service available in IBM Cloud. It provides a secure, and resilient event streaming service that is ready for your business critical workloads.
This article describes ways in which you can ensure that the availability of applications built on IBM Event Streams on Cloud grows in-line with your businesses reliance on these applications. (While similar techniques can be applied to Apache Kafka instances in general, the rest of this article describes the specific implementation for IBM Event Streams on Cloud.)
The 'availability spectrum'
You will no doubt have come across the terms high availability (HA), mirroring, and disaster recovery (DR). These are often incorrectly painted as binary choices:
- You either have HA or you don't.
- You either have DR or you don't.
The reality is that availability is a spectrum, and where your enterprise needs to be on that spectrum will depend on your business requirements.
There are two important metrics that your business will define in its business continuity plan: recovery time objective (RTO) and recovery point objective (RPO). These metrics are defined by your business for the entire system (not just a single service like Event Streams or a single component of the system such as your own deployment of Kafka).
RTO: Recovery time objective - RTO is the length of time that a business process must be restored after a disaster or disruption to avoid unacceptable consequences associated with a break in business continuity. That is, “How much time can it take to recover after a business process disruption before the business is broken?“
RPO: Recovery point objective - RPO is the maximum targeted period of time in which data (transactions) might be lost from an IT service due to a major incident. That is, "How far back in time can I restore a backup without seriously impacting my business?"
Any particular HA solution is determined by three factors:
- Availability of the service (RTO) - How long can you go without the service?
- Availability of data (RPO) - How much data can you afford to lose?
- Cost - How much are you prepared to pay?
Managing Risk - Expectations and considerations for availability
The primary drive for improving a service's availability is to reduce the risk to the business. Simplistically, risk can be thought of as the combination of two factors:
- The Probability of an event happening
- The Impact of an event
Risk = Probability x Impact
Imagine a skilled tightrope walker. The probability of them falling off a rope is the same whether the rope is just off the ground or strung between two tall buildings. However, the impact of falling off at a great height is dramatically increased. So, we can assert that tightrope walking at a great height carries more risk than tightrope walking closer to the ground.
First, let's consider the types of risks that we are attempting to mitigate when we build a highly available service.
At the lowest level, we are trying to mitigate the failure of the basic components of the service: the machines, networks, disks, and so on. The cloud-native approach to this scenario is to assume that everything can and will fail and to deal with it through redundancy.
Beyond that, we are looking at things like localized natural disasters taking out the whole data centre, such as with floods, fires, and power outages. Cloud-native solutions, like IBM Cloud, mitigate these disasters by providing availability zones (AZs). These are a collection of data centers that make up a single region where your service is hosted.
For example, my local IBM Cloud region is London, and while IBM doesn't publish their exact locations, I know the AZ data centers are distributed around the South East of England in a way that it would be very unlikely for say a flood or fire to take them all out together.
The highest level of disaster would be an entire region failure, such as a massive natural disaster, cyber attacks, or cascading software failure. To mitigate such an event would require the ability to fail-over to a backup service in another region.
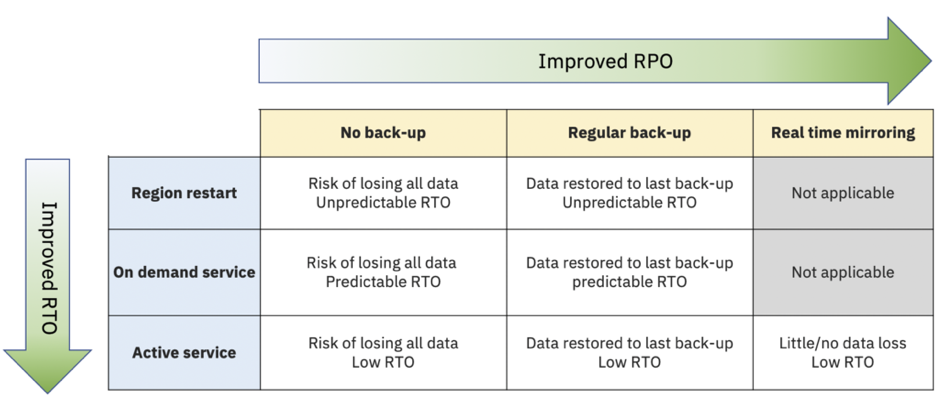
If your requirement is to be able to tolerate a complete region failure, then there are various strategies depending on your defined RPO and RTO requirements:
From the RTO point of view there are a range of options:
- Region restart: Wait for the region to come back on line and the service restarted
- On demand service: Build a new service in a different region when required
- Active service: Have a permanently running second service in another region
From the RPO point of view the options are:
- No back-up: Take no backups, start from scratch
- Regular back-up: Take backups of the active service data at regular intervals to meet the RPO
- Real time mirroring: Send all data in real time to a running service in remote region
As we move down each list, we improve RTO/RPO attainment, while cost also increases.
Combining both RTO and RPO
It is important to remember that your service is just part of a system and that your RTO/RPO requirements apply to every part of the system.
In addition to your service, you will need to consider how to handle your frontend and backend applications. If they are all contained within the failing region, then you will need to ensure that they are cared for in the new environment. If they exist outside of the region, then you will need a mechanism for them to reconnect to the new environment (DNS swapping or hard coded endpoints).
You will also need to consider what triggers a switch to a new region. Is it a manual process where a human operator shuts down everything associated with the failed region and restarts in another? Or do the applications themselves detect a problem and look elsewhere for the service?
What the IBM Event Streams on Cloud service provides
IBM Event Streams commits to deliver 99.99% availability (on average that’s less than 9 seconds of downtime per day). Let's take a look at a couple of ways that this is achieved.
Using three availability zones
If you use the managed Kafka service, IBM Event Streams on Cloud, both the Enterprise and Standard plans for the Event Streams service provide resilience to failures by distributing its Kafka nodes across three AZs in a region.
See my blog "Using Availability Zones to Enhance Event Streams Resilience" to learn how availability zones provide excellent resilience to failure and how to write your applications to exploit this.
Performing regular disaster recovery testing
The Event Streams team carry out regular disaster recovery testing. Recently we simulated a cyber attack on the US-West region, then created a new Event Streams cluster in Washington, and restored all our topics from a back up in a third region.
Since we use the IBM Cloud to run our own business, we also rebuilt our delivery pipeline in the new region to demonstrate that we could continue to push changes to production across the World, several times a day, even after losing our primary region!
How you can enhance HA and DR with IBM Event Streams
If your requirement is to be able to tolerate a complete region failure, then there are various strategies depending on your RTO/RPO requirements:
Build a new enterprise cluster on demand:
- No event data from back up
- Restore event data from a back-up
Permanently running second cluster, with the configuration matching the original cluster:
- No event data from back up
- Event data restored from latest back up when required
- Event data periodically loaded from back up to achieve RPO
Permanently running second cluster, mirroring all the events received on the primary cluster in near real-time or on a regular schedule that still meets your RPO.
The IBM Cloud Object Storage (COS) (https://www.ibm.com/cloud/object-storage) is a potential service for storing backups. Its cross-region capabilities make it useful for this use case since a secondary region can easily access the backups for restoring in the new region. (It is not in the scope of this article to cover how this might be achieved.)
Build a new cluster on demand
This is the most cost effective option; however, it can take up to 3 hours to create and you must have a back-up of your configuration data so the relevant topics can be re-instated. Initially, there will be no data on any of the topics. If you have kept periodic back-ups in IBM Cloud Object Storage, then the events could be restored.
Permanently run a second cluster, pre-configured
Since the Kafka cluster is already running, your RTO is determined by how quickly your applications can connect to the new service. Initially, there will be no data on any of the topics. If you have kept periodic back-ups in IBM Cloud Object Storage, then the events could be restored either at the point of disaster, or at a regular frequency that helps minimize the RPO/RTO when the secondary cluster is called on.
This scenario would be most appropriate when your data has a short lifetime, and it makes sense just to start gathering new data after a failure. In this case, you want a low RTO, but are not concerned about RPO.
It is also possible to use this environment to do periodic restores of events in line with your RPO, so the Kafka cluster is always kept at an appropriate level. This could be achieved using IBM Cloud Object Storage backups or using cross-region mirroring.
Permanently run a second cluster, pre-configured with events or messages mirrored in near real-time
As above, RTO is approaching instantaneous. The difference in this scenario is that any event delivered to the primary cluster is copied in real time to the backup cluster, thus keeping the RPO to a minimum.
The IBM Event Streams on Cloud Enterprise plan provides the option to enable fully managed mirroring between two instances of the service. You can use this to continually copy message data from your primary service instance into a backup instance. Typically, these instances would be located in different regions of the same geography, such as Dallas and Washington.
For example, let's say you’ve setup mirroring from an Event Streams instance in Dallas (primary) to one in Washington (backup). If a major incident occurs that affects the whole Dallas region, your Kafka applications can switch to using the Washington instance and continue to operate as normal. The Washington instance is now the primary instance. At this point you have two options:
Failback: wait for the Dallas instance to become available, mirror any new data from the Washington instance back to the Dallas instance. When this is complete switch your Kafka applications back to using the Dallas instance, making this the primary once again.
Provision a new instance of Event Streams to act as the backup instance. Washington remains the primary and mirroring is setup to copy message data from Washington to the newly provisioned backup instance.
By using the built-in mirroring capability, the RTO time is the amount of time it takes for your Kafka applications to reconnect to the backup site. Often, this can be measured in seconds. Ensuring a low RPO time may limit the rate at which your Kafka applications can produce message data into the primary service instance. This allows the mirroring process to keep up with the rate at which new messages are arriving in order to keep the RPO time to a few seconds. Returning to the example of mirroring between Dallas and Washington, no more than 35MB per second of message data can be produced into the Dallas instance in order to ensure a low RPO time.
To continue learning about mirroring between Event Streams instances, check out our Event Streams on Cloud documentation.
Summary and next steps
High availability and disaster recovery is a complex area that requires much thought and design to achieve the right goals for your business, balancing the availability of your services, the consistency of your data, and the price you are prepared to pay.
While this article focused on the high availability and disaster recovery capabilities of IBM Event Streams on Cloud, it is important to view these capabilities in the broader context of the system, of which Event Streams is one component.
Crucially, whatever approach you take for HA and DR, make sure you document and test the procedure regularly!
You can explore more about building resilient applications on the cloud in the IBM Cloud Architecture Center.