Learning Path
Take control of your data with Watson Studio
Introduction
With IBM Watson Studio, you can visualize and gain insights into your data, then cleanse and transform your data to build high-quality predictive models. You can analyze data and build models in projects with Watson Studio and Watson Machine Learning. The methods you choose for analyzing data or building models help you determine which tools are best for your needs.
Prerequisites
To complete this learning path, you need an IBM Cloud Pak for Data account, which gives you access to IBM Cloud, IBM Watson Studio, and the IBM Watson Machine Learning Service.
Estimated time
It should take you approximately 30 minutes to complete this tutorial.
Steps
Set up your environment
Create your IBM Cloud Pak for Data account.
After creating your IBM Cloud Pak for Data account, several services are provisioned. To see the services, select Services > Service instances from the navigation menu in the upper left corner.
The services should look similar to the following image.
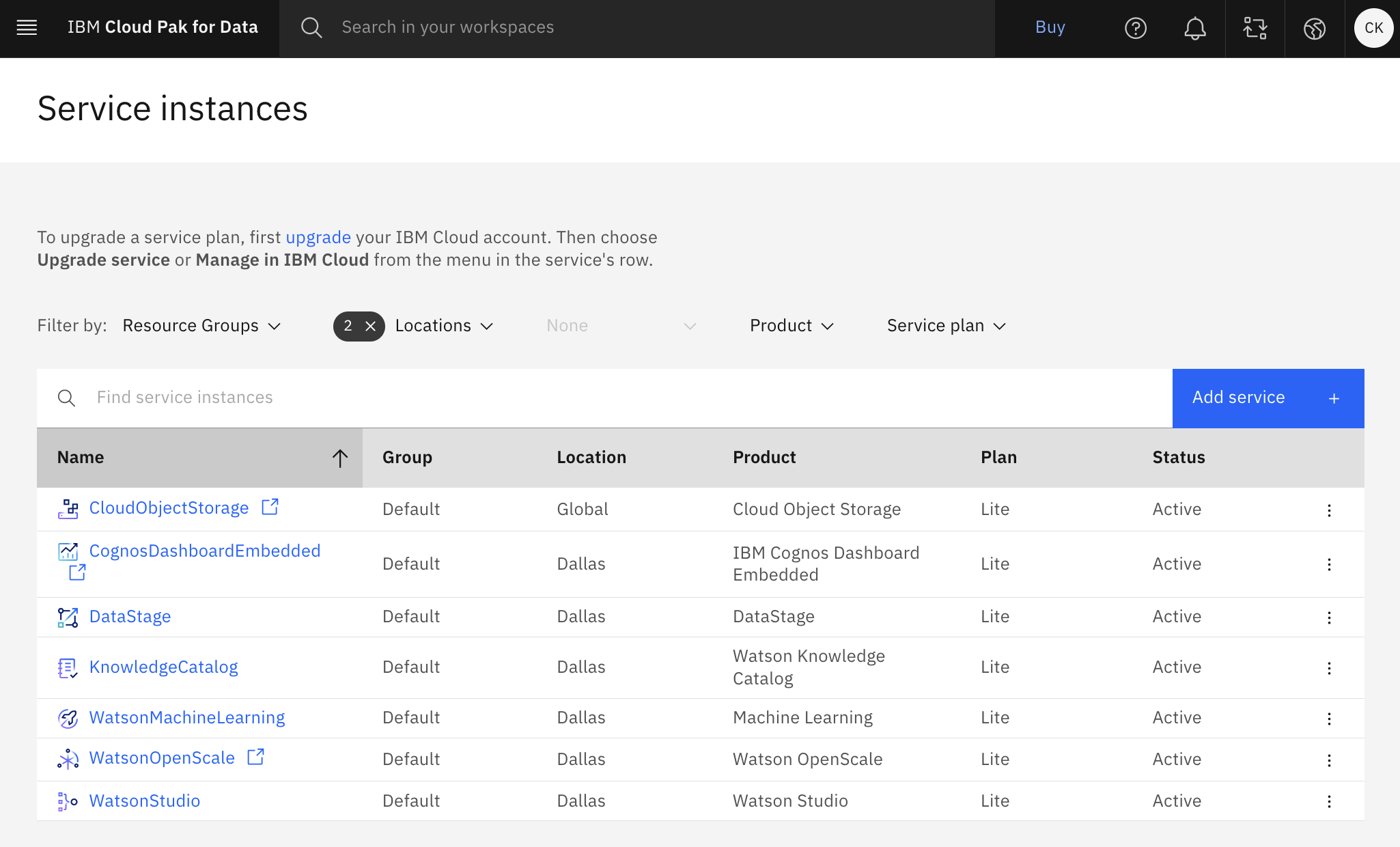
Verify that the following services were created.
- CloudObjectStorage
- DataStage
- KnowledgeCatalog
- WatsonMachineLearning
- WatsonOpenScale
- WatsonStudio
Create Watson Studio project
Watson Studio uses the concept of a project to collect and organize the resources used to achieve a particular goal (resources to build a solution to a problem). Your project resources can include data, collaborators, and analytic assets like notebooks and models, and so on.
There are several ways to create a new project, you can either:
Click Work with data from the IBM Cloud Pak for Data home page

Click Projects -> View all projects in the left-side navigation menu (☰), then click New project +
Click the + sign from the Projects column.
On the Create a project page, you can either create an empty project, or import a file that contains project assets.
When creating a new project, you must provide a unique project name. The IBM Cloud Object Storage service that was provisioned during your account creation process is assigned automatically.
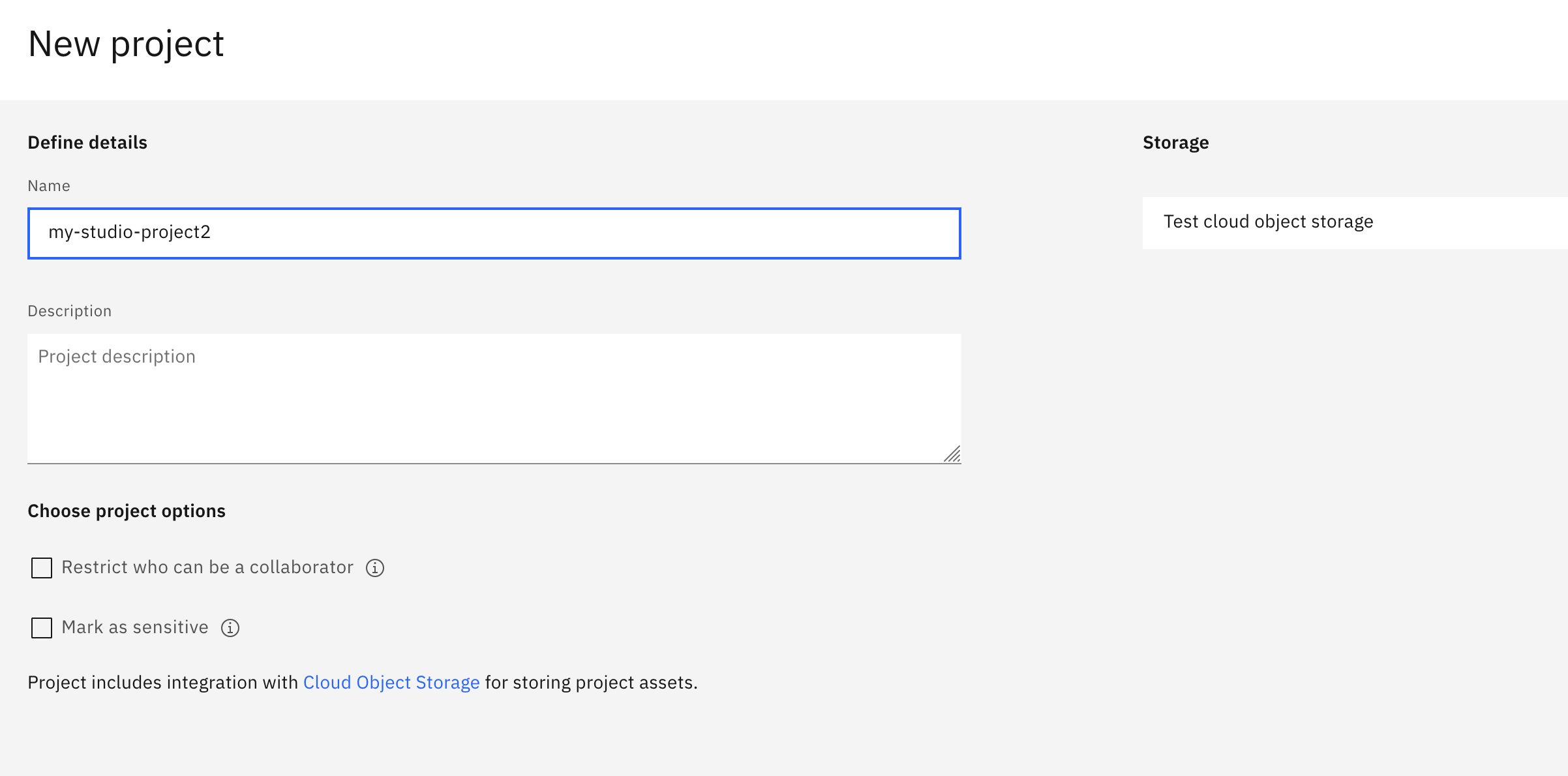
Click Create to finish creating the project.
Basic visualization in Watson Studio
After data is collected, the next step is referred to as the data understanding phase. This consists of activities that enable you to become familiar with the data, identify data quality problems, and discover first insights into the data.
You can achieve this in Watson Studio by simple user interactions, without a single line of code. To learn more about analyzing and visualizing data and understanding the overall workflow, see Getting started with analyzing and visualizing data.
Data preparation and transformation using Data Refinery and DataStage
The data preparation phase covers all activities needed to construct the final data set that is fed into the machine learning service. Data preparation tasks are likely to be performed multiple times and not in any prescribed order. Tasks include table, record, and attribute selection as well as transformation and cleansing of data for the modeling tools. This can involve turning categorical features into numerical ones, normalizing the features, and removing columns not relevant for prediction.
Watson Studio offers a service called Data Refinery that lets you clean up and transform data without any programming. Data Refinery saves data preparation time by quickly transforming large amounts of raw data into consumable, high-quality information that is ready for analytics.
Data Refinery Flows allow you to perform quick transformations of data without the need for programming. To learn more about refining your data, see this quick start on refining data.
DataStage is a data integration tool that moves and transforms data between operational, transactional, and analytical target systems. Data integration specialists use DataStage to develop flows that process and transform data. Hundreds of prebuilt transformation functions, parallel processing capabilities, and platform connectivity is available to connect directly to enterprise applications, cloud data sources, relational and NoSQL systems, REST endpoints, and more. You can administer, manage, deploy, and reuse these flows to integrate data across many systems throughout your organization.
To learn more about transforming your data, see this quick start guide.
Conclusion
This tutorial covered some of the tools available in Watson Studio for visualizing, preparing, and transforming you data.