Learning Path
Get started using Kubernetes Operators
- Overview
- Intro to Kubernetes Operators
- Deep dive into Kubernetes operators
- Develop and deploy a Level I JanusGraph Operator using BerkeleyDB
- Develop and deploy a Level I JanusGraph operator using Apache Cassandra
- The Operator Cookbook: How to make an operator
- Seamlessly upgrade a JanusGraph operator
- Certify a JanusGraph image and operator for publishing to the Red Hat Marketplace
- Summary
This tutorial shows you how to develop and deploy a Level I operator on the Red Hat OpenShift Container Platform. You will create an operator for JanusGraph that uses Apache Cassandra as a storage back end. Cassandra is a distributed database platform that can scale and be highly available, and can perform really well on any commodity hardware or cloud infrastructure.
When you have completed this tutorial, you will understand how to:
- Deploy Cassandra as back-end storage.
- Create a JanusGraph image that runs well in OpenShift, not just Kubernetes.
- Deploy a JanusGraph operator to an OpenShift cluster.
- Scale a JanusGraph instance up or down by modifying and applying the custom resource (CR) to an OpenShift cluster.
Note: Cassandra deployment is not part of this tutorial. We assume that Cassandra is already available, whether its deployed from operator hub or as a stand-alone deployment.
A Level I JanusGraph operator has the following capabilities:
- Deploys JanusGraph by creating its Services, Deployments, and RoleBinding
- Ensures that managed resources reach a healthy state, and conveys readiness of the resources to the user through the status block of the CR
- Manages scalability by resizing the underlying resources in response to changes in the CR
Flow

Included components
- Apache Cassandra -- The Cassandra database is the right choice when you need scalability and high availability without compromising performance.
- JanusGraph -- JanusGraph is a scalable graph database that's optimized for storing and querying graphs containing hundreds of billions of vertices and edges distributed across a multi-machine cluster.
- Red Hat OpenShift -- OpenShift is a powerful, flexible hybrid cloud platform that enables you to build a wide range of solutions that work anywhere.
Featured technology
- Red Hat OpenShift Operator: Operator automates the creation, configuration, and management of Kubernetes-native application instances.
Prerequisites
To complete this tutorial, we assume that you:
- have little or no experience developing operators
- have some knowledge of Kubernetes Operators concepts
- have created a memcached operator
- have read "Explanation of memcached operator code"
- have set up your environment as shown in the "Set up your environment" tutorial
Estimated time
It should take you about 1 hour to complete this tutorial.
Steps
1. Deploy Cassandra to OpenShift
Clone the cassandra-openshift locally. In a terminal, run:
$ git clone https://github.com/IBM/janusgraph-operator.git
$ cd cassandra-openshift
You need to update the default configurations of Cassandra so that it can be deployed to OpenShift. The changes are defined in the Dockerfile. In order to adapt to the OpenShift environment, you need to change the group ownership and file permission to root. (See Set group ownership and file permission in "Best practices for designing a universal application image.") Although OpenShift runs containers using an arbitrarily assigned user ID, the group ID must always be set to the root group (0).
You can build and push the Cassandra image to your image repository by running following commands:
docker build -t cassandra:1.0
docker tag cassandra:1.0 <repository hostname>/<username>/cassandra:1.0
docker push <repository hostname>/<username>/cassandra:1.0
Note: You need to change "repository hostname" and "username" accordingly.
After the image is built, you can deploy Cassandra as a StatefulSet in OpenShift.
Run the following command to deploy Cassandra from the cloned directory in the terminal:
$ oc apply -f cassandra-app-v1.yaml -f cassandra-svc-v1.yaml
To ensure that Cassandra is running, it should create one instance of the Cassandra database. If you want to have multiple replicas, you can modify replicas in the cassandra-app-v1.yaml.

2. Clone and modify the JanusGraph Docker image
The JanusGraph Docker image from the official repo deploys fine into Kubernetes but runs into errors when deployed into OpenShift. There are few things that need to be modified before you can deploy:
- Fork the repo
https://github.com/JanusGraph/janusgraph-docker. - Change the file and group ownership to root (0) for related folders. The following modifications apply to the
Dockerfile:
chgrp -R 1001:0 ${JANUS_HOME} ${JANUS_INITDB_DIR} ${JANUS_CONFIG_DIR} ${JANUS_DATA_DIR} && \
chmod -R g+w ${JANUS_HOME} ${JANUS_INITDB_DIR} ${JANUS_CONFIG_DIR} ${JANUS_DATA_DIR}
RUN chmod u+x /opt/janusgraph/bin/gremlin.sh
RUN chmod u+x /opt/janusgraph/conf/remote.yaml
- Change the
JANUS_PROPS_TEMPLATEproperty value tocql. This specifies to use Cassandra as the back end database. - Create a
janusgraph-cql-server.propertiesfile in the latest version directory (which in this case is0.5) and add the following properties:
gremlin.graph=org.janusgraph.core.JanusGraphFactory
storage.backend=cql
storage.hostname=cassandra-service
storage.username=cassandra
storage.password=cassandra
storage.cql.keyspace=janusgraph
storage.cassandra.replication-factor=3
storage.cassandra.replication-strategy-class=org.apache.cassandra.locator.NetworkTopologyStrategy
cache.db-cache = true
cache.db-cache-clean-wait = 20
cache.db-cache-time = 180000
cache.db-cache-size = 0.5
storage.directory=/var/lib/janusgraph/data
index.search.backend=lucene
index.search.directory=/var/lib/janusgraph/index
These properties configure JanusGraph to connect to Cassandra and use it to store its data. Whereas the default database, BerkeleyDB, runs in a single container, Cassandra runs in a cluster of containers.
Also, update the storage.hostname property in the janusgraph-cql-server.properties file with the IP address for the Cassandra service. The IP address for Cassandra running in a Kubernetes cluster is shown as the Kubernetes service's Cluster-IP property. You can find that property in an OpenShift cluster by running the oc get svc command, as shown here:

Now you can build and deploy the JanusGraph Docker image to OpenShift by running the following script:
$ ./build-images.sh
OR
Make a copy of the build-images.sh file and replace with the modified script. Before you run make sure to modify the tag and the IMAGE_NAME accordingly and run the script.
3. Deploy the JanusGraph operator
Use the Operator SDK to create the operator project, and you can initialize and create the project structure using the SDK. To make things easier, we have already created a project structure using the SDK. If you want to learn more about Operator SDK and controller code structure, you can check out our operator tutorials.
First, clone the repo:
git clone https://github.com/IBM/janusgraph-operator.git
From the cloned repo, we will be using few scripts to build and deploy JanusGraph operator.
The CR instance should look like this:
apiVersion: graph.ibm.com/v1alpha1
kind: Janusgraph
metadata:
name: janusgraph-sample
spec:
# Add fields here
size: 3
version: latest
And the spec definition in your API should look like this:
type JanusgraphSpec struct {}
Size int32 `json:"size"`
Version string `json:"version"`
}
From the cloned project root directory, open the build-and-deploy.sh script in an editor and change following parameters:
img="<image repo name>/<username>/<image name>:<tag>"
namespace="<namespace>"
And finally, run the following script from your terminal that you can find in the cloned repo:
$ ./build-and-deploy.sh
For more information, you can check out the controller code. The operator controller code is responsible for the following tasks:
- Creates the Kubernetes Service that exposes the JanusGraph database with an IP
- Creates the Kubernetes Deployments containing JanusGraph images, configuring them based on the specification in the CR
- Sets the status block in the CR to show the readiness of the JanusGraph database
Let's take a look at all of the resources that the operator has deployed for JanusGraph. Run the following command in your terminal:
$ oc get all
The output should look like this:

4. Load and test retrieval of data using the Gremlin console
To load the data, use your Gremlin console to run the Groovy script load_data.groovy. To do so, first, download the Gremlin console if you haven't already done so.
Once it's downloaded and unzipped, go to conf/remote.yaml and update it with the following configuration:
hosts: [HOST_NAME]
port: 8182
serializer: {
className: org.apache.tinkerpop.gremlin.driver.ser.GryoMessageSerializerV3d0, config: { serializeResultToString: true }
}
connectionPool: {
enableSsl: false,
maxInProcessPerConnection: 16,
# The maximum number of times that a connection can be borrowed from the pool simultaneously.
maxSimultaneousUsagePerConnection: 32,
# The maximum size of a connection pool for a host.
maxSize: 32,
maxContentLength: 81928192
}
# Size of the pool for handling background work. default : available processors * 2
workerPoolSize: 16
# Size of the pool for handling request/response operations. # default : available processors
nioPoolSize: 8
Note: HOST_NAME is the external IP from your cluster and it can be retrieved using oc get svc. Copy the EXTERNAL-IP for janusgraph-sample-service and replace it.
Copy the Groovy script and paste it into the Gremlin console data directory. Then, from the terminal, run the following from the root of your Gremlin console:
$ bin/gremlin.sh
$ :remote connect tinkerpop.server conf/remote.yaml
Then run the following command to load the Groovy script that you copied and pasted to the data directory:
$ :load data/load_data.groovy
To retrieve the data and test to make sure the data has been successfully loaded, run a gremlin query to get all the airlines:
gremlin> g.V().has("object_type", "flight").limit(30000).values("airlines").dedup().toList()
==>MilkyWay Airlines
==>Spartan Airlines
==>Phoenix Airlines
You have now successfully loaded your data.
In the next section, you will scale the JanusGraph instance by changing the number of pod replicas. As you do so, rerun this Gremlin query to show that the set of data in the database remains the same, and that starting or stopping pod replicas does not duplicate or lose data.
5. Scaling JanusGraph
The JanusGraph instance can scale to run more pods to handle more client load and spread it across more cluster nodes. However, scaling is adjusted differently when an operator is managing an instance. Let's look at two approaches that a developer can use to scale a set of pods:
- First, we’ll look at how you can scale a set of pods manually, and examine why that doesn't work quite the same with an operator.
- Second, we'll look at how you can use an operator to scale a set of pods that the operator is managing.
Manually adjust the number of pod replicas
From your provisioned cluster, which you already set up as part of the prerequisites, select the cluster and go to OpenShift web console by clicking the button from top-right corner of the page.
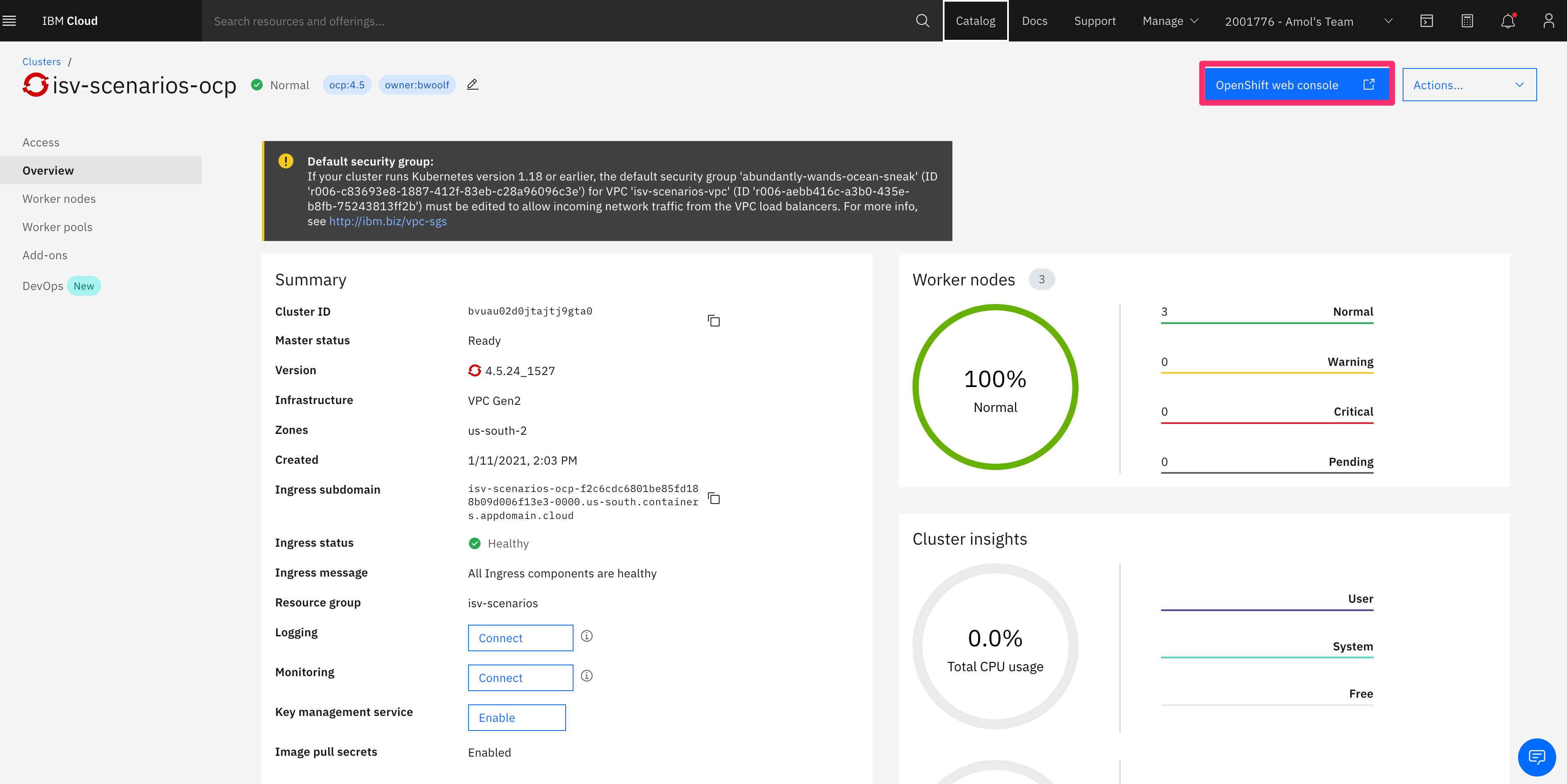
In the OpenShift console, select your project in the Project combo box along the top of the window. Your project is the namespace that you deployed your operator into.
Then, from the left navigation menu, select Workloads and Stateful Sets. Click on the one named janusgraph-sample.

This will bring you to a screen that shows the number of replicas that have been deployed.

Typically, a developer can use this view to manually change the number of pod replicas, but this works a bit differently in a Deployment or StatefulSet that's managed by an operator. In this view, you can use the up and down arrows next to the set of pods to increase or decrease the number of pods. Indeed, if you try that here, the view shows that the number of replicas does change. But wait a minute and the number changes back to 3 again. Why? Because this resource is managed by the JanusGraph operator, and its CR says that the size is 3. So when the size differs from 3, the operator puts it back.
To adjust the number of pod replicas and have the change stick, you'll need to use the operator.
Use the operator to adjust the number of pod replicas
To tell the operator to adjust the number of pod replicas, change that setting in the CR. Because the CR describes the instance's configuration, changing the settings in the CR causes the operator to change the configuration in the instance.
To scale the number of pod replicas in the JanusGraph instance, change the spec in your CR instance -- change the size in the following spec:
apiVersion: graph.example.com/v1alpha1
kind: Janusgraph
metadata:
name: janusgraph-sample
spec:
# update the size to scale/descale Janusgraph instances
size: 3
version: 1.0.1
And apply to the cluster using:
oc apply -f samples/graph_v1alpha1_janusgraph.yaml
In the view of the StatefulSet in the OpenShift console, watch the number of pod replicas. After a minute, the number will adjust to the new size you specified in the CR. This is because the operator saw the new size and made the necessary adjustments to the instance it's managing.
Conclusion
Congratulations! You have now successfully deployed a Level I JanusGraph operator, tested the deployment by resizing the replicas, and checked the integrity of the data in new pods. You are now ready to move on to the other tutorials in this learning path, which show you how to build an operator and how to prepare and certify a JanusGraph operator so it can be published to the Red Hat Marketplace.