Learning Path
Get started using Kubernetes Operators
- Overview
- Intro to Kubernetes Operators
- Deep dive into Kubernetes operators
- Develop and deploy a Level I JanusGraph Operator using BerkeleyDB
- Develop and deploy a Level I JanusGraph operator using Apache Cassandra
- The Operator Cookbook: How to make an operator
- Seamlessly upgrade a JanusGraph operator
- Certify a JanusGraph image and operator for publishing to the Red Hat Marketplace
- Summary
For developers who understand what Kubernetes operators are and how they work, the next step is to build and deploy one yourself. Follow the steps in this tutorial to develop and deploy a Memcached Operator to Red Hat OpenShift. In this tutorial, you will learn the basic concepts and steps needed to develop a Golang-based operator to manage Kubernetes resources.
Note: This tutorial can apply to other Kubernetes clusters as well, however the commands may differ slightly.
Prerequisites
This tutorial assumes that you have some knowledge of Kubernetes operators concepts but little or no experience developing operators. If you need a refresher, read Intro to Kubernetes Operators.
Important: If you haven't set up your environment for building Kubernetes operators, see these installation instructions.
Note: This tutorial is inspired by the Operator SDK tutorial. Thanks to the Operator SDK team for a great tutorial!
Estimated time
It should take you about 1 hour to complete this tutorial.
Flow

- Create a new operator project using the Operator SDK command-line interface (CLI).
- Define new resource APIs by adding custom resource definitions (CRD).
- Define controllers to watch and reconcile resources.
- Write the reconciling logic for your controller using the SDK and controller-runtime APIs
- Use the SDK CLI to build and generate the operator deployment manifests.
- Use the SDK CLI to build the operator image, push it to the image registry, and then deploy to OpenShift.
- When the operator is deployed, it creates a custom controller which is responsible for deploying the application.
- The reconcile loop watches and heals the resources as needed.
Steps
- Prerequisites
- Estimated time
- Flow
- Steps
- Step 1: Create a new project using the Operator SDK
- Step 2: Create an API and custom controller
- Step 3: Update the API
- What is the Status?
- Step 4: Implement the controller logic
- Step 5: Compile, build, and push
- Step 6: Deploy the operator to your OpenShift cluster
- Step 7: Create the custom resource
- Step 8: Test and verify
- Cleanup
Step 1: Create a new project using the Operator SDK
Check your Go version. This tutorial is tested with the following Go version:
go version go version go1.15.6 darwin/amd64Next, create a directory where you will hold your project files:
mkdir $HOME/projects/memcached-operator cd $HOME/projects/memcached-operatorNote: Before your run the
operator-sdk initcommand, yourmemcached-operatordirectory must be completely empty, otherwise KubeBuilder will complain with an error. This means you can't have a.gitfolder, etc.Run the
operator-sdk initcommand to create a new memcached-operator project:operator-sdk init --domain=example.com --repo=github.com/example/memcached-operator- The
--domainflag is used to uniquely identify the operator resources that this project creates. - The
example.comdomain is used as part of the Kubernetes API group. When you use the commandoc api-resourceslater, theexample.comdomain will be listed there by yourmemcachedin theAPIGROUPcategory.
- The
Set up your Go modules
You must set up your Go modules properly to develop and run your operator. The --repo flag sets the name to use for your Go module, which is specified at the top of your go.mod file:
module github.com/example/memcached-operator
Setting up your Go module enables you to work outside of your GOPATH, as long as the working directory of the project is the same as the name of the module in the top of the go.mod file.
Make sure that your directory is called
memcached-operatorand that yourgo.modfile shows the following Go module:module github.com/example/memcached-operatorFor Go modules to work properly, activate Go module support by running the following command:
export GO111MODULE=onVerify that Go module support is turned on by issuing the following command and ensuring you get the same output:
$ echo $GO111MODULE on
You should now have the basic scaffold for your operator, such as the bin, config, and hack directories, as well as the main.go file that initializes the manager.
Step 2: Create an API and custom controller
This section shows you how to use the operator-sdk create api command to create an API, which will be in your api directory, and a blank custom controller file, which will be in your controllers directory.
Use the --group, --version, and --kind flags to pass in the resource group and version. These 3 flags together form the fully qualified name of a Kubernetes resource type. This name must be unique across a cluster.
$ operator-sdk create api --group=cache --version=v1alpha1 --kind=Memcached --controller --resource
Writing scaffold for you to edit...
api/v1alpha1/memcached_types.go
controllers/memcached_controller.go
- The
--groupflag defines anAPI Groupin Kubernetes. It is a collection of related functionality. - Each group has one or more
versions, which allows you to change how an API works over time. This is what the--versionflag represents. - Each API group-version contains one or more API types, called
Kinds. This is the name of the API type that you are creating as part of this operator.- There are more nuances to versioning that we will not cover here. Read more about groups, versions, kinds, and resources in this KubeBuilder reference.
- The
--controllerflag signifies that the SDK should scaffold a controller file. - The
--resourceflag signifies that the SDK should scaffold the schema for a resource.
Once you deploy this operator, you can use kubectl api-resources to see the name cache.example.com as the api-group, and Memcached as the Kind. You can try this command later after you deploy the operator.
(Optional) Troubleshooting the create api command
If you get an error running the create api command, you most likely need to install the modules manually.
Here is an example error:
Error: go exit status 1: go: github.com/example/memcached-operator/controllers: package github.com/go-logr/logr imported from implicitly required module; to add missing requirements, run:
go get github.com/go-logr/logr@v0.3.0
You will have to install the modules manually by running the following commands:
go get github.com/go-logr/logr@v0.3.0
go get github.com/onsi/ginkgo@v1.14.1
go get github.com/onsi/gomega@v1.10.2
Step 3: Update the API
Defining an API is one of the two main parts of the operator pattern. Defining your API creates your custom resource definition (CRD) and is done in the api/v1alpha1/memcached_types.go file.
First, you need to understand the struct that defines your schema. Note that it
implements the Object interface, which means it is a Kubernetes object. Also, it has the Spec and Status fields.
type Memcached struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
Spec MemcachedSpec `json:"spec,omitempty"`
Status MemcachedStatus `json:"status,omitempty"`
}
What is the Spec?
The MemcachedSpec struct, referenced as the Spec, defines the desired state of the resource. A good way to think about Spec is that any inputs (values tweaked by the user) to your controller go in the Spec section. The controller code references the Spec section to determine how many replicas to deploy.
What is the Status?
The MemcachedStatus struct, referenced as the Status, defines the current, observed state of the resource. The status contains information that users or other controllers can easily obtain. The status is updated in the controller code, which updates the current state of the cluster.
The MemcachedStatus struct and the MemcachedSpec struct each has its own fields to describe the observed state and the desired state, respectively.
Add a
Size int32field to yourMemcachedSpecstruct, along with the JSON-encoded string representation of the field name, in lowercase. See Golang's JSON encoding page for more details.In this example, since
Sizeis the field name and the JSON encoding must be lowercase, it would look likejson:"size".Add the following to your struct:
type MemcachedSpec struct { // INSERT ADDITIONAL SPEC FIELDS - desired state of cluster // Important: Run "make" to regenerate code after modifying this file // Foo is an example field of Memcached. Edit Memcached_types.go to remove/update Size int32 `json:"size"` }When you create a custom resource later, you will need to fill in the size, which is the number of
Memcachedreplicas you want as thedesired stateof your system.Add a
Nodes []stringfield to yourMemcachedStatusstruct, as shown here:// MemcachedStatus defines the observed state of Memcached type MemcachedStatus struct { // INSERT ADDITIONAL STATUS FIELD - define observed state of cluster // Important: Run "make" to regenerate code after modifying this file Nodes []string `json:"nodes"` }The
MemcachedStatusstruct uses a string array to list the name of theMemcachedpods in the current state.Lastly, the
Memcachedstruct has the fieldsSpecandStatusto denote the desired state (spec) and the observed state (status). At a high level, when the system recognizes that there is a difference in the spec and the status, the operator uses custom controller logic defined in thecontrollers/memcached_controller.gofile to update the system to achieve the desired state.
Output and code explanation
Now that you've modified the file api/v1alpha1/memcached_types.go, it should look like the file in the artifacts directory:
package v1alpha1
import (
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
)
// EDIT THIS FILE! THIS IS SCAFFOLDING FOR YOU TO OWN!
// NOTE: json tags are required. Any new fields you add must have json tags for the fields to be serialized.
// MemcachedSpec defines the desired state of Memcached
type MemcachedSpec struct {
// INSERT ADDITIONAL SPEC FIELDS - desired state of cluster
// Important: Run "make" to regenerate code after modifying this file
// Foo is an example field of Memcached. Edit Memcached_types.go to remove/update
Size int32 `json:"size"`
}
// MemcachedStatus defines the observed state of Memcached
type MemcachedStatus struct {
// INSERT ADDITIONAL STATUS FIELD - define observed state of cluster
// Important: Run "make" to regenerate code after modifying this file
Nodes []string `json:"nodes"`
}
// +kubebuilder:object:root=true
// +kubebuilder:subresource:status
// Memcached is the Schema for the memcacheds API
type Memcached struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
Spec MemcachedSpec `json:"spec,omitempty"`
Status MemcachedStatus `json:"status,omitempty"`
}
// +kubebuilder:object:root=true
// MemcachedList contains a list of Memcached
type MemcachedList struct {
metav1.TypeMeta `json:",inline"`
metav1.ListMeta `json:"metadata,omitempty"`
Items []Memcached `json:"items"`
}
func init() {
SchemeBuilder.Register(&Memcached{}, &MemcachedList{})
}
Above type Memcached struct, there are two lines of code starting with +kubebuilder -- note that they are actually commented out. They are important because they provide additional information to the controller-tools. For example, this line:
// +kubebuilder:object:root=true
tells the object generator that this type represents a Kind. The generator then implements the runtime.Object interface for you, which all Kinds must implement.
And this line:
// +kubebuilder:subresource:status
adds the status subresource in the custom resource definition. If you run make manifests, it generates YAML under config/crds/<kind_types.yaml. It also adds a subresources section like so:
subresources:
status: {}
The next section shows you how to get and update the status subresource in the controller code.
The key thing to know here is that each of these markers, starting with // +kubebuilder, generate utility code (such as role-based access control) and Kubernetes YAML. When you run make generate and make manifests, your KubeBuilder Markers are read in order to create RBAC roles, CRDs, and code. Read more about KubeBuilder markers.
Step 4: Implement the controller logic
Note: If you want to learn more in depth about the controller logic, please see our accompanying article, Deep dive into Memcached Operator Code.
Now that the API is updated, the next step is to implement the controller logic in controllers/memcached_controller.go.
Copy the code from the artifacts/memcached_controller.go file, and replace your current controller code.
Once this is complete, your controller should look like the following:
/*
Copyright 2021.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
*/
package controllers
import (
"reflect"
appsv1 "k8s.io/api/apps/v1"
corev1 "k8s.io/api/core/v1"
"k8s.io/apimachinery/pkg/api/errors"
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
"context"
"github.com/go-logr/logr"
"k8s.io/apimachinery/pkg/runtime"
ctrl "sigs.k8s.io/controller-runtime"
"sigs.k8s.io/controller-runtime/pkg/client"
cachev1alpha1 "github.com/example/memcached-operator/api/v1alpha1"
)
// MemcachedReconciler reconciles a Memcached object
type MemcachedReconciler struct {
client.Client
Log logr.Logger
Scheme *runtime.Scheme
}
// generate rbac to get, list, watch, create, update and patch the memcached status the nencached resource
// +kubebuilder:rbac:groups=cache.example.com,resources=memcacheds,verbs=get;list;watch;create;update;patch;delete
// generate rbac to get, update and patch the memcached status the memcached/finalizers
// +kubebuilder:rbac:groups=cache.example.com,resources=memcacheds/status,verbs=get;update;patch
// generate rbac to update the memcached/finalizers
// +kubebuilder:rbac:groups=cache.example.com,resources=memcacheds/finalizers,verbs=update
// generate rbac to get, list, watch, create, update, patch, and delete deployments
// +kubebuilder:rbac:groups=apps,resources=deployments,verbs=get;list;watch;create;update;patch;delete
// generate rbac to get,list, and watch pods
// +kubebuilder:rbac:groups=core,resources=pods,verbs=get;list;watch
// Reconcile is part of the main kubernetes reconciliation loop which aims to
// move the current state of the cluster closer to the desired state.
// TODO(user): Modify the Reconcile function to compare the state specified by
// the Memcached object against the actual cluster state, and then
// perform operations to make the cluster state reflect the state specified by
// the user.
//
// For more details, check Reconcile and its Result here:
// - https://pkg.go.dev/sigs.k8s.io/controller-runtime@v0.7.0/pkg/reconcile
func (r *MemcachedReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
log := r.Log.WithValues("memcached", req.NamespacedName)
// Fetch the Memcached instance
memcached := &cachev1alpha1.Memcached{}
err := r.Get(ctx, req.NamespacedName, memcached)
if err != nil {
if errors.IsNotFound(err) {
// Request object not found, could have been deleted after reconcile request.
// Owned objects are automatically garbage collected. For additional cleanup logic use finalizers.
// Return and don't requeue
log.Info("Memcached resource not found. Ignoring since object must be deleted")
return ctrl.Result{}, nil
}
// Error reading the object - requeue the request.
log.Error(err, "Failed to get Memcached")
return ctrl.Result{}, err
}
// Check if the deployment already exists, if not create a new one
found := &appsv1.Deployment{}
err = r.Get(ctx, req.NamespacedName, found)
if err != nil && errors.IsNotFound(err) {
// Define a new deployment
dep := r.deploymentForMemcached(memcached)
log.Info("Creating a new Deployment", "Deployment.Namespace", dep.Namespace, "Deployment.Name", dep.Name)
err = r.Create(ctx, dep)
if err != nil {
log.Error(err, "Failed to create new Deployment", "Deployment.Namespace", dep.Namespace, "Deployment.Name", dep.Name)
return ctrl.Result{}, err
}
// Deployment created successfully - return and requeue
return ctrl.Result{Requeue: true}, nil
} else if err != nil {
log.Error(err, "Failed to get Deployment")
return ctrl.Result{}, err
}
// Ensure the deployment size is the same as the spec
size := memcached.Spec.Size
if *found.Spec.Replicas != size {
found.Spec.Replicas = &size
err = r.Update(ctx, found)
if err != nil {
log.Error(err, "Failed to update Deployment", "Deployment.Namespace", found.Namespace, "Deployment.Name", found.Name)
return ctrl.Result{}, err
}
// Spec updated - return and requeue
return ctrl.Result{Requeue: true}, nil
}
// Update the Memcached status with the pod names
// List the pods for this memcached's deployment
podList := &corev1.PodList{}
listOpts := []client.ListOption{
client.InNamespace(memcached.Namespace),
client.MatchingLabels(labelsForMemcached(memcached.Name)),
}
if err = r.List(ctx, podList, listOpts...); err != nil {
log.Error(err, "Failed to list pods", "Memcached.Namespace", memcached.Namespace, "Memcached.Name", memcached.Name)
return ctrl.Result{}, err
}
podNames := getPodNames(podList.Items)
// Update status.Nodes if needed
if !reflect.DeepEqual(podNames, memcached.Status.Nodes) {
memcached.Status.Nodes = podNames
err := r.Status().Update(ctx, memcached)
if err != nil {
log.Error(err, "Failed to update Memcached status")
return ctrl.Result{}, err
}
}
return ctrl.Result{}, nil
}
// deploymentForMemcached returns a memcached Deployment object
func (r *MemcachedReconciler) deploymentForMemcached(m *cachev1alpha1.Memcached) *appsv1.Deployment {
ls := labelsForMemcached(m.Name)
replicas := m.Spec.Size
dep := &appsv1.Deployment{
ObjectMeta: metav1.ObjectMeta{
Name: m.Name,
Namespace: m.Namespace,
},
Spec: appsv1.DeploymentSpec{
Replicas: &replicas,
Selector: &metav1.LabelSelector{
MatchLabels: ls,
},
Template: corev1.PodTemplateSpec{
ObjectMeta: metav1.ObjectMeta{
Labels: ls,
},
Spec: corev1.PodSpec{
Containers: []corev1.Container{{
Image: "memcached:1.4.36-alpine",
Name: "memcached",
Command: []string{"memcached", "-m=64", "-o", "modern", "-v"},
Ports: []corev1.ContainerPort{{
ContainerPort: 11211,
Name: "memcached",
}},
}},
},
},
},
}
// Set Memcached instance as the owner and controller
ctrl.SetControllerReference(m, dep, r.Scheme)
return dep
}
// labelsForMemcached returns the labels for selecting the resources
// belonging to the given memcached CR name.
func labelsForMemcached(name string) map[string]string {
return map[string]string{"app": "memcached", "memcached_cr": name}
}
// getPodNames returns the pod names of the array of pods passed in
func getPodNames(pods []corev1.Pod) []string {
var podNames []string
for _, pod := range pods {
podNames = append(podNames, pod.Name)
}
return podNames
}
// SetupWithManager sets up the controller with the Manager.
func (r *MemcachedReconciler) SetupWithManager(mgr ctrl.Manager) error {
return ctrl.NewControllerManagedBy(mgr).
For(&cachev1alpha1.Memcached{}).
Owns(&appsv1.Deployment{}).
Complete(r)
}
Step 5: Compile, build, and push
Now you are ready to compile, build the image of your operator, and push the image to an image repository. You can use the image registry of your choice, but this tutorial uses Docker Hub. If you plan on deploying to an OpenShift cluster, log in to your cluster now.
- From your provisioned cluster that you set up in the
installation.mdfile, select the cluster. Open the
OpenShift web consoleby clicking the button on the top right corner of the page.
From the OpenShift web console, copy the login command from the account drop-down menu.

From your terminal, run the command to log in to your cluster. Once you've logged in, you should see output like the following:
$ oc login --token=fFQ-HbFVBT4qHKl1n0b*****63U --server=https://c****-e.us-south.containers.cloud.ibm.com:31047 s-south.containers.cloud.ibm.com:31047 Logged into "https://c116-e.us-south.containers.cloud.ibm.com:31047" as "IAM#horea.porutiu@ibm.com" using the token provided. You have access to 84 projects, the list has been suppressed. You can list all projects with 'oc projects' Using project "horea-test-scc".Extremely important: By running the login command, you should now be able to run
oc projectto see which project you are currently in. The project you're in is your namespace as well. This is important because your operator only runs in the namespace you deploy it to. OpenShift connects to your cluster via this login command, and if you do not do this step properly you will not be able to deploy your operator.Create a new project using the following command:
oc new-project <new-project-name>Once you create a new project, you will be automatically switched to that project, as the output below shows:
$ oc new-project memcache-demo-project Now using project "memcache-demo-project" on server "https://c116-e.us-south.containers.cloud.ibm.com:31047".
For the rest of this tutorial, you should use memcache-demo-project (or whatever you named your project) as your namespace. The following steps go into more detail about this, but keep in mind that your project is the same as your namespace in terms of OpenShift.
Edit the manager.yaml file
The manager.yaml file defines a deployment manifest that's used to deploy the operator. This manifest includes a security context that tells Kubernetes to run the pods as a specific user (uid=65532). OpenShift already manages the users that are employed to run pods, which is behavior the manifest should not override. So you should remove that from the manifest.
To do this, modify the config/manager/manager.yaml file to remove the following line:
runAsUser: 65532
This enables OpenShift to run its default security constraint. After you remove the runAsUser line and save the file, your file should look like the following (it is the same as the one in the artifacts directory):
apiVersion: v1
kind: Namespace
metadata:
labels:
control-plane: controller-manager
name: system
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: controller-manager
namespace: system
labels:
control-plane: controller-manager
spec:
selector:
matchLabels:
control-plane: controller-manager
replicas: 1
template:
metadata:
labels:
control-plane: controller-manager
spec:
securityContext:
containers:
- command:
- /manager
args:
- --leader-elect
image: controller:latest
name: manager
securityContext:
allowPrivilegeEscalation: false
livenessProbe:
httpGet:
path: /healthz
port: 8081
initialDelaySeconds: 15
periodSeconds: 20
readinessProbe:
httpGet:
path: /readyz
port: 8081
initialDelaySeconds: 5
periodSeconds: 10
resources:
limits:
cpu: 100m
memory: 30Mi
requests:
cpu: 100m
memory: 20Mi
terminationGracePeriodSeconds: 10
Create CRD and RBAC
The generated code from the operator-sdk creates a Makefile. This Makefile allows you to use the make command to compile your go operator code.
Now that your controller code and API are implemented, run the following command to implement the required Go type interfaces:
make generateThis command updates your
api/v1alpha1/zz_generated.deepcopy.gofile to implement the metav1.Object and runtime.Object interfaces. This enables your custom resource to be treated like a native Kubernetes resource.After the code is generated for your custom resource, you can use the
make manifestscommand to generate CRD manifests and RBAC from KubeBuilder Markers:make manifestsThis command invokes
controller-gento generate the CRD manifests atconfig/crd/bases/cache.example.com_memcacheds.yaml. You can see the YAML representation of the object you specified in your_types.gofile. It also generates RBAC YAML files in theconfig/rbacdirectory based on your KubeBuilder markers.
Don't worry about KubeBuilder Markers for now -- we cover them in an upcoming article.
Compile your operator
To compile the code, run the following command in the terminal from your project root:
make install
Set the operator namespace
Now you need to update your config to tell your operator to run in your own project namespace. Do this by issuing the following kustomize commands:
export IMG=docker.io/<username>/memcached-operator:<version>
export NAMESPACE=<oc-project-name>
cd config/manager
kustomize edit set image controller=${IMG}
kustomize edit set namespace "${NAMESPACE}"
cd ../../
cd config/default
kustomize edit set namespace "${NAMESPACE}"
cd ../../
<username> is your Docker Hub (or Quay.io) username, and <version> is the
version of the operator image you will deploy. Note that each time you
make a change to your operator code, it is good practice to increment the
version. NAMESPACE is the oc project name where you plan to deploy your operator. For us, this is memcache-demo-project.
For example, our export statements would look like the following:
export IMG=docker.io/horeaporutiu/memcached-operator:latest
export NAMESPACE=memcache-demo-project
Build and push your image
Note: You will need to have an account for an image repository like Docker Hub to be able to push your operator image. Use Docker login to log in.
To build the Docker image, run the following command. Note that you can also use the regular
docker build -tcommand to build as well.make docker-build IMG=$IMGPush the Docker image to your registry using the following from your terminal:
make docker-push IMG=$IMG
Step 6: Deploy the operator to your OpenShift cluster
To deploy the operator, run the following command from your terminal:
make deploy IMG=$IMGThe output of the deployment should look like the following:
...go-workspace/src/memcached-operator/bin/controller-gen "crd:trivialVersions=true,preserveUnknownFields=false" rbac:roleName=manager-role webhook paths="./..." output:crd:artifacts:config=config/crd/bases cd config/manager && ...go-workspace/src/memcached-operator/bin/kustomize edit set image controller=sanjeevghimire/memcached-operator:v0.0.5 .../go-workspace/src/memcached-operator/bin/kustomize build config/default | kubectl apply -f - Warning: kubectl apply should be used on resource created by either kubectl create --save-config or kubectl apply namespace/sanjeev-operator-prj configured customresourcedefinition.apiextensions.k8s.io/memcacheds.cache.example.com configured role.rbac.authorization.k8s.io/memcached-operator-leader-election-role created clusterrole.rbac.authorization.k8s.io/memcached-operator-manager-role configured clusterrole.rbac.authorization.k8s.io/memcached-operator-metrics-reader unchanged clusterrole.rbac.authorization.k8s.io/memcached-operator-proxy-role unchanged rolebinding.rbac.authorization.k8s.io/memcached-operator-leader-election-rolebinding created clusterrolebinding.rbac.authorization.k8s.io/memcached-operator-manager-rolebinding configured clusterrolebinding.rbac.authorization.k8s.io/memcached-operator-proxy-rolebinding configured configmap/memcached-operator-manager-config created service/memcached-operator-controller-manager-metrics-service created deployment.apps/memcached-operator-controller-manager createdTo make sure everything is working correctly, use the
oc get podscommand:$ oc get pods NAME READY STATUS RESTARTS AGE memcached-operator-controller-manager-54c5864f7b-znwws 2/2 Running 0 14sThis means your operator is up and running. Great job!
Step 7: Create the custom resource
Next, let's create the custom resource.
Update your custom resource by modifying the
config/samples/cache_v1alpha1_memcached.yamlfile to look like the following:apiVersion: cache.example.com/v1alpha1 kind: Memcached metadata: name: memcached-sample spec: # Add fields here size: 3Note the only change was to set the size of the Memcached replicas to be 3.
Finally, create the custom resources using the following command:
kubectl apply -f config/samples/cache_v1alpha1_memcached.yaml
Verify that resources are running
From the terminal, run
kubectl get alloroc get allto make sure that the controllers, managers, and pods have been successfully created and are inRunningstate with the right number of pods as defined in the spec:kubectl get allHere's what the output should look like:

From your cluster, you can see the logs by going to your project in the OpenShift web console:
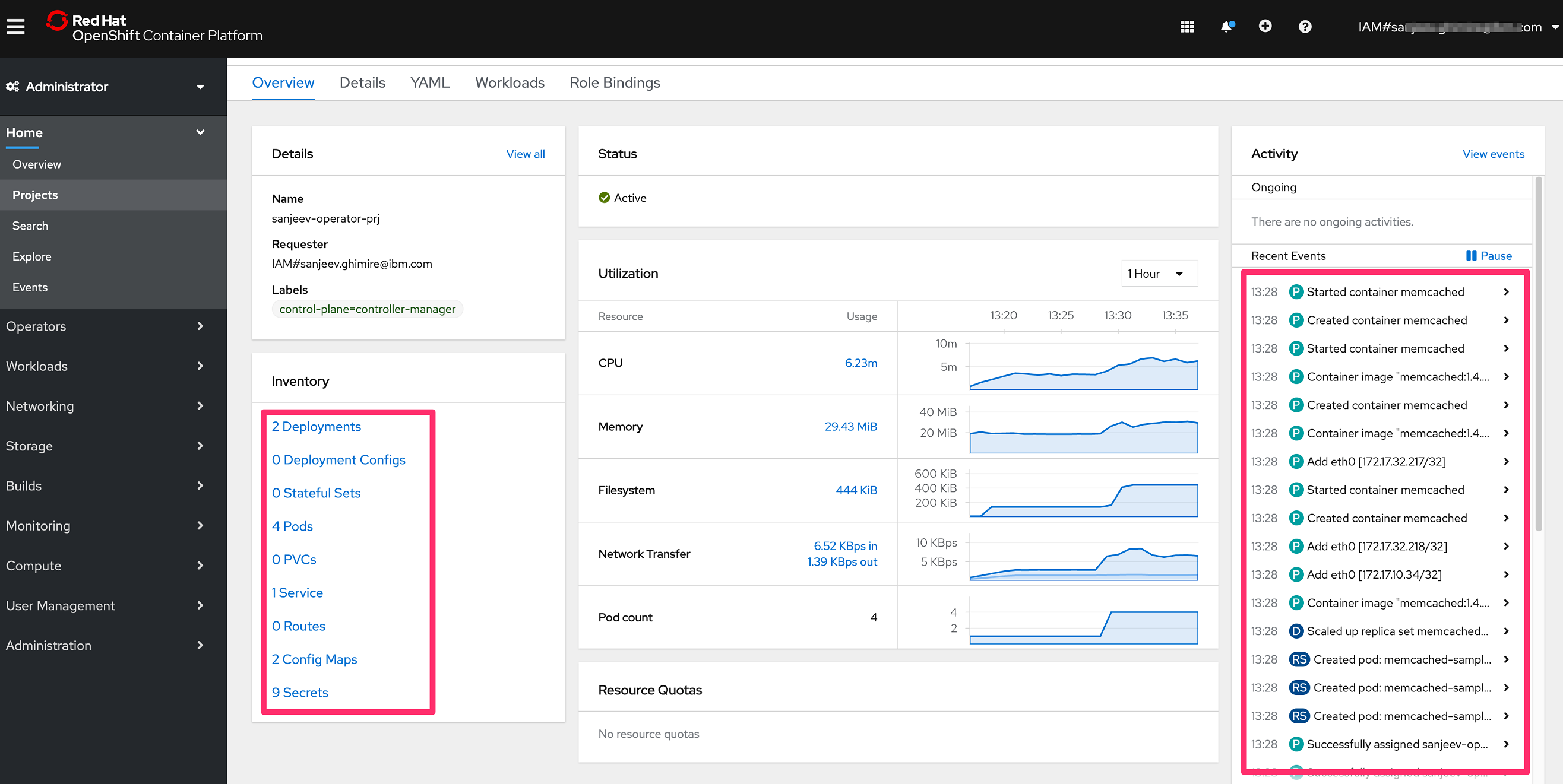
You can also now run
oc api-resourcesto view thememcacheresource you created:$ oc api-resources NAME APIGROUP NAMESPACED KIND memcacheds cache.example.com true MemcachedIf you want to make code changes in the controller and build and deploy a new version of your operator, you can simply use the
build-and-deploy.shscript. Just make sure to set your namespace and img in that file.Run the script by issuing the following command:
./build-and-deploy.sh
Step 8: Test and verify
Update
config/samples/<group>_<version>_memcached.yamlto change thespec.sizefield in the Memcached CR. This increases the application pods from 3 to 5. It can also be patched directly in the cluster as follows:oc patch memcached memcached-sample -p '{"spec":{"size": 5}}' --type=mergeYou can also update the spec.size from your OpenShift web console by going to
Deploymentsand selectingmemcached-sample. Increase or decrease the spec.size using the up or down arrow:
Next, verify that your pods have scaled up. Run the following command:
kubectl get podsYou should now see that there are 5 total
memcached-samplepods.
Congratulations! You've successfully deployed a Memcached operator using the operator-sdk!
To learn more about exactly what the code in Step 4 does, read the Deep dive into Memcached Operator Code tutorial, which explains the controller logic in more depth.
Cleanup
The Makefile part of the generated project has a target called undeploy, which deletes all the resources associated with your project. It can be run as follows:
make undeploy